 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom global to local MDI variable importances for random forests and when they are Shapley values
Nov 03, 2021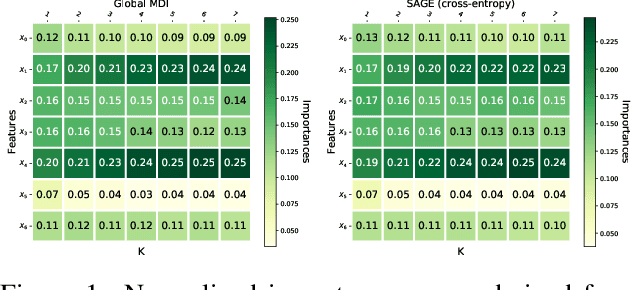
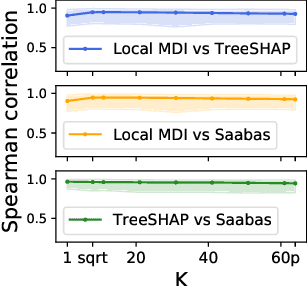

Random forests have been widely used for their ability to provide so-called importance measures, which give insight at a global (per dataset) level on the relevance of input variables to predict a certain output. On the other hand, methods based on Shapley values have been introduced to refine the analysis of feature relevance in tree-based models to a local (per instance) level. In this context, we first show that the global Mean Decrease of Impurity (MDI) variable importance scores correspond to Shapley values under some conditions. Then, we derive a local MDI importance measure of variable relevance, which has a very natural connection with the global MDI measure and can be related to a new notion of local feature relevance. We further link local MDI importances with Shapley values and discuss them in the light of related measures from the literature. The measures are illustrated through experiments on several classification and regression problems.
Deep generative modeling for probabilistic forecasting in power systems
Jun 30, 2021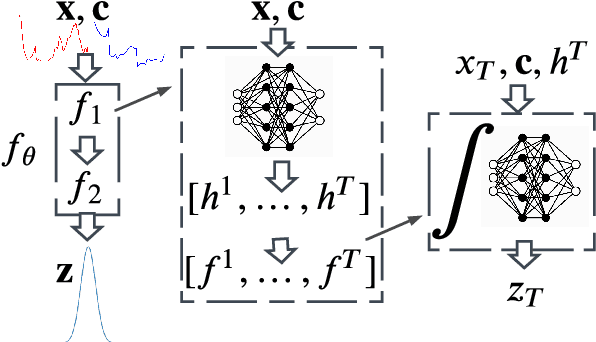
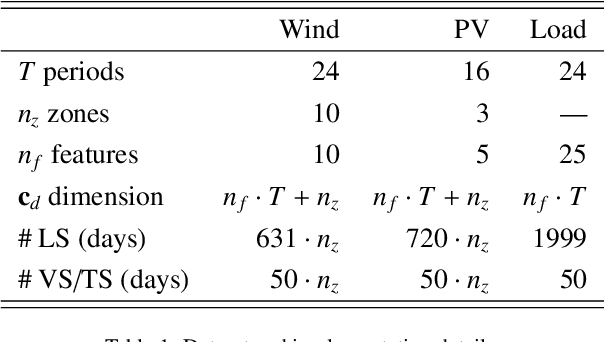
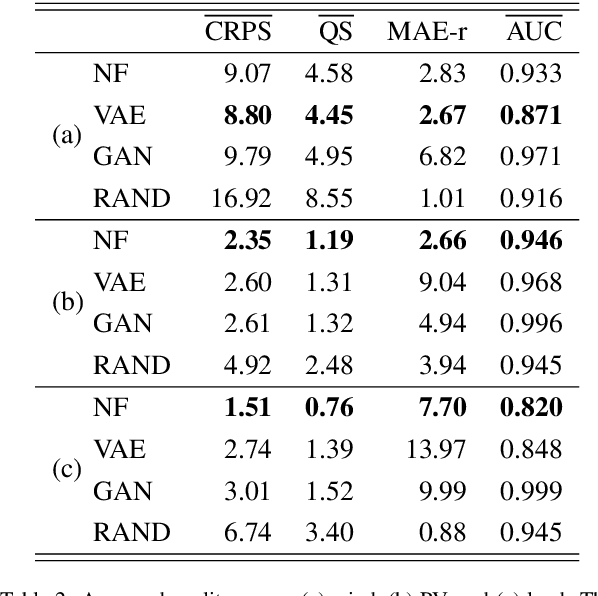
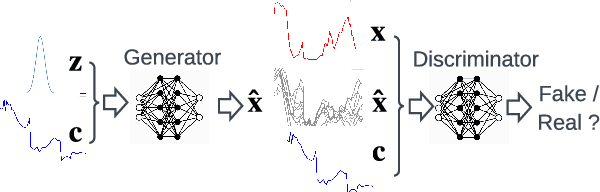
Greater direct electrification of end-use sectors with a higher share of renewables is one of the pillars to power a carbon-neutral society by 2050. This study uses a recent deep learning technique, the normalizing flows, to produce accurate probabilistic forecasts that are crucial for decision-makers to face the new challenges in power systems applications. Through comprehensive empirical evaluations using the open data of the Global Energy Forecasting Competition 2014, we demonstrate that our methodology is competitive with other state-of-the-art deep learning generative models: generative adversarial networks and variational autoencoders. The models producing weather-based wind, solar power, and load scenarios are properly compared both in terms of forecast value, by considering the case study of an energy retailer, and quality using several complementary metrics.
A Probabilistic Forecast-Driven Strategy for a Risk-Aware Participation in the Capacity Firming Market
Jun 21, 2021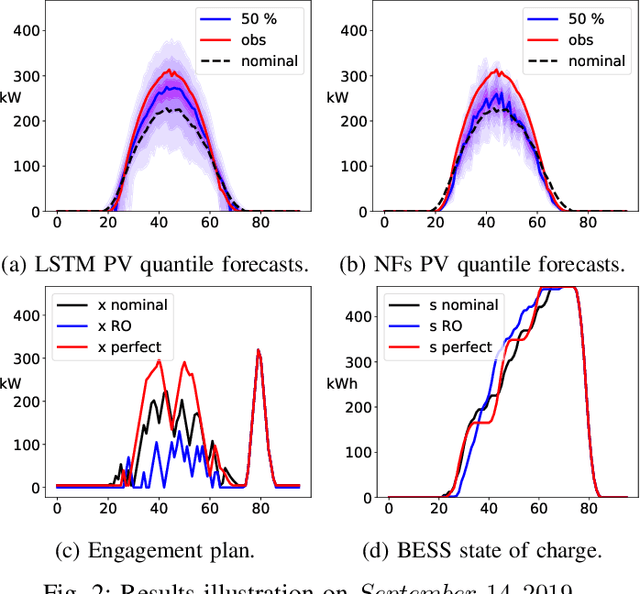
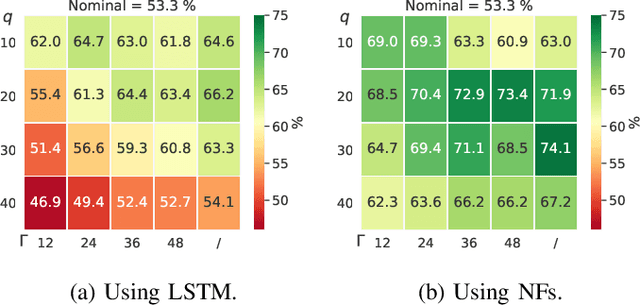
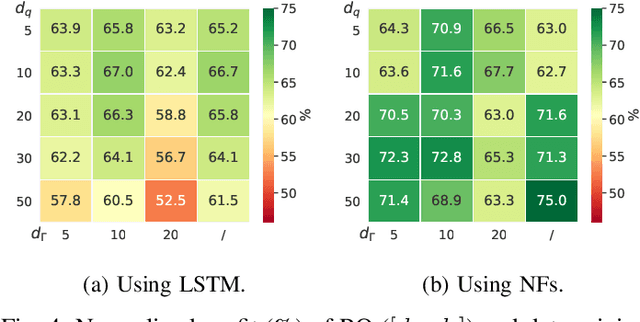
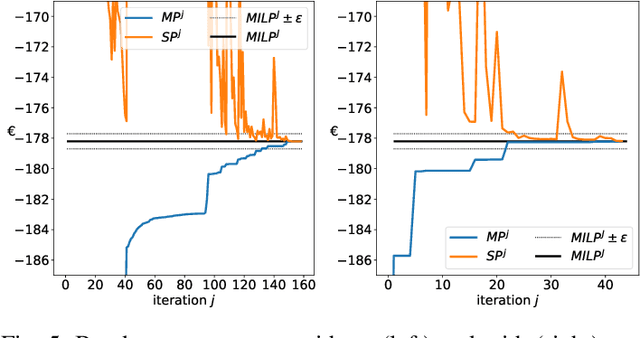
The core contribution is to propose a probabilistic forecast-driven strategy, modeled as a min-max-min robust optimization problem with recourse, and solved using a Benders-dual cutting plane algorithm in a tractable manner. The convergence is improved by building an initial set of cuts. In addition, a dynamic risk-averse parameters selection strategy based on the quantile forecasts distribution is proposed. A secondary contribution is to use a recently developed deep learning model known as normalizing flows to generate quantile forecasts of renewable generation for the robust optimization problem. This technique provides a general mechanism for defining expressive probability distributions, only requiring the specification of a base distribution and a series of bijective transformations. Overall, the robust approach improves the results over a deterministic approach with nominal point forecasts by finding a trade-off between conservative and risk-seeking policies. The case study uses the photovoltaic generation monitored on-site at the University of Li\`ege (ULi\`ege), Belgium.
Importance measures derived from random forests: characterisation and extension
Jun 21, 2021Nowadays new technologies, and especially artificial intelligence, are more and more established in our society. Big data analysis and machine learning, two sub-fields of artificial intelligence, are at the core of many recent breakthroughs in many application fields (e.g., medicine, communication, finance, ...), including some that are strongly related to our day-to-day life (e.g., social networks, computers, smartphones, ...). In machine learning, significant improvements are usually achieved at the price of an increasing computational complexity and thanks to bigger datasets. Currently, cutting-edge models built by the most advanced machine learning algorithms typically became simultaneously very efficient and profitable but also extremely complex. Their complexity is to such an extent that these models are commonly seen as black-boxes providing a prediction or a decision which can not be interpreted or justified. Nevertheless, whether these models are used autonomously or as a simple decision-making support tool, they are already being used in machine learning applications where health and human life are at stake. Therefore, it appears to be an obvious necessity not to blindly believe everything coming out of those models without a detailed understanding of their predictions or decisions. Accordingly, this thesis aims at improving the interpretability of models built by a specific family of machine learning algorithms, the so-called tree-based methods. Several mechanisms have been proposed to interpret these models and we aim along this thesis to improve their understanding, study their properties, and define their limitations.
Random Subspace with Trees for Feature Selection Under Memory Constraints
Sep 06, 2017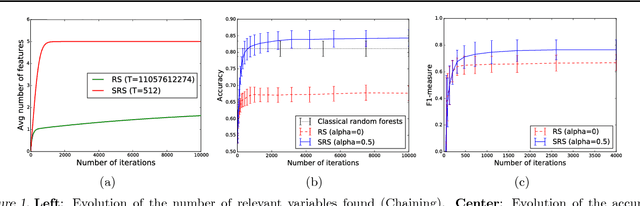
Dealing with datasets of very high dimension is a major challenge in machine learning. In this paper, we consider the problem of feature selection in applications where the memory is not large enough to contain all features. In this setting, we propose a novel tree-based feature selection approach that builds a sequence of randomized trees on small subsamples of variables mixing both variables already identified as relevant by previous models and variables randomly selected among the other variables. As our main contribution, we provide an in-depth theoretical analysis of this method in infinite sample setting. In particular, we study its soundness with respect to common definitions of feature relevance and its convergence speed under various variable dependance scenarios. We also provide some preliminary empirical results highlighting the potential of the approach.
Context-dependent feature analysis with random forests
May 12, 2016
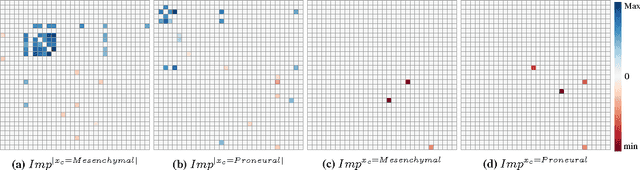


In many cases, feature selection is often more complicated than identifying a single subset of input variables that would together explain the output. There may be interactions that depend on contextual information, i.e., variables that reveal to be relevant only in some specific circumstances. In this setting, the contribution of this paper is to extend the random forest variable importances framework in order (i) to identify variables whose relevance is context-dependent and (ii) to characterize as precisely as possible the effect of contextual information on these variables. The usage and the relevance of our framework for highlighting context-dependent variables is illustrated on both artificial and real datasets.
Simple connectome inference from partial correlation statistics in calcium imaging
Nov 18, 2014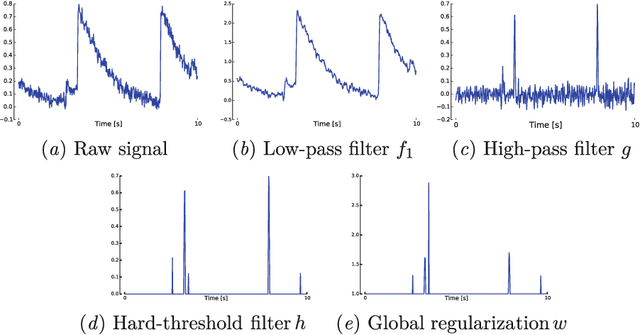
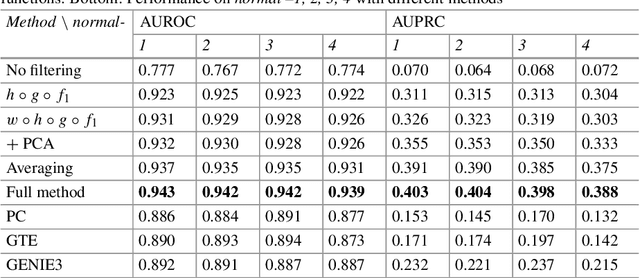
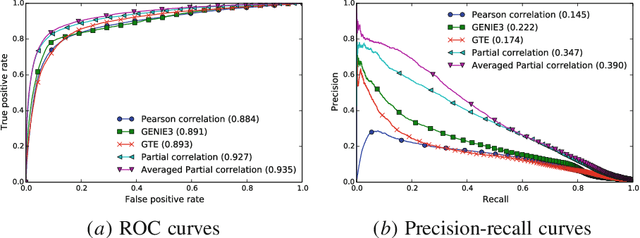

In this work, we propose a simple yet effective solution to the problem of connectome inference in calcium imaging data. The proposed algorithm consists of two steps. First, processing the raw signals to detect neural peak activities. Second, inferring the degree of association between neurons from partial correlation statistics. This paper summarises the methodology that led us to win the Connectomics Challenge, proposes a simplified version of our method, and finally compares our results with respect to other inference methods.