 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom global to local MDI variable importances for random forests and when they are Shapley values
Nov 03, 2021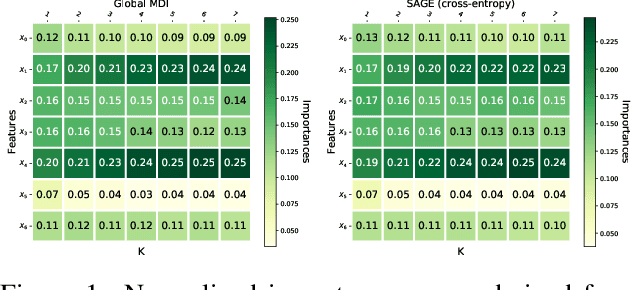
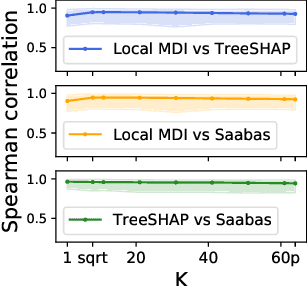

Random forests have been widely used for their ability to provide so-called importance measures, which give insight at a global (per dataset) level on the relevance of input variables to predict a certain output. On the other hand, methods based on Shapley values have been introduced to refine the analysis of feature relevance in tree-based models to a local (per instance) level. In this context, we first show that the global Mean Decrease of Impurity (MDI) variable importance scores correspond to Shapley values under some conditions. Then, we derive a local MDI importance measure of variable relevance, which has a very natural connection with the global MDI measure and can be related to a new notion of local feature relevance. We further link local MDI importances with Shapley values and discuss them in the light of related measures from the literature. The measures are illustrated through experiments on several classification and regression problems.
Gradient tree boosting with random output projections for multi-label classification and multi-output regression
May 18, 2019
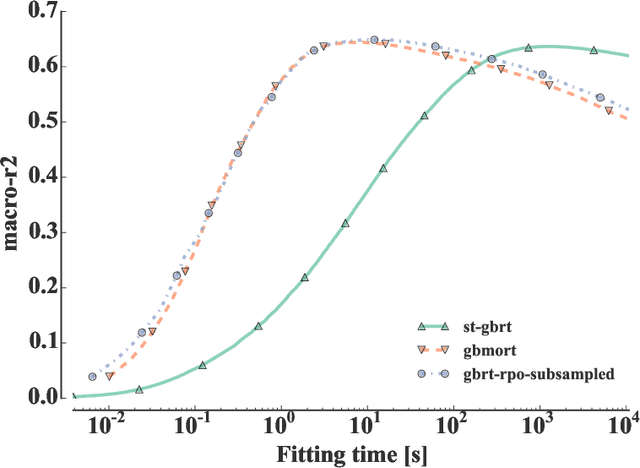
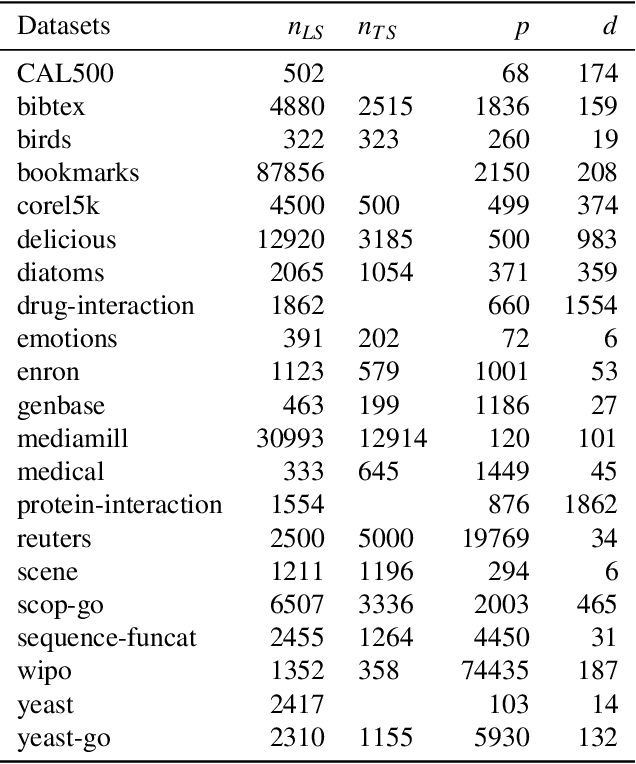
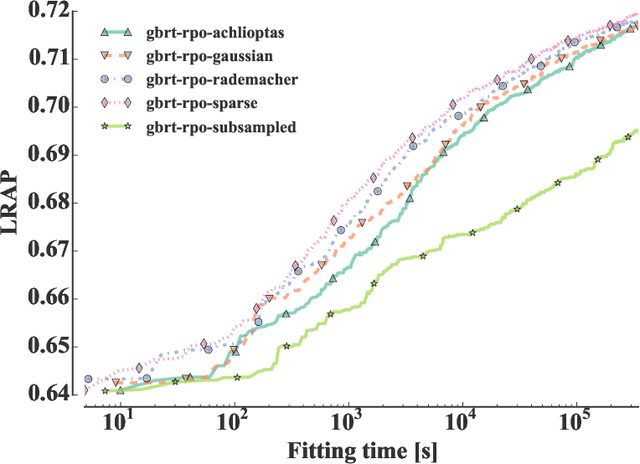
In many applications of supervised learning, multiple classification or regression outputs have to be predicted jointly. We consider several extensions of gradient boosting to address such problems. We first propose a straightforward adaptation of gradient boosting exploiting multiple output regression trees as base learners. We then argue that this method is only expected to be optimal when the outputs are fully correlated, as it forces the partitioning induced by the tree base learners to be shared by all outputs. We then propose a novel extension of gradient tree boosting to specifically address this issue. At each iteration of this new method, a regression tree structure is grown to fit a single random projection of the current residuals and the predictions of this tree are fitted linearly to the current residuals of all the outputs, independently. Because of this linear fit, the method can adapt automatically to any output correlation structure. Extensive experiments are conducted with this method, as well as other algorithmic variants, on several artificial and real problems. Randomly projecting the output space is shown to provide a better adaptation to different output correlation patterns and is therefore competitive with the best of the other methods in most settings. Thanks to model sharing, the convergence speed is also improved, reducing the computing times (or the complexity of the model) to reach a specific accuracy.
Unit Commitment using Nearest Neighbor as a Short-Term Proxy
Feb 28, 2018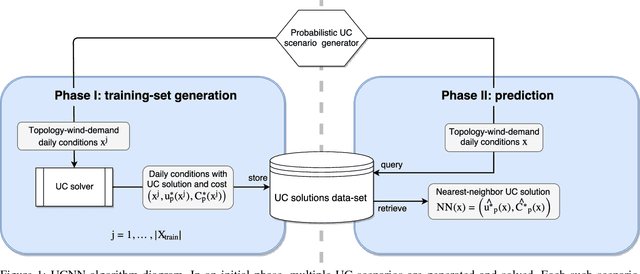
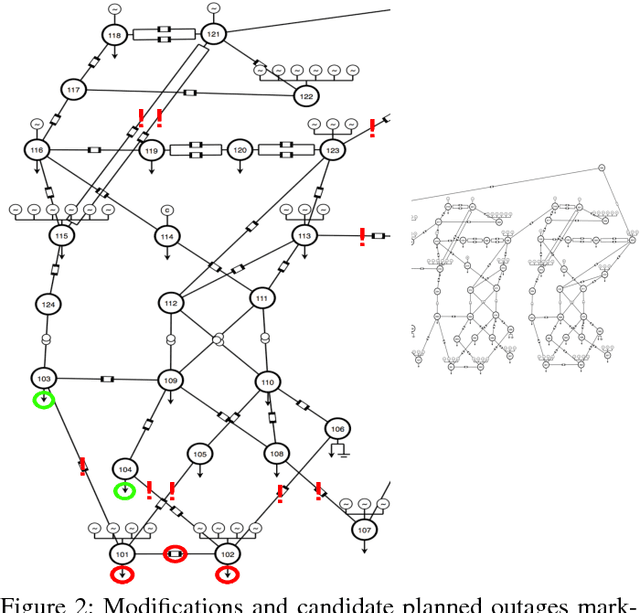
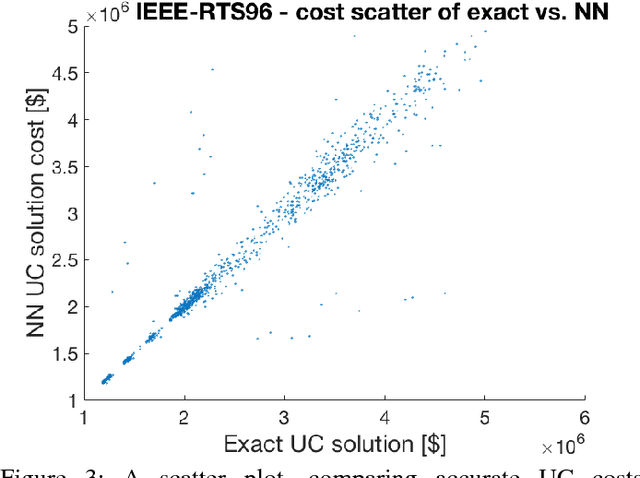
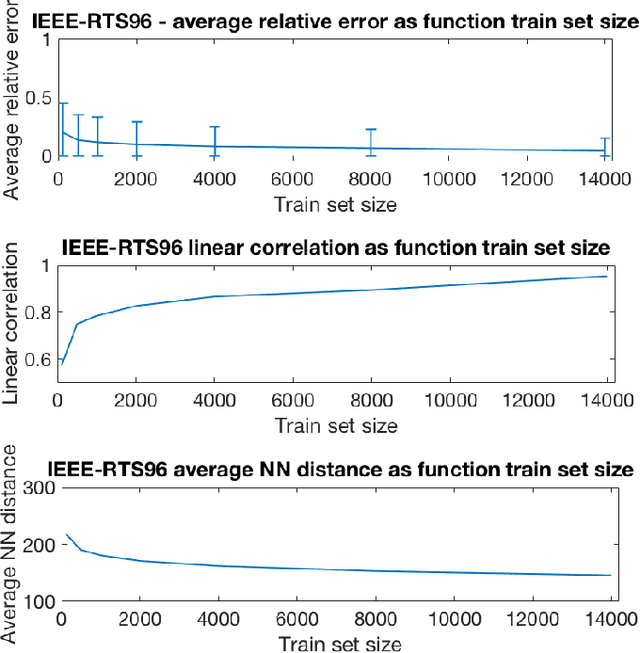
We devise the Unit Commitment Nearest Neighbor (UCNN) algorithm to be used as a proxy for quickly approximating outcomes of short-term decisions, to make tractable hierarchical long-term assessment and planning for large power systems. Experimental results on updated versions of IEEE-RTS79 and IEEE-RTS96 show high accuracy measured on operational cost, achieved in runtimes that are lower in several orders of magnitude than the traditional approach.
Random Subspace with Trees for Feature Selection Under Memory Constraints
Sep 06, 2017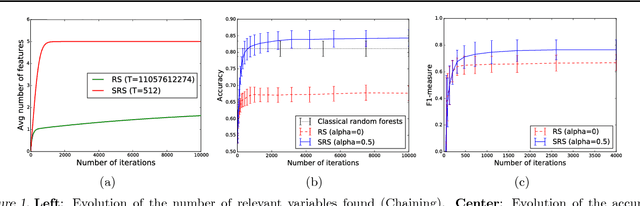
Dealing with datasets of very high dimension is a major challenge in machine learning. In this paper, we consider the problem of feature selection in applications where the memory is not large enough to contain all features. In this setting, we propose a novel tree-based feature selection approach that builds a sequence of randomized trees on small subsamples of variables mixing both variables already identified as relevant by previous models and variables randomly selected among the other variables. As our main contribution, we provide an in-depth theoretical analysis of this method in infinite sample setting. In particular, we study its soundness with respect to common definitions of feature relevance and its convergence speed under various variable dependance scenarios. We also provide some preliminary empirical results highlighting the potential of the approach.
Context-dependent feature analysis with random forests
May 12, 2016
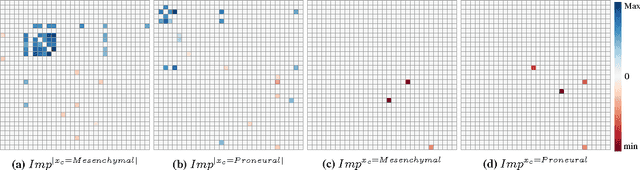


In many cases, feature selection is often more complicated than identifying a single subset of input variables that would together explain the output. There may be interactions that depend on contextual information, i.e., variables that reveal to be relevant only in some specific circumstances. In this setting, the contribution of this paper is to extend the random forest variable importances framework in order (i) to identify variables whose relevance is context-dependent and (ii) to characterize as precisely as possible the effect of contextual information on these variables. The usage and the relevance of our framework for highlighting context-dependent variables is illustrated on both artificial and real datasets.
Random forests with random projections of the output space for high dimensional multi-label classification
Sep 29, 2014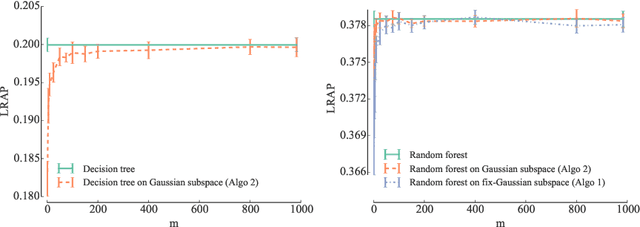
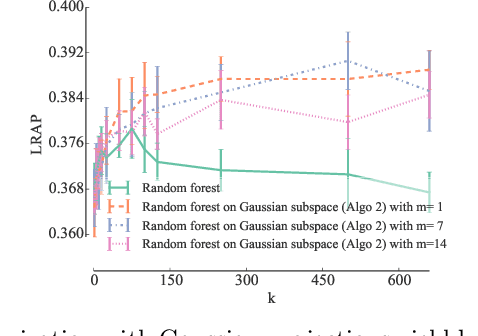

We adapt the idea of random projections applied to the output space, so as to enhance tree-based ensemble methods in the context of multi-label classification. We show how learning time complexity can be reduced without affecting computational complexity and accuracy of predictions. We also show that random output space projections may be used in order to reach different bias-variance tradeoffs, over a broad panel of benchmark problems, and that this may lead to improved accuracy while reducing significantly the computational burden of the learning stage.
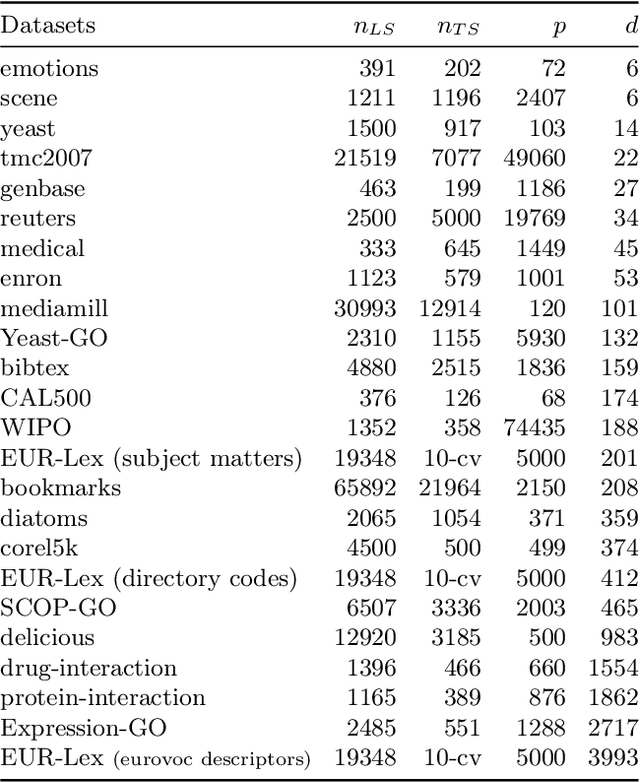
Classifying pairs with trees for supervised biological network inference
Apr 24, 2014
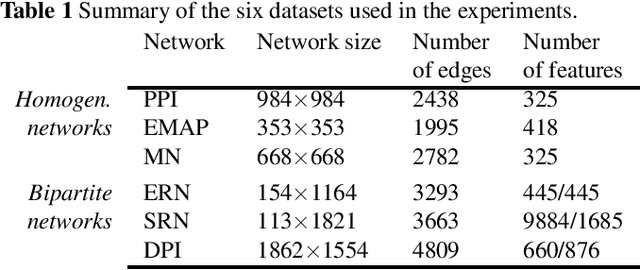
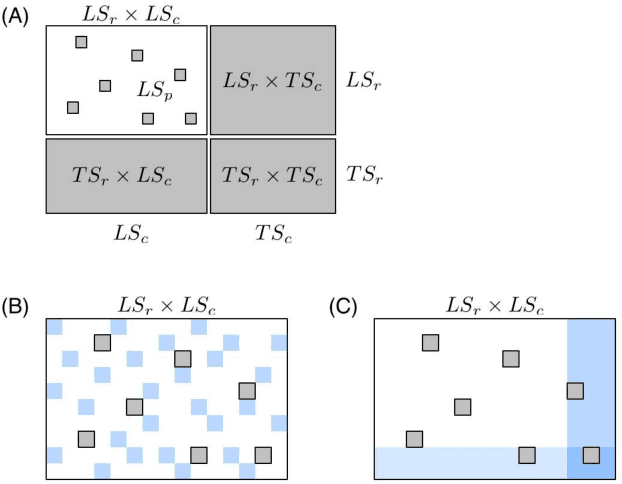
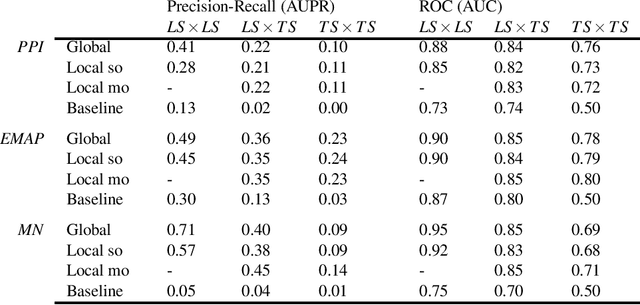
Networks are ubiquitous in biology and computational approaches have been largely investigated for their inference. In particular, supervised machine learning methods can be used to complete a partially known network by integrating various measurements. Two main supervised frameworks have been proposed: the local approach, which trains a separate model for each network node, and the global approach, which trains a single model over pairs of nodes. Here, we systematically investigate, theoretically and empirically, the exploitation of tree-based ensemble methods in the context of these two approaches for biological network inference. We first formalize the problem of network inference as classification of pairs, unifying in the process homogeneous and bipartite graphs and discussing two main sampling schemes. We then present the global and the local approaches, extending the later for the prediction of interactions between two unseen network nodes, and discuss their specializations to tree-based ensemble methods, highlighting their interpretability and drawing links with clustering techniques. Extensive computational experiments are carried out with these methods on various biological networks that clearly highlight that these methods are competitive with existing methods.
On the Construction of the Inclusion Boundary Neighbourhood for Markov Equivalence Classes of Bayesian Network Structures
Dec 12, 2012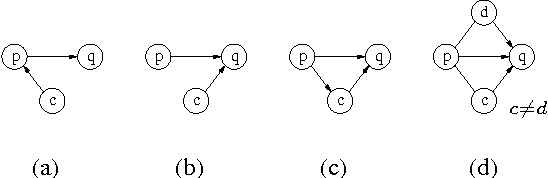
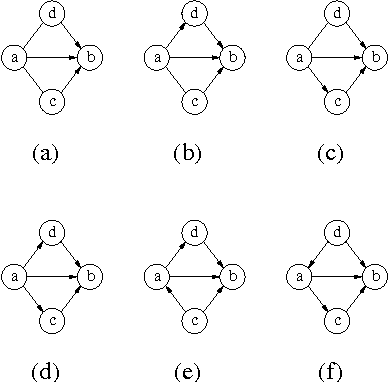
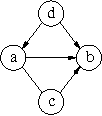
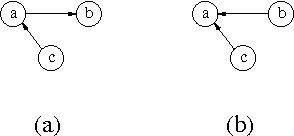
The problem of learning Markov equivalence classes of Bayesian network structures may be solved by searching for the maximum of a scoring metric in a space of these classes. This paper deals with the definition and analysis of one such search space. We use a theoretically motivated neighbourhood, the inclusion boundary, and represent equivalence classes by essential graphs. We show that this search space is connected and that the score of the neighbours can be evaluated incrementally. We devise a practical way of building this neighbourhood for an essential graph that is purely graphical and does not explicitely refer to the underlying independences. We find that its size can be intractable, depending on the complexity of the essential graph of the equivalence class. The emphasis is put on the potential use of this space with greedy hill -climbing search
Optimized Look-Ahead Tree Policies: A Bridge Between Look-Ahead Tree Policies and Direct Policy Search
Aug 23, 2012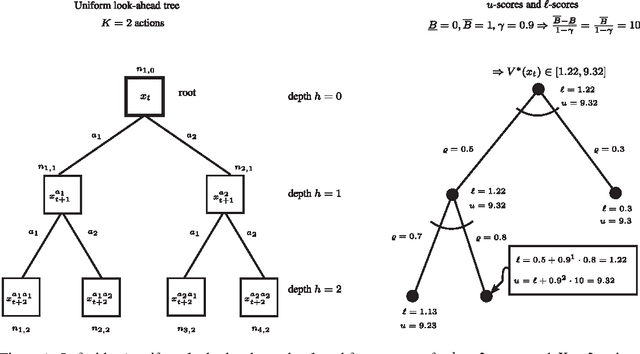
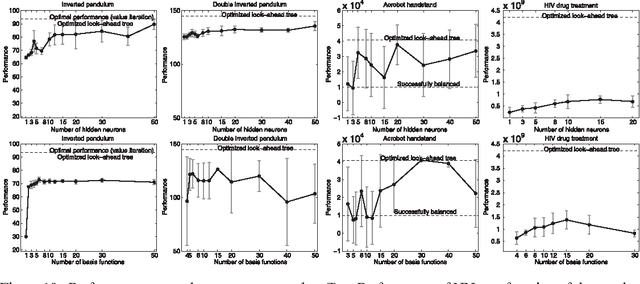
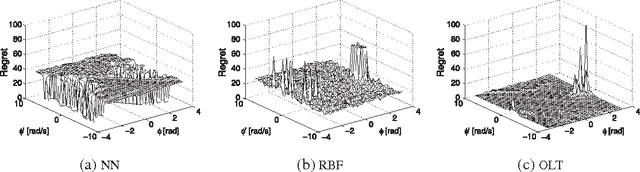
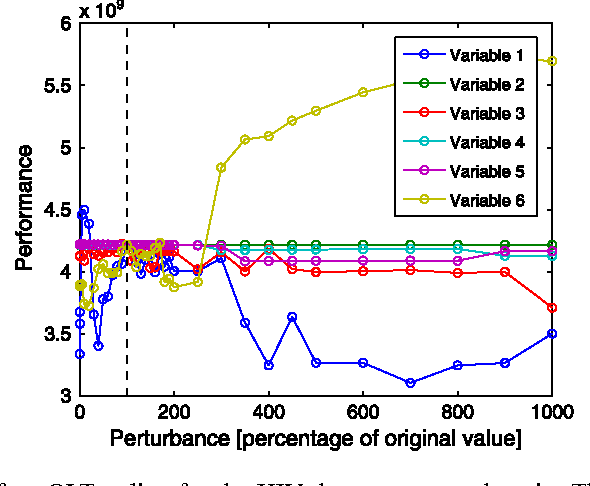
Direct policy search (DPS) and look-ahead tree (LT) policies are two widely used classes of techniques to produce high performance policies for sequential decision-making problems. To make DPS approaches work well, one crucial issue is to select an appropriate space of parameterized policies with respect to the targeted problem. A fundamental issue in LT approaches is that, to take good decisions, such policies must develop very large look-ahead trees which may require excessive online computational resources. In this paper, we propose a new hybrid policy learning scheme that lies at the intersection of DPS and LT, in which the policy is an algorithm that develops a small look-ahead tree in a directed way, guided by a node scoring function that is learned through DPS. The LT-based representation is shown to be a versatile way of representing policies in a DPS scheme, while at the same time, DPS enables to significantly reduce the size of the look-ahead trees that are required to take high-quality decisions. We experimentally compare our method with two other state-of-the-art DPS techniques and four common LT policies on four benchmark domains and show that it combines the advantages of the two techniques from which it originates. In particular, we show that our method: (1) produces overall better performing policies than both pure DPS and pure LT policies, (2) requires a substantially smaller number of policy evaluations than other DPS techniques, (3) is easy to tune and (4) results in policies that are quite robust with respect to perturbations of the initial conditions.
Meta-Learning of Exploration/Exploitation Strategies: The Multi-Armed Bandit Case
Jul 22, 2012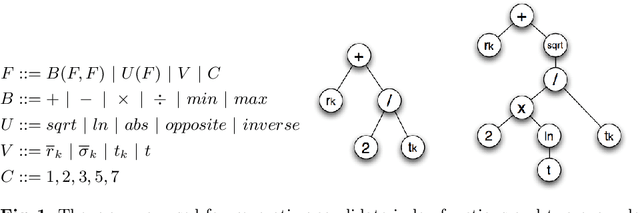
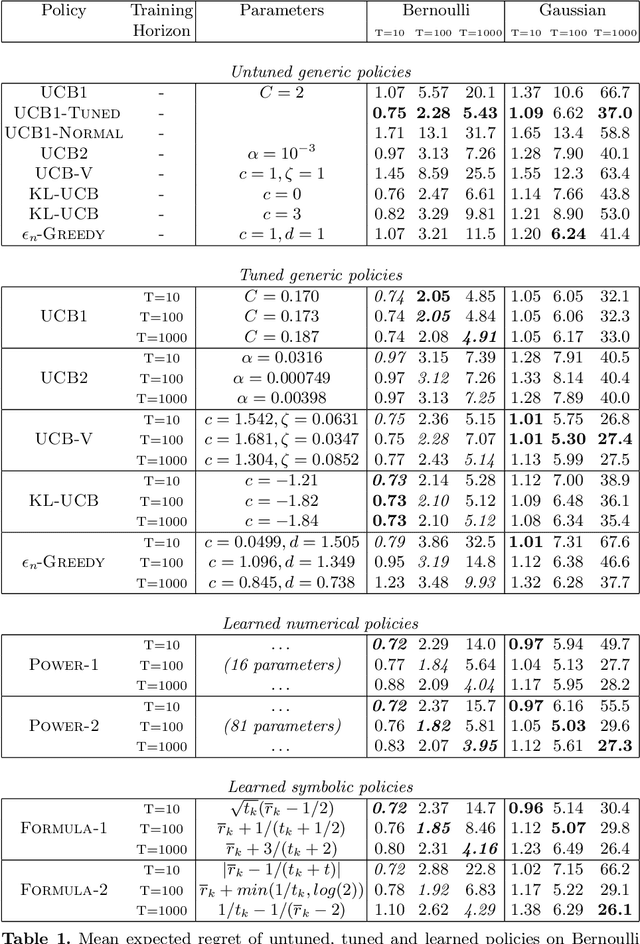
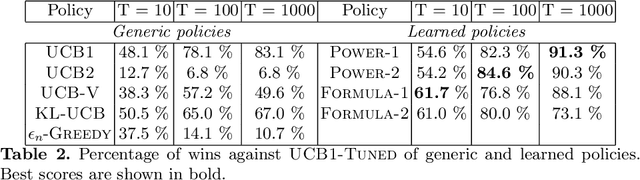
The exploration/exploitation (E/E) dilemma arises naturally in many subfields of Science. Multi-armed bandit problems formalize this dilemma in its canonical form. Most current research in this field focuses on generic solutions that can be applied to a wide range of problems. However, in practice, it is often the case that a form of prior information is available about the specific class of target problems. Prior knowledge is rarely used in current solutions due to the lack of a systematic approach to incorporate it into the E/E strategy. To address a specific class of E/E problems, we propose to proceed in three steps: (i) model prior knowledge in the form of a probability distribution over the target class of E/E problems; (ii) choose a large hypothesis space of candidate E/E strategies; and (iii), solve an optimization problem to find a candidate E/E strategy of maximal average performance over a sample of problems drawn from the prior distribution. We illustrate this meta-learning approach with two different hypothesis spaces: one where E/E strategies are numerically parameterized and another where E/E strategies are represented as small symbolic formulas. We propose appropriate optimization algorithms for both cases. Our experiments, with two-armed Bernoulli bandit problems and various playing budgets, show that the meta-learnt E/E strategies outperform generic strategies of the literature (UCB1, UCB1-Tuned, UCB-v, KL-UCB and epsilon greedy); they also evaluate the robustness of the learnt E/E strategies, by tests carried out on arms whose rewards follow a truncated Gaussian distribution.