 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape-Aware Whole-Body Control for Continuum Robots with Application in Endoluminal Surgical Robotics
Oct 14, 2025This paper presents a shape-aware whole-body control framework for tendon-driven continuum robots with direct application to endoluminal surgical navigation. Endoluminal procedures, such as bronchoscopy, demand precise and safe navigation through tortuous, patient-specific anatomy where conventional tip-only control often leads to wall contact, tissue trauma, or failure to reach distal targets. To address these challenges, our approach combines a physics-informed backbone model with residual learning through an Augmented Neural ODE, enabling accurate shape estimation and efficient Jacobian computation. A sampling-based Model Predictive Path Integral (MPPI) controller leverages this representation to jointly optimize tip tracking, backbone conformance, and obstacle avoidance under actuation constraints. A task manager further enhances adaptability by allowing real-time adjustment of objectives, such as wall clearance or direct advancement, during tele-operation. Extensive simulation studies demonstrate millimeter-level accuracy across diverse scenarios, including trajectory tracking, dynamic obstacle avoidance, and shape-constrained reaching. Real-robot experiments on a bronchoscopy phantom validate the framework, showing improved lumen-following accuracy, reduced wall contacts, and enhanced adaptability compared to joystick-only navigation and existing baselines. These results highlight the potential of the proposed framework to increase safety, reliability, and operator efficiency in minimally invasive endoluminal surgery, with broader applicability to other confined and safety-critical environments.
A Synergistic Framework for Learning Shape Estimation and Shape-Aware Whole-Body Control Policy for Continuum Robots
Jan 07, 2025



In this paper, we present a novel synergistic framework for learning shape estimation and a shape-aware whole-body control policy for tendon-driven continuum robots. Our approach leverages the interaction between two Augmented Neural Ordinary Differential Equations (ANODEs) -- the Shape-NODE and Control-NODE -- to achieve continuous shape estimation and shape-aware control. The Shape-NODE integrates prior knowledge from Cosserat rod theory, allowing it to adapt and account for model mismatches, while the Control-NODE uses this shape information to optimize a whole-body control policy, trained in a Model Predictive Control (MPC) fashion. This unified framework effectively overcomes limitations of existing data-driven methods, such as poor shape awareness and challenges in capturing complex nonlinear dynamics. Extensive evaluations in both simulation and real-world environments demonstrate the framework's robust performance in shape estimation, trajectory tracking, and obstacle avoidance. The proposed method consistently outperforms state-of-the-art end-to-end, Neural-ODE, and Recurrent Neural Network (RNN) models, particularly in terms of tracking accuracy and generalization capabilities.
VITAL: Visual Teleoperation to Enhance Robot Learning through Human-in-the-Loop Corrections
Jul 30, 2024
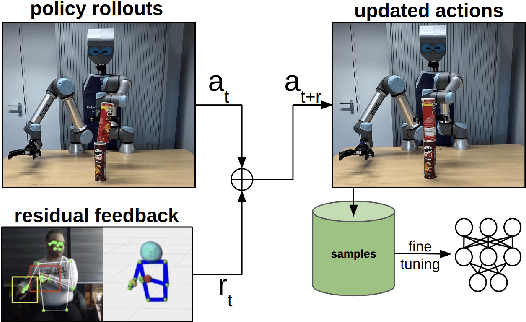
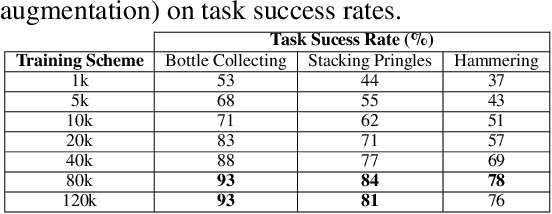
Imitation Learning (IL) has emerged as a powerful approach in robotics, allowing robots to acquire new skills by mimicking human actions. Despite its potential, the data collection process for IL remains a significant challenge due to the logistical difficulties and high costs associated with obtaining high-quality demonstrations. To address these issues, we propose a low-cost visual teleoperation system for bimanual manipulation tasks, called VITAL. Our approach leverages affordable hardware and visual processing techniques to collect demonstrations, which are then augmented to create extensive training datasets for imitation learning. We enhance the generalizability and robustness of the learned policies by utilizing both real and simulated environments and human-in-the-loop corrections. We evaluated our method through several rounds of experiments in simulated and real-robot settings, focusing on tasks of varying complexity, including bottle collecting, stacking objects, and hammering. Our experimental results validate the effectiveness of our approach in learning robust robot policies from simulated data, significantly improved by human-in-the-loop corrections and real-world data integration. Additionally, we demonstrate the framework's capability to generalize to new tasks, such as setting a drink tray, showcasing its adaptability and potential for handling a wide range of real-world bimanual manipulation tasks. A video of the experiments can be found at: https://youtu.be/YeVAMRqRe64?si=R179xDlEGc7nPu8i
Harnessing the Synergy between Pushing, Grasping, and Throwing to Enhance Object Manipulation in Cluttered Scenarios
Feb 25, 2024



In this work, we delve into the intricate synergy among non-prehensile actions like pushing, and prehensile actions such as grasping and throwing, within the domain of robotic manipulation. We introduce an innovative approach to learning these synergies by leveraging model-free deep reinforcement learning. The robot's workflow involves detecting the pose of the target object and the basket at each time step, predicting the optimal push configuration to isolate the target object, determining the appropriate grasp configuration, and inferring the necessary parameters for an accurate throw into the basket. This empowers robots to skillfully reconfigure cluttered scenarios through pushing, creating space for collision-free grasping actions. Simultaneously, we integrate throwing behavior, showcasing how this action significantly extends the robot's operational reach. Ensuring safety, we developed a simulation environment in Gazebo for robot training, applying the learned policy directly to our real robot. Notably, this work represents a pioneering effort to learn the synergy between pushing, grasping, and throwing actions. Extensive experimentation in both simulated and real-robot scenarios substantiates the effectiveness of our approach across diverse settings. Our approach achieves a success rate exceeding 80\% in both simulated and real-world scenarios. A video showcasing our experiments is available online at: https://youtu.be/q1l4BJVDbRw
Language-guided Robot Grasping: CLIP-based Referring Grasp Synthesis in Clutter
Nov 09, 2023
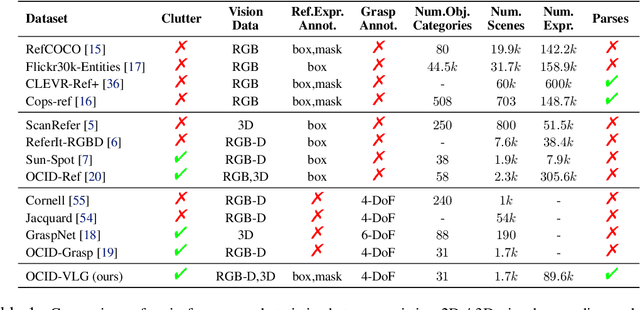
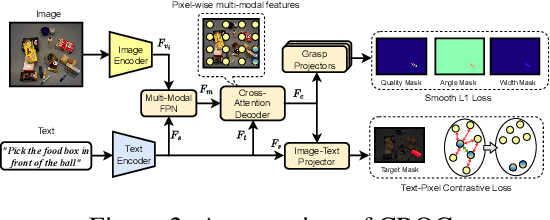
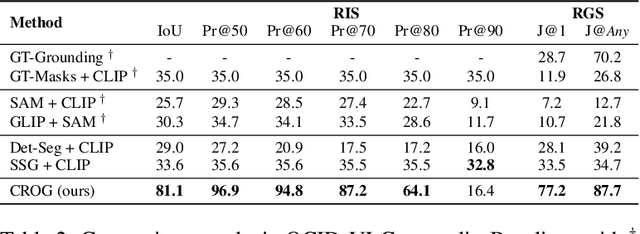
Robots operating in human-centric environments require the integration of visual grounding and grasping capabilities to effectively manipulate objects based on user instructions. This work focuses on the task of referring grasp synthesis, which predicts a grasp pose for an object referred through natural language in cluttered scenes. Existing approaches often employ multi-stage pipelines that first segment the referred object and then propose a suitable grasp, and are evaluated in private datasets or simulators that do not capture the complexity of natural indoor scenes. To address these limitations, we develop a challenging benchmark based on cluttered indoor scenes from OCID dataset, for which we generate referring expressions and connect them with 4-DoF grasp poses. Further, we propose a novel end-to-end model (CROG) that leverages the visual grounding capabilities of CLIP to learn grasp synthesis directly from image-text pairs. Our results show that vanilla integration of CLIP with pretrained models transfers poorly in our challenging benchmark, while CROG achieves significant improvements both in terms of grounding and grasping. Extensive robot experiments in both simulation and hardware demonstrate the effectiveness of our approach in challenging interactive object grasping scenarios that include clutter.
Learning Fine Pinch-Grasp Skills using Tactile Sensing from Real Demonstration Data
Jul 10, 2023
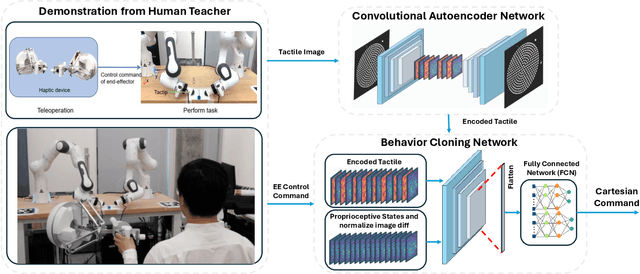


This work develops a data-efficient learning from demonstration framework which exploits the use of rich tactile sensing and achieves fine dexterous bimanual manipulation. Specifically, we formulated a convolutional autoencoder network that can effectively extract and encode high-dimensional tactile information. Further, we developed a behaviour cloning network that can learn human-like sensorimotor skills demonstrated directly on the robot hardware in the task space by fusing both proprioceptive and tactile feedback. Our comparison study with the baseline method revealed the effectiveness of the contact information, which enabled successful extraction and replication of the demonstrated motor skills. Extensive experiments on real dual-arm robots demonstrated the robustness and effectiveness of the fine pinch grasp policy directly learned from one-shot demonstration, including grasping of the same object with different initial poses, generalizing to ten unseen new objects, robust and firm grasping against external pushes, as well as contact-aware and reactive re-grasping in case of dropping objects under very large perturbations. Moreover, the saliency map method is employed to describe the weight distribution across various modalities during pinch grasping. The video is available online at: \href{https://youtu.be/4Pg29bUBKqs}{https://youtu.be/4Pg29bUBKqs}.
Instance-wise Grasp Synthesis for Robotic Grasping
Feb 15, 2023Generating high-quality instance-wise grasp configurations provides critical information of how to grasp specific objects in a multi-object environment and is of high importance for robot manipulation tasks. This work proposed a novel \textbf{S}ingle-\textbf{S}tage \textbf{G}rasp (SSG) synthesis network, which performs high-quality instance-wise grasp synthesis in a single stage: instance mask and grasp configurations are generated for each object simultaneously. Our method outperforms state-of-the-art on robotic grasp prediction based on the OCID-Grasp dataset, and performs competitively on the JACQUARD dataset. The benchmarking results showed significant improvements compared to the baseline on the accuracy of generated grasp configurations. The performance of the proposed method has been validated through both extensive simulations and real robot experiments for three tasks including single object pick-and-place, grasp synthesis in cluttered environments and table cleaning task.
Agile and Versatile Robot Locomotion via Kernel-based Residual Learning
Feb 14, 2023



This work developed a kernel-based residual learning framework for quadrupedal robotic locomotion. Initially, a kernel neural network is trained with data collected from an MPC controller. Alongside a frozen kernel network, a residual controller network is trained via reinforcement learning to acquire generalized locomotion skills and resilience against external perturbations. With this proposed framework, a robust quadrupedal locomotion controller is learned with high sample efficiency and controllability, providing omnidirectional locomotion at continuous velocities. Its versatility and robustness are validated on unseen terrains that the expert MPC controller fails to traverse. Furthermore, the learned kernel can produce a range of functional locomotion behaviors and can generalize to unseen gaits.
Throwing Objects into A Moving Basket While Avoiding Obstacles
Oct 02, 2022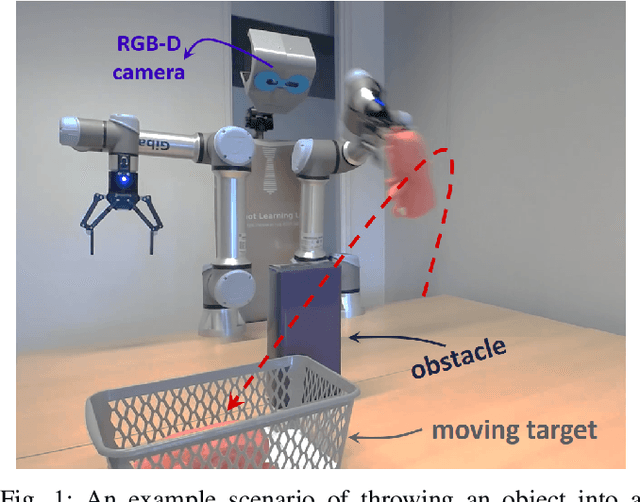

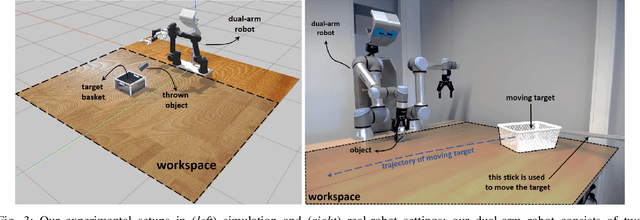

The capabilities of a robot will be increased significantly by exploiting throwing behavior. In particular, throwing will enable robots to rapidly place the object into the target basket, located outside its feasible kinematic space, without traveling to the desired location. In previous approaches, the robot often learned a parameterized throwing kernel through analytical approaches, imitation learning, or hand-coding. There are many situations in which such approaches do not work/generalize well due to various object shapes, heterogeneous mass distribution, and also obstacles that might be presented in the environment. It is obvious that a method is needed to modulate the throwing kernel through its meta parameters. In this paper, we tackle object throwing problem through a deep reinforcement learning approach that enables robots to precisely throw objects into moving baskets while there are obstacles obstructing the path. To the best of our knowledge, we are the first group that addresses throwing objects with obstacle avoidance. Such a throwing skill not only increases the physical reachability of a robot arm but also improves the execution time. In particular, the robot detects the pose of the target object, basket, and obstacle at each time step, predicts the proper grasp configuration for the target object, and then infers appropriate parameters to throw the object into the basket. Due to safety constraints, we develop a simulation environment in Gazebo to train the robot and then use the learned policy in real-robot directly. To assess the performers of the proposed approach, we perform extensive sets of experiments in both simulation and real robots in three scenarios. Experimental results showed that the robot could precisely throw a target object into the basket outside its kinematic range and generalize well to new locations and objects without colliding with obstacles.
Simultaneous Multi-View Object Recognition and Grasping in Open-Ended Domains
Jun 03, 2021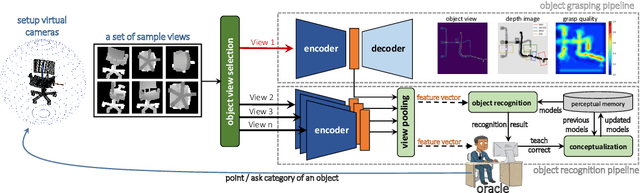
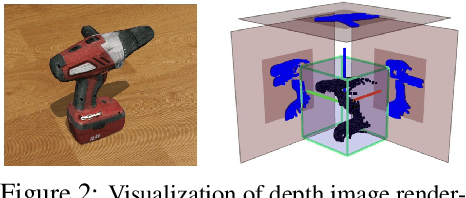
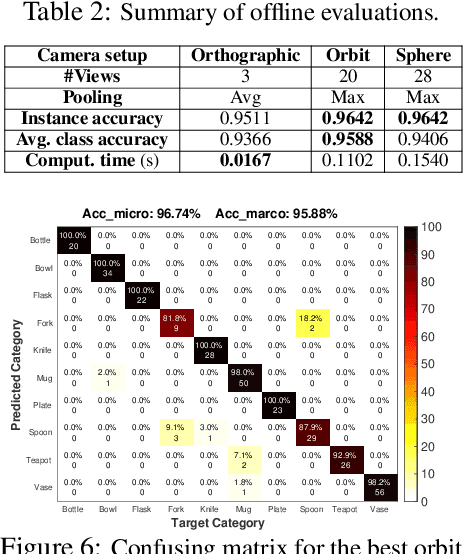
A robot working in human-centric environments needs to know which kind of objects exist in the scene, where they are, and how to grasp and manipulate various objects in different situations to help humans in everyday tasks. Therefore, object recognition and grasping are two key functionalities for such robots. Most state-of-the-art tackles object recognition and grasping as two separate problems while both use visual input. Furthermore, the knowledge of the robot is fixed after the training phase. In such cases, if the robot faces new object categories, it must retrain from scratch to incorporate new information without catastrophic interference. To address this problem, we propose a deep learning architecture with augmented memory capacities to handle open-ended object recognition and grasping simultaneously. In particular, our approach takes multi-views of an object as input and jointly estimates pixel-wise grasp configuration as well as a deep scale- and rotation-invariant representation as outputs. The obtained representation is then used for open-ended object recognition through a meta-active learning technique. We demonstrate the ability of our approach to grasp never-seen-before objects and to rapidly learn new object categories using very few examples on-site in both simulation and real-world settings.