 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Quality-Value (DQV) Learning
Paper and Code

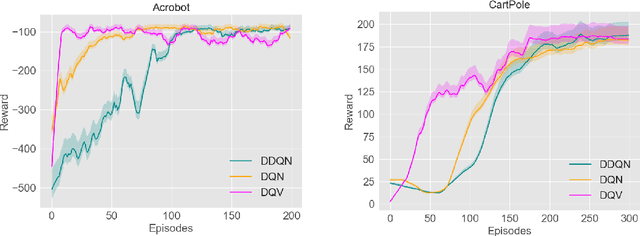
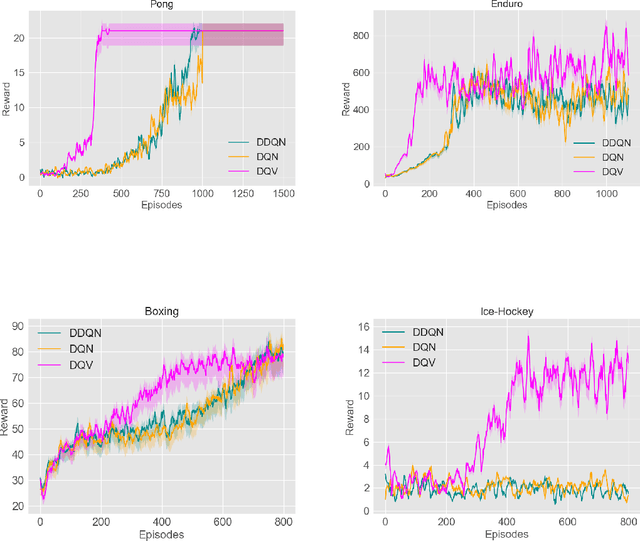
We introduce a novel Deep Reinforcement Learning (DRL) algorithm called Deep Quality-Value (DQV) Learning. DQV uses temporal-difference learning to train a Value neural network and uses this network for training a second Quality-value network that learns to estimate state-action values. We first test DQV's update rules with Multilayer Perceptrons as function approximators on two classic RL problems, and then extend DQV with the use of Deep Convolutional Neural Networks, `Experience Replay' and `Target Neural Networks' for tackling four games of the Atari Arcade Learning environment. Our results show that DQV learns significantly faster and better than Deep Q-Learning and Double Deep Q-Learning, suggesting that our algorithm can potentially be a better performing synchronous temporal difference algorithm than what is currently present in DRL.