 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Transfer Learning for Deep Model-Based Reinforcement Learning
May 28, 2022
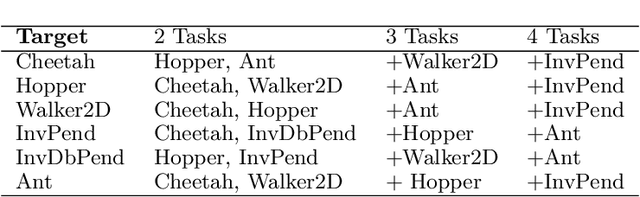
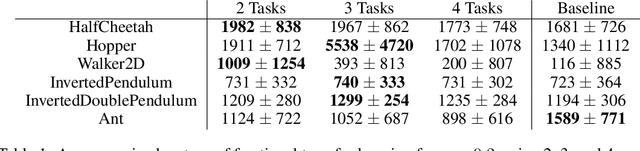
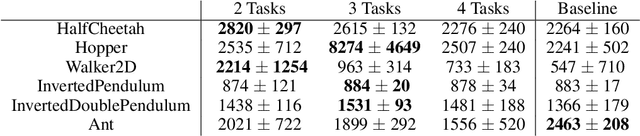
Recent progress in deep model-based reinforcement learning allows agents to be significantly more sample efficient by constructing world models of high-dimensional environments from visual observations, which enables agents to learn complex behaviours in summarized lower-dimensional spaces. Reusing knowledge from relevant previous tasks is another approach for achieving better data-efficiency, which becomes especially more likely when information of multiple previously learned tasks is accessible. We show that the simplified representations of environments resulting from world models provide for promising transfer learning opportunities, by introducing several methods that facilitate world model agents to benefit from multi-source transfer learning. Methods are proposed for autonomously extracting relevant knowledge from both multi-task and multi-agent settings as multi-source origins, resulting in substantial performance improvements compared to learning from scratch. We introduce two additional novel techniques that enable and enhance the proposed approaches respectively: fractional transfer learning and universal feature spaces from a universal autoencoder. We demonstrate that our methods enable transfer learning from different domains with different state, reward, and action spaces by performing extensive and challenging multi-domain experiments on Dreamer, the state-of-the-art world model based algorithm for visual continuous control tasks.
Fractional Transfer Learning for Deep Model-Based Reinforcement Learning
Aug 14, 2021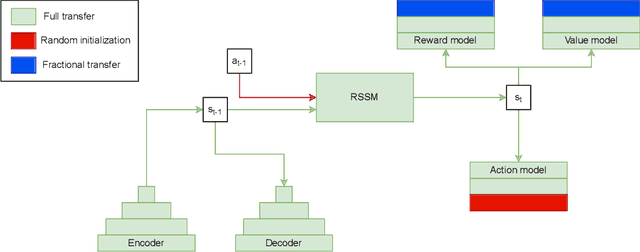

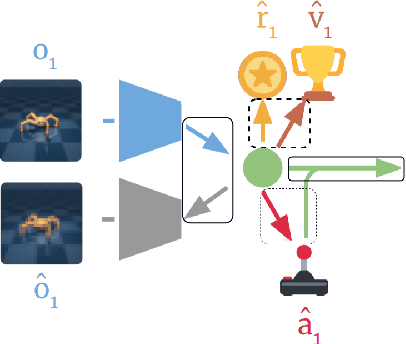
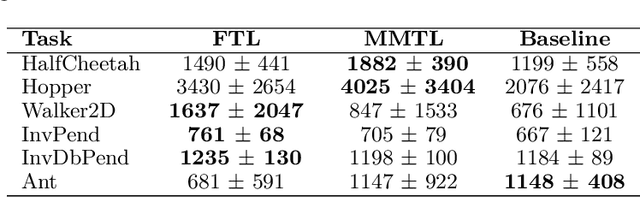
Reinforcement learning (RL) is well known for requiring large amounts of data in order for RL agents to learn to perform complex tasks. Recent progress in model-based RL allows agents to be much more data-efficient, as it enables them to learn behaviors of visual environments in imagination by leveraging an internal World Model of the environment. Improved sample efficiency can also be achieved by reusing knowledge from previously learned tasks, but transfer learning is still a challenging topic in RL. Parameter-based transfer learning is generally done using an all-or-nothing approach, where the network's parameters are either fully transferred or randomly initialized. In this work we present a simple alternative approach: fractional transfer learning. The idea is to transfer fractions of knowledge, opposed to discarding potentially useful knowledge as is commonly done with random initialization. Using the World Model-based Dreamer algorithm, we identify which type of components this approach is applicable to, and perform experiments in a new multi-source transfer learning setting. The results show that fractional transfer learning often leads to substantially improved performance and faster learning compared to learning from scratch and random initialization.
Enhancing reinforcement learning by a finite reward response filter with a case study in intelligent structural control
Oct 25, 2020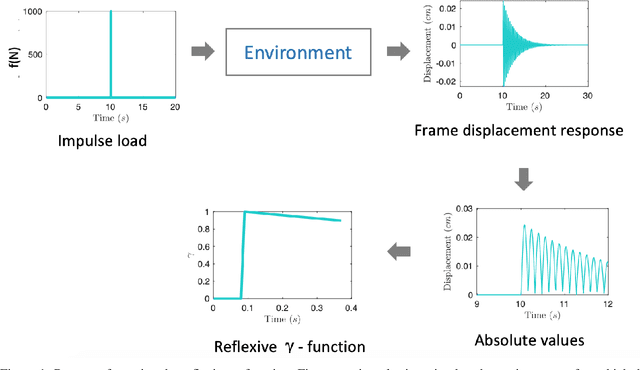

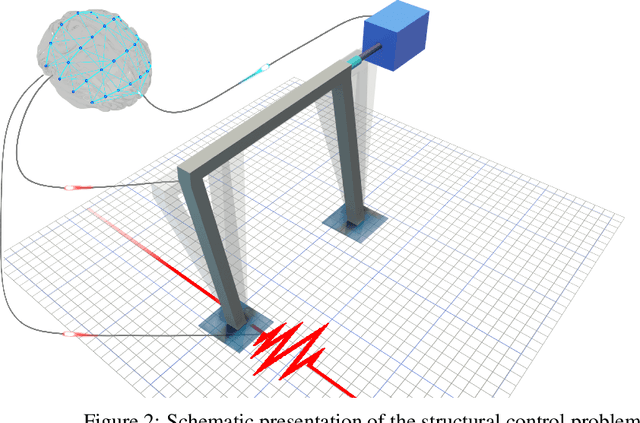
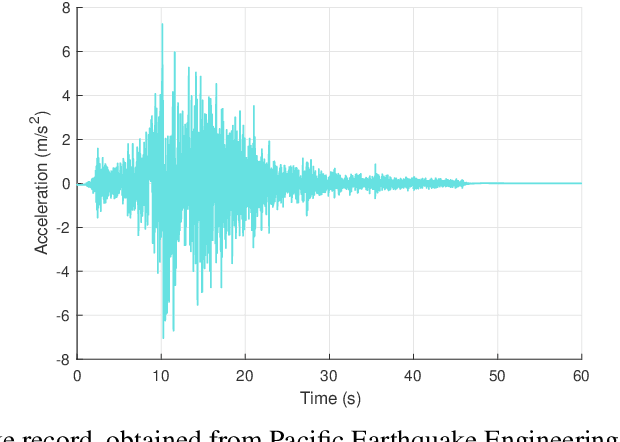
In many reinforcement learning (RL) problems, it takes some time until a taken action by the agent reaches its maximum effect on the environment and consequently the agent receives the reward corresponding to that action by a delay called action-effect delay. Such delays reduce the performance of the learning algorithm and increase the computational costs, as the reinforcement learning agent values the immediate rewards more than the future reward that is more related to the taken action. This paper addresses this issue by introducing an applicable enhanced Q-learning method in which at the beginning of the learning phase, the agent takes a single action and builds a function that reflects the environments response to that action, called the reflexive $\gamma$ - function. During the training phase, the agent utilizes the created reflexive $\gamma$- function to update the Q-values. We have applied the developed method to a structural control problem in which the goal of the agent is to reduce the vibrations of a building subjected to earthquake excitations with a specified delay. Seismic control problems are considered as a complex task in structural engineering because of the stochastic and unpredictable nature of earthquakes and the complex behavior of the structure. Three scenarios are presented to study the effects of zero, medium, and long action-effect delays and the performance of the Enhanced method is compared to the standard Q-learning method. Both RL methods use neural network to learn to estimate the state-action value function that is used to control the structure. The results show that the enhanced method significantly outperforms the performance of the original method in all cases, and also improves the stability of the algorithm in dealing with action-effect delays.
Continuous-action Reinforcement Learning for Playing Racing Games: Comparing SPG to PPO
Jan 15, 2020
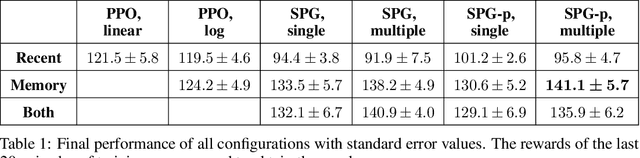

In this paper, a novel racing environment for OpenAI Gym is introduced. This environment operates with continuous action- and state-spaces and requires agents to learn to control the acceleration and steering of a car while navigating a randomly generated racetrack. Different versions of two actor-critic learning algorithms are tested on this environment: Sampled Policy Gradient (SPG) and Proximal Policy Optimization (PPO). An extension of SPG is introduced that aims to improve learning performance by weighting action samples during the policy update step. The effect of using experience replay (ER) is also investigated. To this end, a modification to PPO is introduced that allows for training using old action samples by optimizing the actor in log space. Finally, a new technique for performing ER is tested that aims to improve learning speed without sacrificing performance by splitting the training into two parts, whereby networks are first trained using state transitions from the replay buffer, and then using only recent experiences. The results indicate that experience replay is not beneficial to PPO in continuous action spaces. The training of SPG seems to be more stable when actions are weighted. All versions of SPG outperform PPO when ER is used. The ER trick is effective at improving training speed on a computationally less intensive version of SPG.
Approximating two value functions instead of one: towards characterizing a new family of Deep Reinforcement Learning algorithms
Sep 01, 2019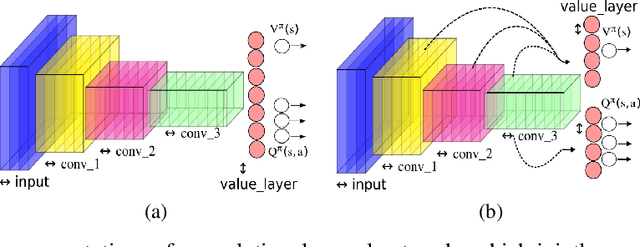
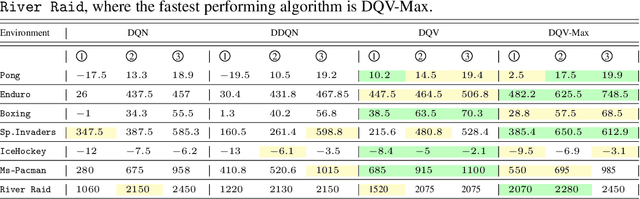
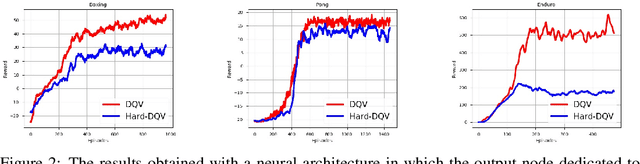
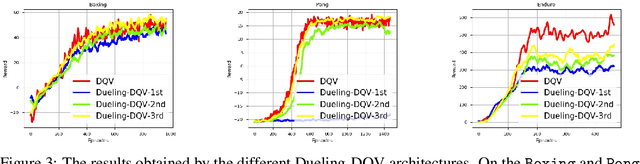
This paper makes one step forward towards characterizing a new family of \textit{model-free} Deep Reinforcement Learning (DRL) algorithms. The aim of these algorithms is to jointly learn an approximation of the state-value function ($V$), alongside an approximation of the state-action value function ($Q$). Our analysis starts with a thorough study of the Deep Quality-Value Learning (DQV) algorithm, a DRL algorithm which has been shown to outperform popular techniques such as Deep-Q-Learning (DQN) and Double-Deep-Q-Learning (DDQN) \cite{sabatelli2018deep}. Intending to investigate why DQV's learning dynamics allow this algorithm to perform so well, we formulate a set of research questions which help us characterize a new family of DRL algorithms. Among our results, we present some specific cases in which DQV's performance can get harmed and introduce a novel \textit{off-policy} DRL algorithm, called DQV-Max, which can outperform DQV. We then study the behavior of the $V$ and $Q$ functions that are learned by DQV and DQV-Max and show that both algorithms might perform so well on several DRL test-beds because they are less prone to suffer from the overestimation bias of the $Q$ function.
Deep Quality-Value (DQV) Learning
Oct 10, 2018
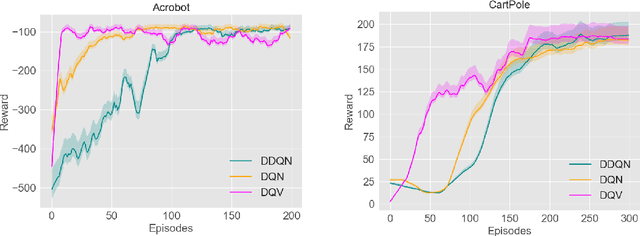
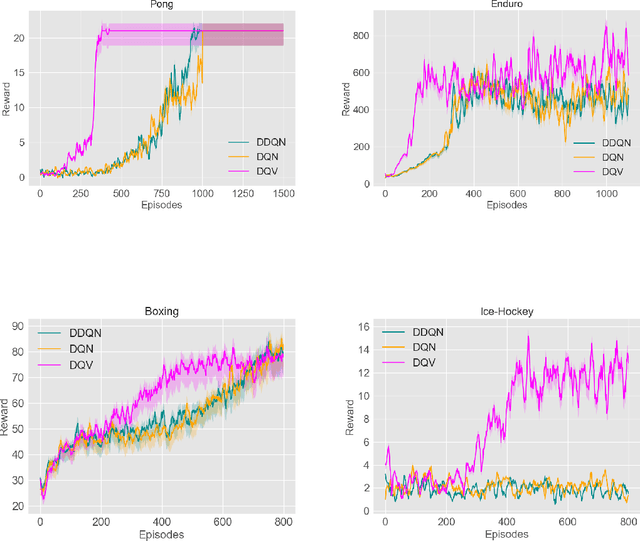
We introduce a novel Deep Reinforcement Learning (DRL) algorithm called Deep Quality-Value (DQV) Learning. DQV uses temporal-difference learning to train a Value neural network and uses this network for training a second Quality-value network that learns to estimate state-action values. We first test DQV's update rules with Multilayer Perceptrons as function approximators on two classic RL problems, and then extend DQV with the use of Deep Convolutional Neural Networks, `Experience Replay' and `Target Neural Networks' for tackling four games of the Atari Arcade Learning environment. Our results show that DQV learns significantly faster and better than Deep Q-Learning and Double Deep Q-Learning, suggesting that our algorithm can potentially be a better performing synchronous temporal difference algorithm than what is currently present in DRL.
Sampled Policy Gradient for Learning to Play the Game Agar.io
Sep 15, 2018

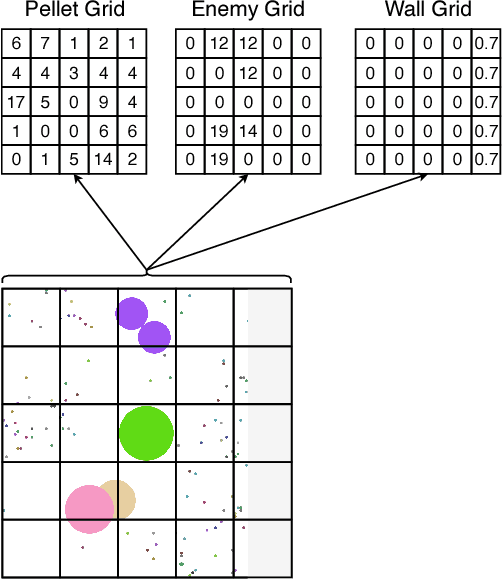
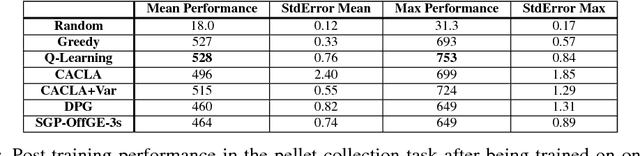
In this paper, a new offline actor-critic learning algorithm is introduced: Sampled Policy Gradient (SPG). SPG samples in the action space to calculate an approximated policy gradient by using the critic to evaluate the samples. This sampling allows SPG to search the action-Q-value space more globally than deterministic policy gradient (DPG), enabling it to theoretically avoid more local optima. SPG is compared to Q-learning and the actor-critic algorithms CACLA and DPG in a pellet collection task and a self play environment in the game Agar.io. The online game Agar.io has become massively popular on the internet due to intuitive game design and the ability to instantly compete against players around the world. From the point of view of artificial intelligence this game is also very intriguing: The game has a continuous input and action space and allows to have diverse agents with complex strategies compete against each other. The experimental results show that Q-Learning and CACLA outperform a pre-programmed greedy bot in the pellet collection task, but all algorithms fail to outperform this bot in a fighting scenario. The SPG algorithm is analyzed to have great extendability through offline exploration and it matches DPG in performance even in its basic form without extensive sampling.