 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelizing Autoregressive Generation with Variational State Space Models
Jul 11, 2024Attention-based models such as Transformers and recurrent models like state space models (SSMs) have emerged as successful methods for autoregressive sequence modeling. Although both enable parallel training, none enable parallel generation due to their autoregressiveness. We propose the variational SSM (VSSM), a variational autoencoder (VAE) where both the encoder and decoder are SSMs. Since sampling the latent variables and decoding them with the SSM can be parallelized, both training and generation can be conducted in parallel. Moreover, the decoder recurrence allows generation to be resumed without reprocessing the whole sequence. Finally, we propose the autoregressive VSSM that can be conditioned on a partial realization of the sequence, as is common in language generation tasks. Interestingly, the autoregressive VSSM still enables parallel generation. We highlight on toy problems (MNIST, CIFAR) the empirical gains in speed-up and show that it competes with traditional models in terms of generation quality (Transformer, Mamba SSM).
* 4 pages, 11 pages total, 3 figures
Knowledge-Guided Additive Modeling For Supervised Regression
Jul 05, 2023Learning processes by exploiting restricted domain knowledge is an important task across a plethora of scientific areas, with more and more hybrid methods combining data-driven and model-based approaches. However, while such hybrid methods have been tested in various scientific applications, they have been mostly tested on dynamical systems, with only limited study about the influence of each model component on global performance and parameter identification. In this work, we assess the performance of hybrid modeling against traditional machine learning methods on standard regression problems. We compare, on both synthetic and real regression problems, several approaches for training such hybrid models. We focus on hybrid methods that additively combine a parametric physical term with a machine learning term and investigate model-agnostic training procedures. We also introduce a new hybrid approach based on partial dependence functions. Experiments are carried out with different types of machine learning models, including tree-based models and artificial neural networks.
Distillation from heterogeneous unlabeled collections
Jan 17, 2022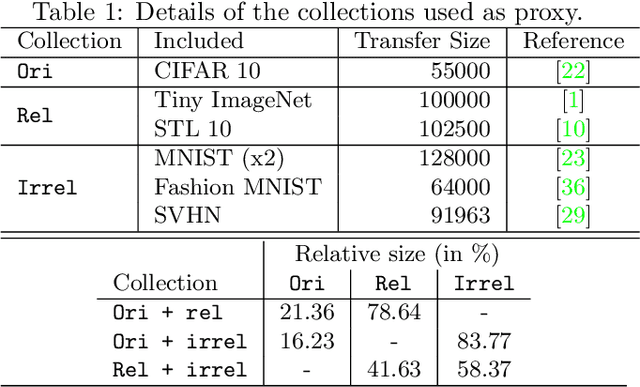
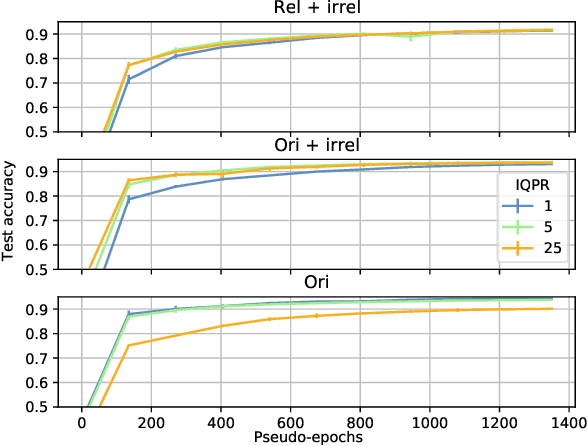

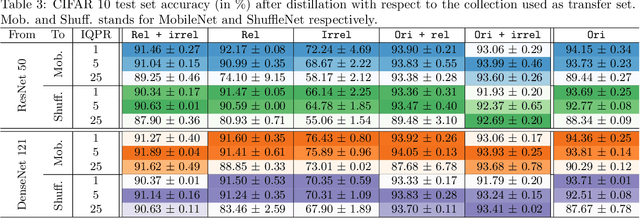
Compressing deep networks is essential to expand their range of applications to constrained settings. The need for compression however often arises long after the model was trained, when the original data might no longer be available. On the other hand, unlabeled data, not necessarily related to the target task, is usually plentiful, especially in image classification tasks. In this work, we propose a scheme to leverage such samples to distill the knowledge learned by a large teacher network to a smaller student. The proposed technique relies on (i) preferentially sampling datapoints that appear related, and (ii) taking better advantage of the learning signal. We show that the former speeds up the student's convergence, while the latter boosts its performance, achieving performances closed to what can be expected with the original data.
From global to local MDI variable importances for random forests and when they are Shapley values
Nov 03, 2021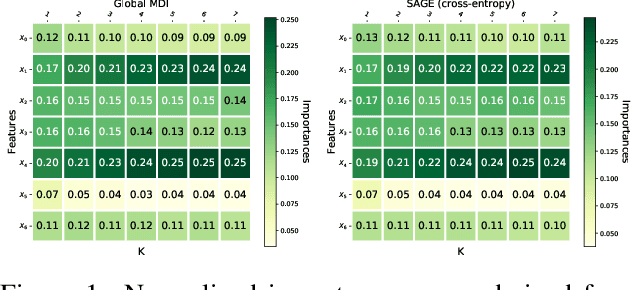
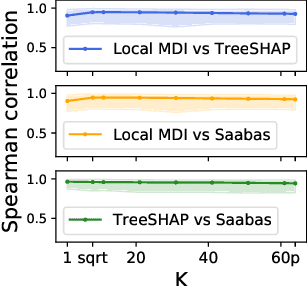

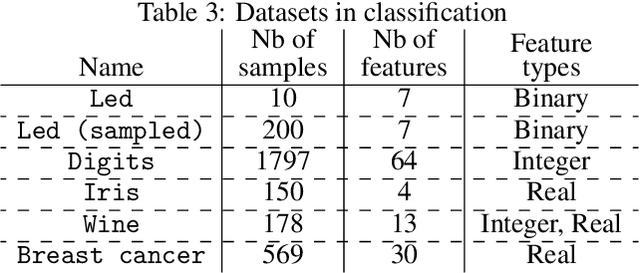
Random forests have been widely used for their ability to provide so-called importance measures, which give insight at a global (per dataset) level on the relevance of input variables to predict a certain output. On the other hand, methods based on Shapley values have been introduced to refine the analysis of feature relevance in tree-based models to a local (per instance) level. In this context, we first show that the global Mean Decrease of Impurity (MDI) variable importance scores correspond to Shapley values under some conditions. Then, we derive a local MDI importance measure of variable relevance, which has a very natural connection with the global MDI measure and can be related to a new notion of local feature relevance. We further link local MDI importances with Shapley values and discuss them in the light of related measures from the literature. The measures are illustrated through experiments on several classification and regression problems.
On The Transferability of Deep-Q Networks
Oct 06, 2021
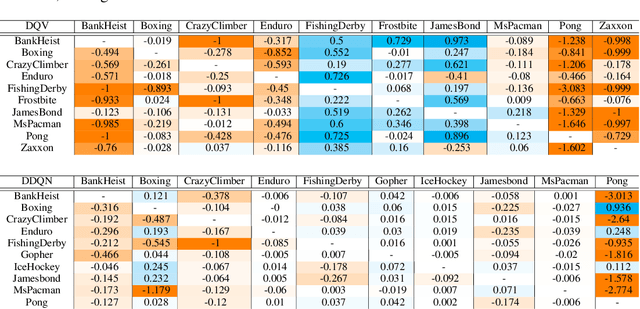

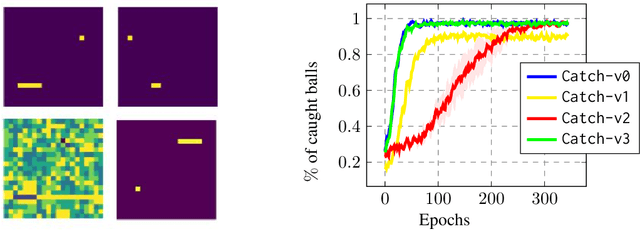
Transfer Learning (TL) is an efficient machine learning paradigm that allows overcoming some of the hurdles that characterize the successful training of deep neural networks, ranging from long training times to the needs of large datasets. While exploiting TL is a well established and successful training practice in Supervised Learning (SL), its applicability in Deep Reinforcement Learning (DRL) is rarer. In this paper, we study the level of transferability of three different variants of Deep-Q Networks on popular DRL benchmarks as well as on a set of novel, carefully designed control tasks. Our results show that transferring neural networks in a DRL context can be particularly challenging and is a process which in most cases results in negative transfer. In the attempt of understanding why Deep-Q Networks transfer so poorly, we gain novel insights into the training dynamics that characterizes this family of algorithms.
Optimizing model-agnostic Random Subspace ensembles
Sep 07, 2021
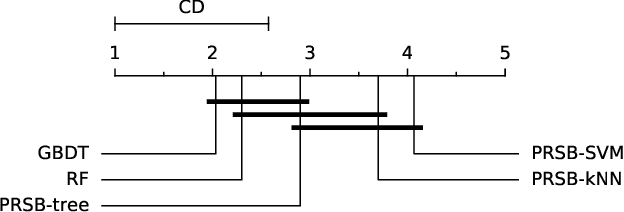
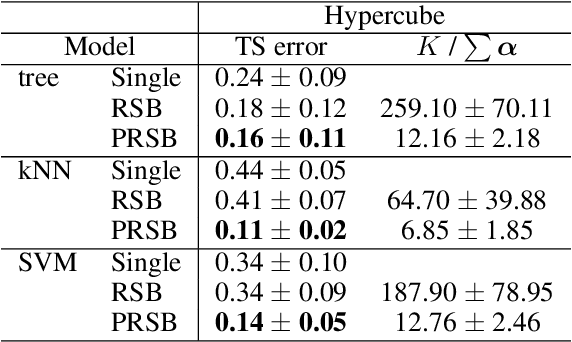
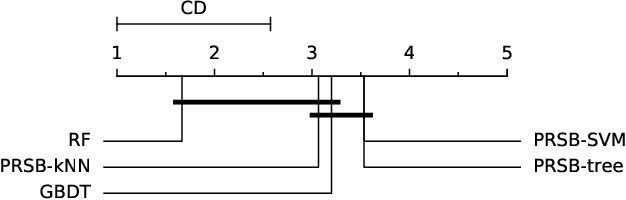
This paper presents a model-agnostic ensemble approach for supervised learning. The proposed approach alternates between (1) learning an ensemble of models using a parametric version of the Random Subspace approach, in which feature subsets are sampled according to Bernoulli distributions, and (2) identifying the parameters of the Bernoulli distributions that minimize the generalization error of the ensemble model. Parameter optimization is rendered tractable by using an importance sampling approach able to estimate the expected model output for any given parameter set, without the need to learn new models. While the degree of randomization is controlled by a hyper-parameter in standard Random Subspace, it has the advantage to be automatically tuned in our parametric version. Furthermore, model-agnostic feature importance scores can be easily derived from the trained ensemble model. We show the good performance of the proposed approach, both in terms of prediction and feature ranking, on simulated and real-world datasets. We also show that our approach can be successfully used for the reconstruction of gene regulatory networks.
Evaluation of Local Model-Agnostic Explanations Using Ground Truth
Jun 04, 2021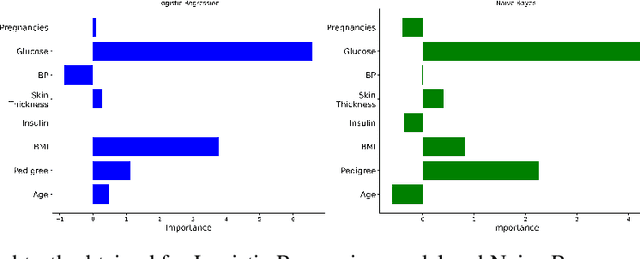

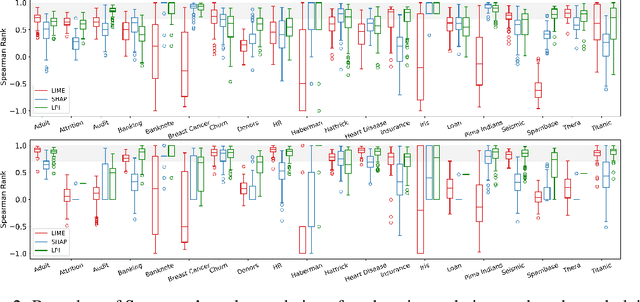
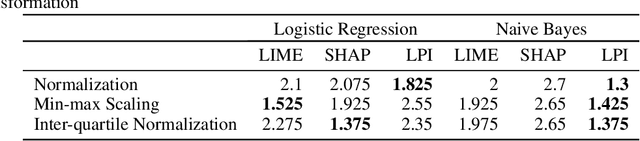
Explanation techniques are commonly evaluated using human-grounded methods, limiting the possibilities for large-scale evaluations and rapid progress in the development of new techniques. We propose a functionally-grounded evaluation procedure for local model-agnostic explanation techniques. In our approach, we generate ground truth for explanations when the black-box model is Logistic Regression and Gaussian Naive Bayes and compare how similar each explanation is to the extracted ground truth. In our empirical study, explanations of Local Interpretable Model-agnostic Explanations (LIME), SHapley Additive exPlanations (SHAP), and Local Permutation Importance (LPI) are compared in terms of how similar they are to the extracted ground truth. In the case of Logistic Regression, we find that the performance of the explanation techniques is highly dependent on the normalization of the data. In contrast, Local Permutation Importance outperforms the other techniques on Naive Bayes, irrespective of normalization. We hope that this work lays the foundation for further research into functionally-grounded evaluation methods for explanation techniques.
QVMix and QVMix-Max: Extending the Deep Quality-Value Family of Algorithms to Cooperative Multi-Agent Reinforcement Learning
Dec 22, 2020
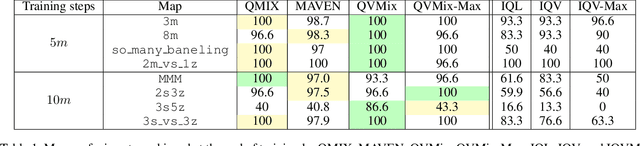
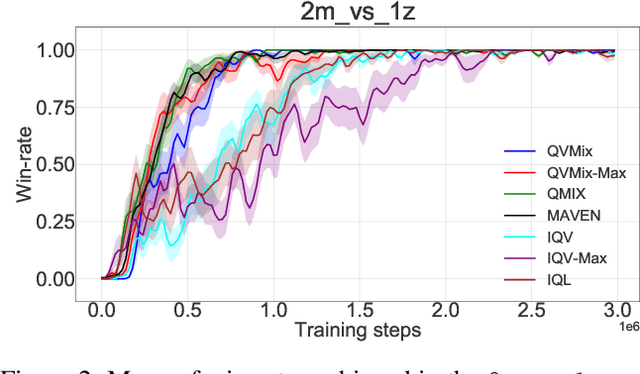
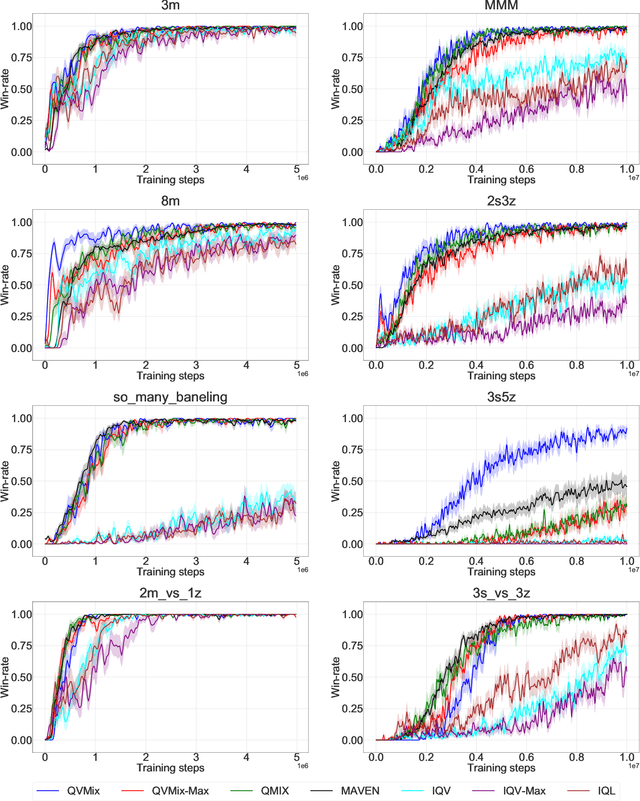
This paper introduces four new algorithms that can be used for tackling multi-agent reinforcement learning (MARL) problems occurring in cooperative settings. All algorithms are based on the Deep Quality-Value (DQV) family of algorithms, a set of techniques that have proven to be successful when dealing with single-agent reinforcement learning problems (SARL). The key idea of DQV algorithms is to jointly learn an approximation of the state-value function $V$, alongside an approximation of the state-action value function $Q$. We follow this principle and generalise these algorithms by introducing two fully decentralised MARL algorithms (IQV and IQV-Max) and two algorithms that are based on the centralised training with decentralised execution training paradigm (QVMix and QVMix-Max). We compare our algorithms with state-of-the-art MARL techniques on the popular StarCraft Multi-Agent Challenge (SMAC) environment. We show competitive results when QVMix and QVMix-Max are compared to well-known MARL techniques such as QMIX and MAVEN and show that QVMix can even outperform them on some of the tested environments, being the algorithm which performs best overall. We hypothesise that this is due to the fact that QVMix suffers less from the overestimation bias of the $Q$ function.
On the Transferability of Winning Tickets in Non-Natural Image Datasets
May 11, 2020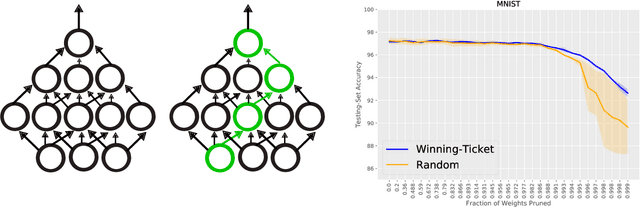
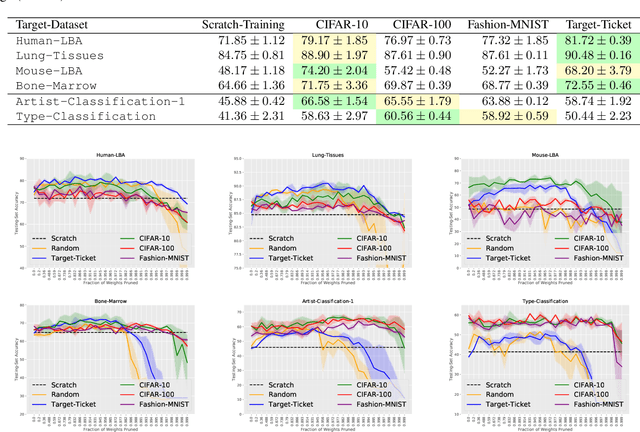

We study the generalization properties of pruned neural networks that are the winners of the lottery ticket hypothesis on datasets of natural images. We analyse their potential under conditions in which training data is scarce and comes from a non-natural domain. Specifically, we investigate whether pruned models that are found on the popular CIFAR-10/100 and Fashion-MNIST datasets, generalize to seven different datasets that come from the fields of digital pathology and digital heritage. Our results show that there are significant benefits in transferring and training sparse architectures over larger parametrized models, since in all of our experiments pruned networks, winners of the lottery ticket hypothesis, significantly outperform their larger unpruned counterparts. These results suggest that winning initializations do contain inductive biases that are generic to some extent, although, as reported by our experiments on the biomedical datasets, their generalization properties can be more limiting than what has been so far observed in the literature.
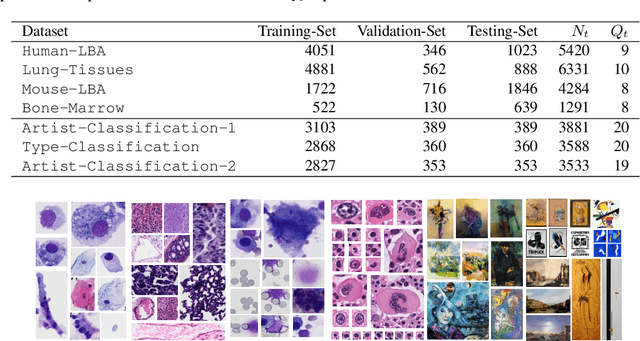
Multi-task pre-training of deep neural networks for digital pathology
May 07, 2020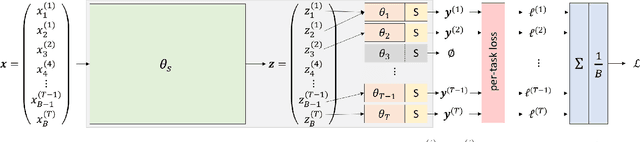
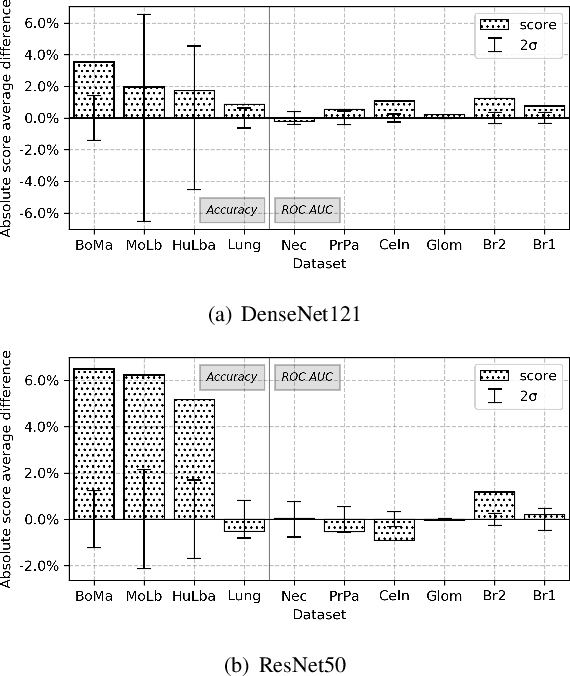
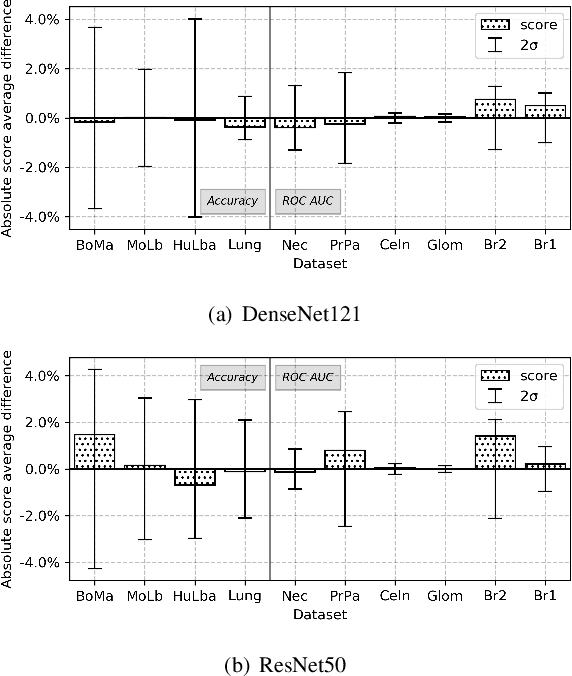
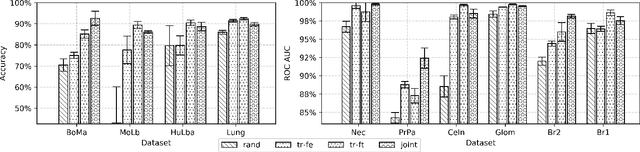
In this work, we investigate multi-task learning as a way of pre-training models for classification tasks in digital pathology. It is motivated by the fact that many small and medium-size datasets have been released by the community over the years whereas there is no large scale dataset similar to ImageNet in the domain. We first assemble and transform many digital pathology datasets into a pool of 22 classification tasks and almost 900k images. Then, we propose a simple architecture and training scheme for creating a transferable model and a robust evaluation and selection protocol in order to evaluate our method. Depending on the target task, we show that our models used as feature extractors either improve significantly over ImageNet pre-trained models or provide comparable performance. Fine-tuning improves performance over feature extraction and is able to recover the lack of specificity of ImageNet features, as both pre-training sources yield comparable performance.