 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models as World Models: A Foundational Study in Text-Based GridWorlds
Sep 19, 2025



While reinforcement learning from scratch has shown impressive results in solving sequential decision-making tasks with efficient simulators, real-world applications with expensive interactions require more sample-efficient agents. Foundation models (FMs) are natural candidates to improve sample efficiency as they possess broad knowledge and reasoning capabilities, but it is yet unclear how to effectively integrate them into the reinforcement learning framework. In this paper, we anticipate and, most importantly, evaluate two promising strategies. First, we consider the use of foundation world models (FWMs) that exploit the prior knowledge of FMs to enable training and evaluating agents with simulated interactions. Second, we consider the use of foundation agents (FAs) that exploit the reasoning capabilities of FMs for decision-making. We evaluate both approaches empirically in a family of grid-world environments that are suitable for the current generation of large language models (LLMs). Our results suggest that improvements in LLMs already translate into better FWMs and FAs; that FAs based on current LLMs can already provide excellent policies for sufficiently simple environments; and that the coupling of FWMs and reinforcement learning agents is highly promising for more complex settings with partial observability and stochastic elements.
VDSC: Enhancing Exploration Timing with Value Discrepancy and State Counts
Mar 26, 2024



Despite the considerable attention given to the questions of \textit{how much} and \textit{how to} explore in deep reinforcement learning, the investigation into \textit{when} to explore remains relatively less researched. While more sophisticated exploration strategies can excel in specific, often sparse reward environments, existing simpler approaches, such as $\epsilon$-greedy, persist in outperforming them across a broader spectrum of domains. The appeal of these simpler strategies lies in their ease of implementation and generality across a wide range of domains. The downside is that these methods are essentially a blind switching mechanism, which completely disregards the agent's internal state. In this paper, we propose to leverage the agent's internal state to decide \textit{when} to explore, addressing the shortcomings of blind switching mechanisms. We present Value Discrepancy and State Counts through homeostasis (VDSC), a novel approach for efficient exploration timing. Experimental results on the Atari suite demonstrate the superiority of our strategy over traditional methods such as $\epsilon$-greedy and Boltzmann, as well as more sophisticated techniques like Noisy Nets.
Posterior Sampling for Deep Reinforcement Learning
Apr 30, 2023Despite remarkable successes, deep reinforcement learning algorithms remain sample inefficient: they require an enormous amount of trial and error to find good policies. Model-based algorithms promise sample efficiency by building an environment model that can be used for planning. Posterior Sampling for Reinforcement Learning is such a model-based algorithm that has attracted significant interest due to its performance in the tabular setting. This paper introduces Posterior Sampling for Deep Reinforcement Learning (PSDRL), the first truly scalable approximation of Posterior Sampling for Reinforcement Learning that retains its model-based essence. PSDRL combines efficient uncertainty quantification over latent state space models with a specially tailored continual planning algorithm based on value-function approximation. Extensive experiments on the Atari benchmark show that PSDRL significantly outperforms previous state-of-the-art attempts at scaling up posterior sampling while being competitive with a state-of-the-art (model-based) reinforcement learning method, both in sample efficiency and computational efficiency.
Multi-Source Transfer Learning for Deep Model-Based Reinforcement Learning
May 28, 2022
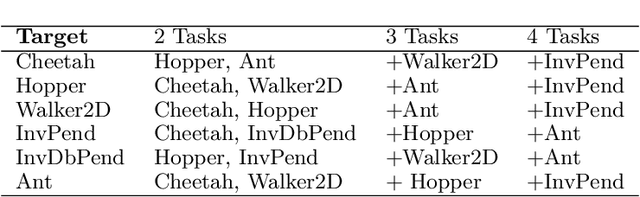
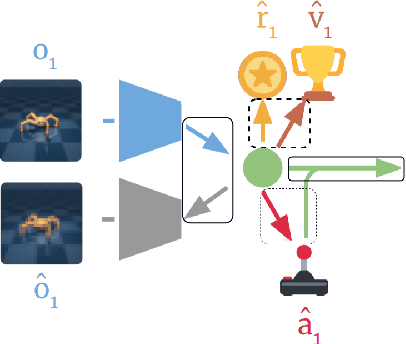
Recent progress in deep model-based reinforcement learning allows agents to be significantly more sample efficient by constructing world models of high-dimensional environments from visual observations, which enables agents to learn complex behaviours in summarized lower-dimensional spaces. Reusing knowledge from relevant previous tasks is another approach for achieving better data-efficiency, which becomes especially more likely when information of multiple previously learned tasks is accessible. We show that the simplified representations of environments resulting from world models provide for promising transfer learning opportunities, by introducing several methods that facilitate world model agents to benefit from multi-source transfer learning. Methods are proposed for autonomously extracting relevant knowledge from both multi-task and multi-agent settings as multi-source origins, resulting in substantial performance improvements compared to learning from scratch. We introduce two additional novel techniques that enable and enhance the proposed approaches respectively: fractional transfer learning and universal feature spaces from a universal autoencoder. We demonstrate that our methods enable transfer learning from different domains with different state, reward, and action spaces by performing extensive and challenging multi-domain experiments on Dreamer, the state-of-the-art world model based algorithm for visual continuous control tasks.
Fractional Transfer Learning for Deep Model-Based Reinforcement Learning
Aug 14, 2021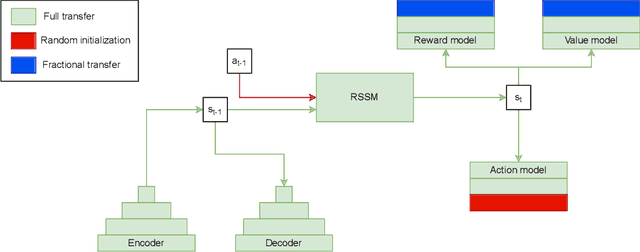
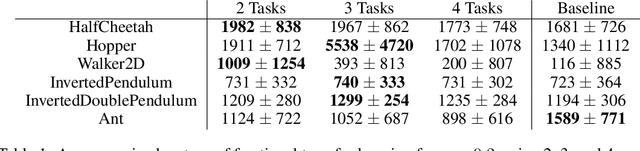

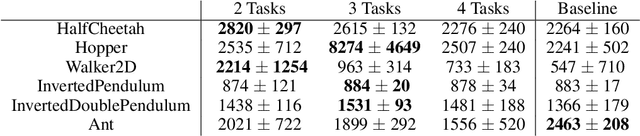
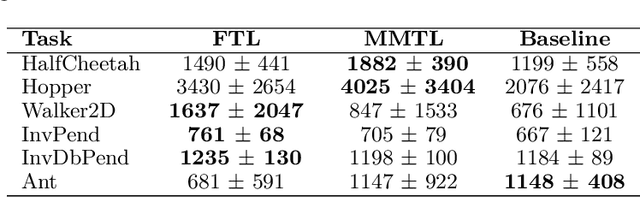
Reinforcement learning (RL) is well known for requiring large amounts of data in order for RL agents to learn to perform complex tasks. Recent progress in model-based RL allows agents to be much more data-efficient, as it enables them to learn behaviors of visual environments in imagination by leveraging an internal World Model of the environment. Improved sample efficiency can also be achieved by reusing knowledge from previously learned tasks, but transfer learning is still a challenging topic in RL. Parameter-based transfer learning is generally done using an all-or-nothing approach, where the network's parameters are either fully transferred or randomly initialized. In this work we present a simple alternative approach: fractional transfer learning. The idea is to transfer fractions of knowledge, opposed to discarding potentially useful knowledge as is commonly done with random initialization. Using the World Model-based Dreamer algorithm, we identify which type of components this approach is applicable to, and perform experiments in a new multi-source transfer learning setting. The results show that fractional transfer learning often leads to substantially improved performance and faster learning compared to learning from scratch and random initialization.
Simultaneous Multi-View Object Recognition and Grasping in Open-Ended Domains
Jun 03, 2021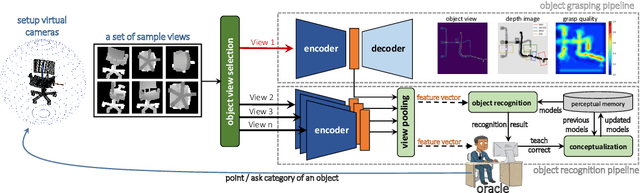
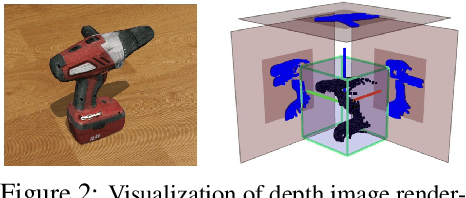
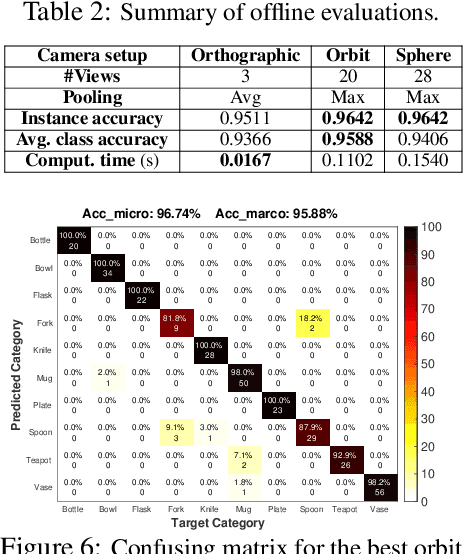
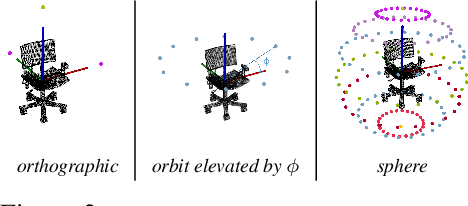
A robot working in human-centric environments needs to know which kind of objects exist in the scene, where they are, and how to grasp and manipulate various objects in different situations to help humans in everyday tasks. Therefore, object recognition and grasping are two key functionalities for such robots. Most state-of-the-art tackles object recognition and grasping as two separate problems while both use visual input. Furthermore, the knowledge of the robot is fixed after the training phase. In such cases, if the robot faces new object categories, it must retrain from scratch to incorporate new information without catastrophic interference. To address this problem, we propose a deep learning architecture with augmented memory capacities to handle open-ended object recognition and grasping simultaneously. In particular, our approach takes multi-views of an object as input and jointly estimates pixel-wise grasp configuration as well as a deep scale- and rotation-invariant representation as outputs. The obtained representation is then used for open-ended object recognition through a meta-active learning technique. We demonstrate the ability of our approach to grasp never-seen-before objects and to rapidly learn new object categories using very few examples on-site in both simulation and real-world settings.