 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-User MultiWOZ: Task-Oriented Dialogues among Multiple Users
Oct 31, 2023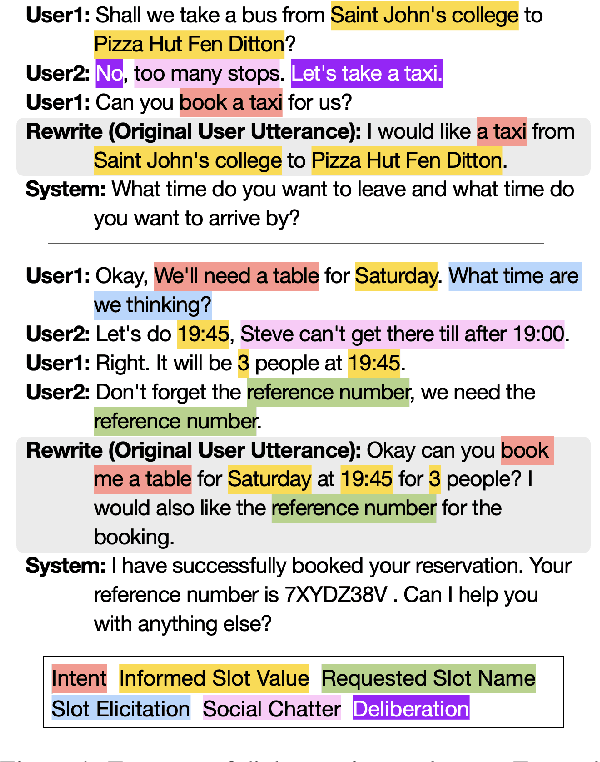
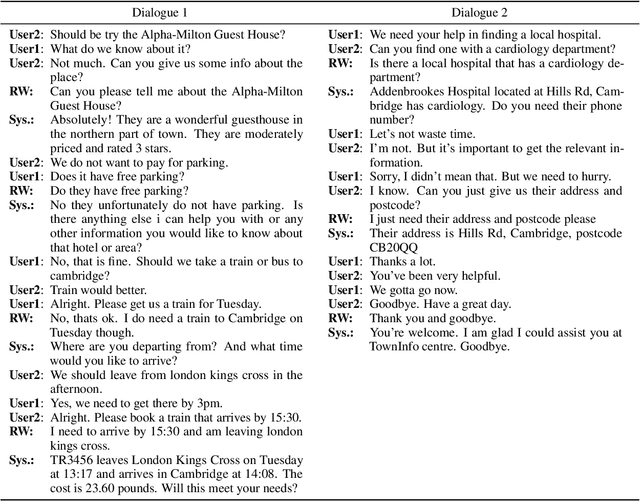
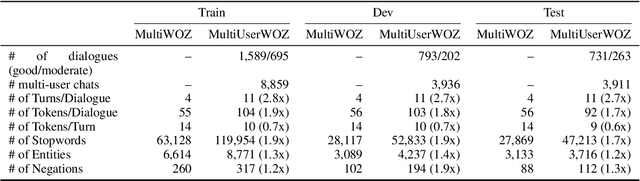
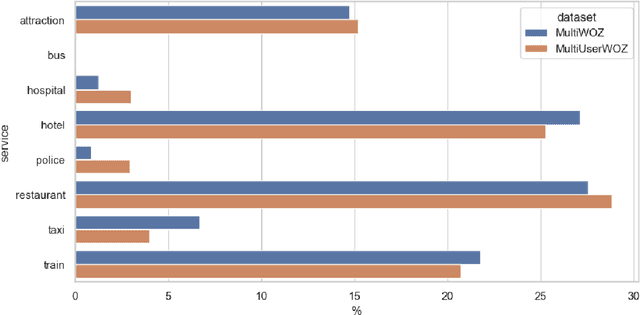
While most task-oriented dialogues assume conversations between the agent and one user at a time, dialogue systems are increasingly expected to communicate with multiple users simultaneously who make decisions collaboratively. To facilitate development of such systems, we release the Multi-User MultiWOZ dataset: task-oriented dialogues among two users and one agent. To collect this dataset, each user utterance from MultiWOZ 2.2 was replaced with a small chat between two users that is semantically and pragmatically consistent with the original user utterance, thus resulting in the same dialogue state and system response. These dialogues reflect interesting dynamics of collaborative decision-making in task-oriented scenarios, e.g., social chatter and deliberation. Supported by this data, we propose the novel task of multi-user contextual query rewriting: to rewrite a task-oriented chat between two users as a concise task-oriented query that retains only task-relevant information and that is directly consumable by the dialogue system. We demonstrate that in multi-user dialogues, using predicted rewrites substantially improves dialogue state tracking without modifying existing dialogue systems that are trained for single-user dialogues. Further, this method surpasses training a medium-sized model directly on multi-user dialogues and generalizes to unseen domains.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
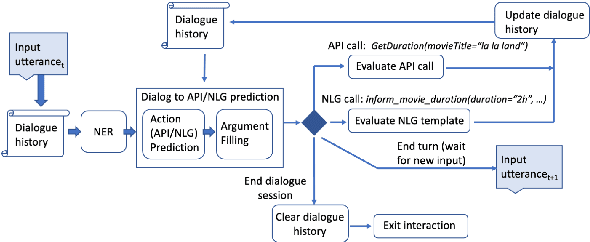

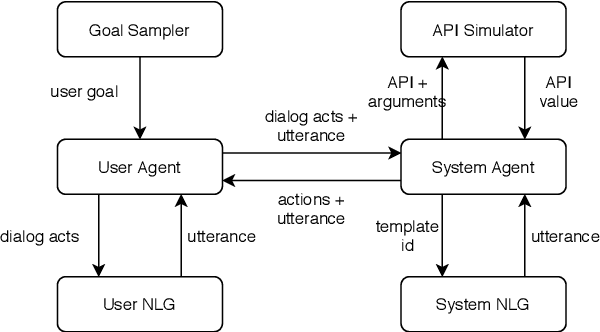
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
OodGAN: Generative Adversarial Network for Out-of-Domain Data Generation
Apr 06, 2021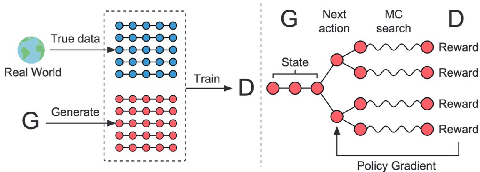
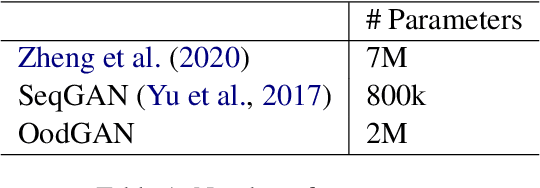
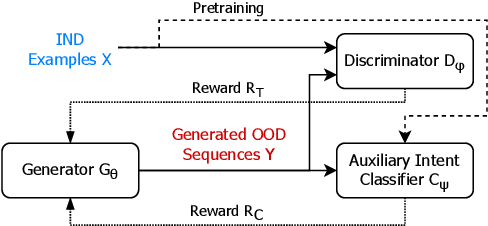
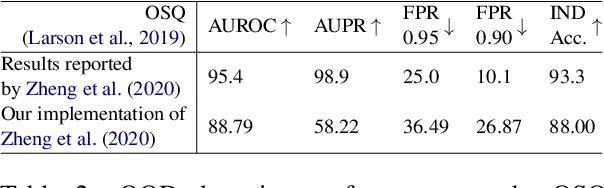
Detecting an Out-of-Domain (OOD) utterance is crucial for a robust dialog system. Most dialog systems are trained on a pool of annotated OOD data to achieve this goal. However, collecting the annotated OOD data for a given domain is an expensive process. To mitigate this issue, previous works have proposed generative adversarial networks (GAN) based models to generate OOD data for a given domain automatically. However, these proposed models do not work directly with the text. They work with the text's latent space instead, enforcing these models to include components responsible for encoding text into latent space and decoding it back, such as auto-encoder. These components increase the model complexity, making it difficult to train. We propose OodGAN, a sequential generative adversarial network (SeqGAN) based model for OOD data generation. Our proposed model works directly on the text and hence eliminates the need to include an auto-encoder. OOD data generated using OodGAN model outperforms state-of-the-art in OOD detection metrics for ROSTD (67% relative improvement in FPR 0.95) and OSQ datasets (28% relative improvement in FPR 0.95) (Zheng et al., 2020).
Dialog Simulation with Realistic Variations for Training Goal-Oriented Conversational Systems
Nov 16, 2020
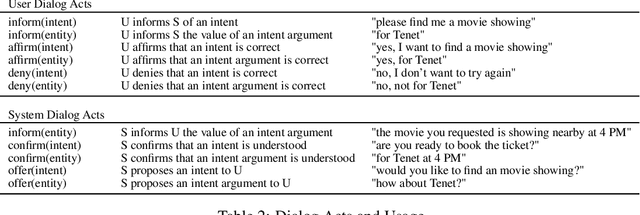
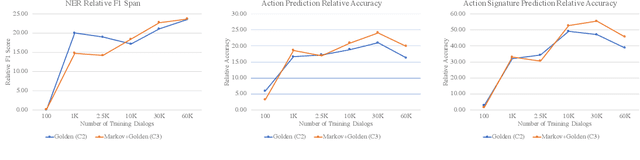
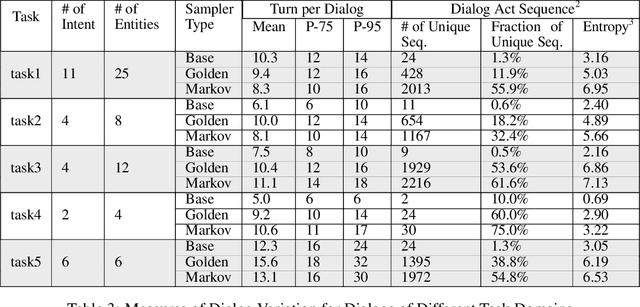
Goal-oriented dialog systems enable users to complete specific goals like requesting information about a movie or booking a ticket. Typically the dialog system pipeline contains multiple ML models, including natural language understanding, state tracking and action prediction (policy learning). These models are trained through a combination of supervised or reinforcement learning methods and therefore require collection of labeled domain specific datasets. However, collecting annotated datasets with language and dialog-flow variations is expensive, time-consuming and scales poorly due to human involvement. In this paper, we propose an approach for automatically creating a large corpus of annotated dialogs from a few thoroughly annotated sample dialogs and the dialog schema. Our approach includes a novel goal-sampling technique for sampling plausible user goals and a dialog simulation technique that uses heuristic interplay between the user and the system (Alexa), where the user tries to achieve the sampled goal. We validate our approach by generating data and training three different downstream conversational ML models. We achieve 18 ? 50% relative accuracy improvements on a held-out test set compared to a baseline dialog generation approach that only samples natural language and entity value variations from existing catalogs but does not generate any novel dialog flow variations. We also qualitatively establish that the proposed approach is better than the baseline. Moreover, several different conversational experiences have been built using this method, which enables customers to have a wide variety of conversations with Alexa.
On the Construction of the Inclusion Boundary Neighbourhood for Markov Equivalence Classes of Bayesian Network Structures
Dec 12, 2012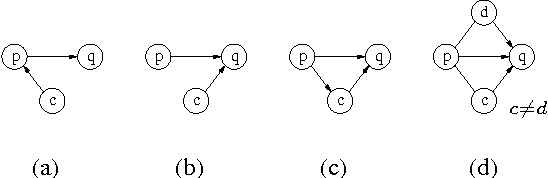
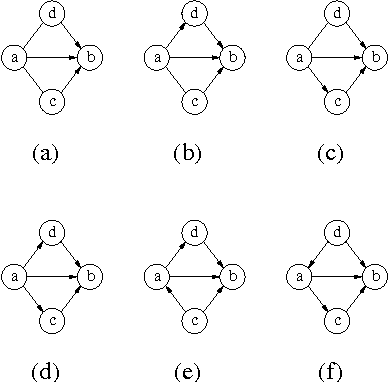
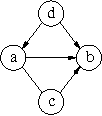
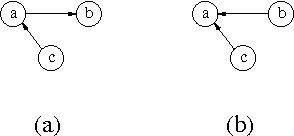
The problem of learning Markov equivalence classes of Bayesian network structures may be solved by searching for the maximum of a scoring metric in a space of these classes. This paper deals with the definition and analysis of one such search space. We use a theoretically motivated neighbourhood, the inclusion boundary, and represent equivalence classes by essential graphs. We show that this search space is connected and that the score of the neighbours can be evaluated incrementally. We devise a practical way of building this neighbourhood for an essential graph that is purely graphical and does not explicitely refer to the underlying independences. We find that its size can be intractable, depending on the complexity of the essential graph of the equivalence class. The emphasis is put on the potential use of this space with greedy hill -climbing search
Learning Inclusion-Optimal Chordal Graphs
Jun 13, 2012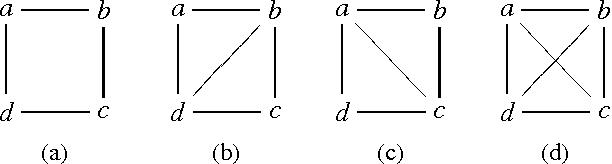
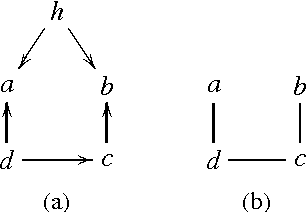
Chordal graphs can be used to encode dependency models that are representable by both directed acyclic and undirected graphs. This paper discusses a very simple and efficient algorithm to learn the chordal structure of a probabilistic model from data. The algorithm is a greedy hill-climbing search algorithm that uses the inclusion boundary neighborhood over chordal graphs. In the limit of a large sample size and under appropriate hypotheses on the scoring criterion, we prove that the algorithm will find a structure that is inclusion-optimal when the dependency model of the data-generating distribution can be represented exactly by an undirected graph. The algorithm is evaluated on simulated datasets.