 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing reinforcement learning by a finite reward response filter with a case study in intelligent structural control
Paper and Code
Oct 25, 2020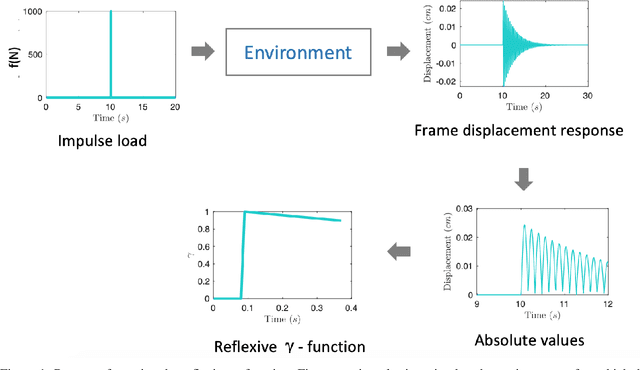

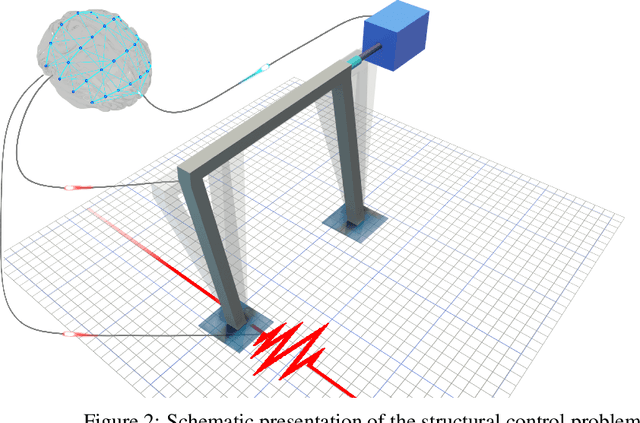
In many reinforcement learning (RL) problems, it takes some time until a taken action by the agent reaches its maximum effect on the environment and consequently the agent receives the reward corresponding to that action by a delay called action-effect delay. Such delays reduce the performance of the learning algorithm and increase the computational costs, as the reinforcement learning agent values the immediate rewards more than the future reward that is more related to the taken action. This paper addresses this issue by introducing an applicable enhanced Q-learning method in which at the beginning of the learning phase, the agent takes a single action and builds a function that reflects the environments response to that action, called the reflexive $\gamma$ - function. During the training phase, the agent utilizes the created reflexive $\gamma$- function to update the Q-values. We have applied the developed method to a structural control problem in which the goal of the agent is to reduce the vibrations of a building subjected to earthquake excitations with a specified delay. Seismic control problems are considered as a complex task in structural engineering because of the stochastic and unpredictable nature of earthquakes and the complex behavior of the structure. Three scenarios are presented to study the effects of zero, medium, and long action-effect delays and the performance of the Enhanced method is compared to the standard Q-learning method. Both RL methods use neural network to learn to estimate the state-action value function that is used to control the structure. The results show that the enhanced method significantly outperforms the performance of the original method in all cases, and also improves the stability of the algorithm in dealing with action-effect delays.