 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlquist 5.0: Dialogue Trees Meet Generative Models. A Novel Approach for Enhancing SocialBot Conversations
Oct 24, 2023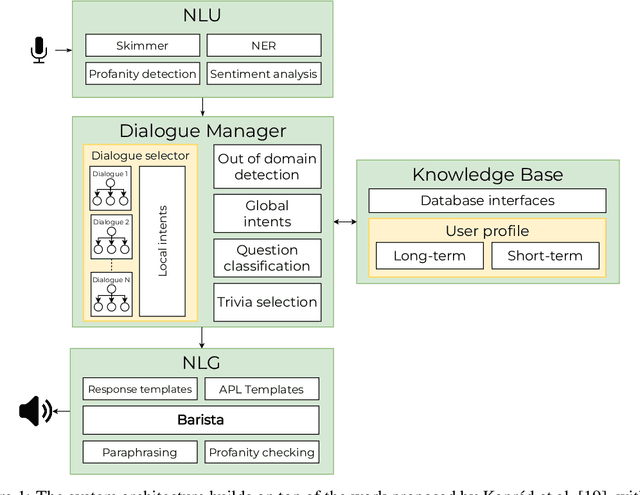

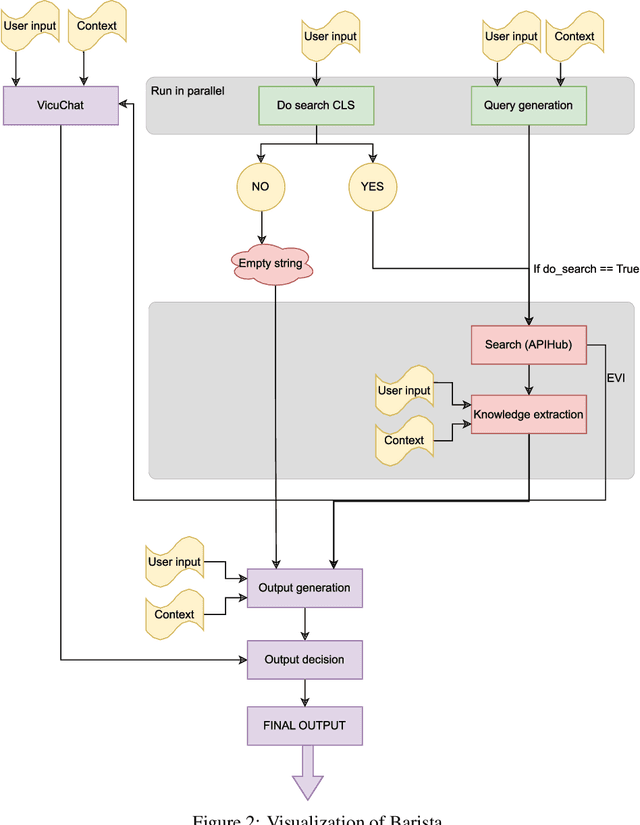
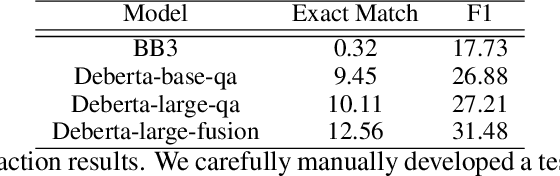
We present our SocialBot -- Alquist~5.0 -- developed for the Alexa Prize SocialBot Grand Challenge~5. Building upon previous versions of our system, we introduce the NRG Barista and outline several innovative approaches for integrating Barista into our SocialBot, improving the overall conversational experience. Additionally, we extend our SocialBot to support multimodal devices. This paper offers insights into the development of Alquist~5.0, which meets evolving user expectations while maintaining empathetic and knowledgeable conversational abilities across diverse topics.
Flowstorm: Open-Source Platform with Hybrid Dialogue Architecture
Dec 19, 2022



This paper presents a conversational AI platform called Flowstorm. Flowstorm is an open-source SaaS project suitable for creating, running, and analyzing conversational applications. Thanks to the fast and fully automated build process, the dialogues created within the platform can be executed in seconds. Furthermore, we propose a novel dialogue architecture that uses a combination of tree structures with generative models. The tree structures are also used for training NLU models suitable for specific dialogue scenarios. However, the generative models are globally used across applications and extend the functionality of the dialogue trees. Moreover, the platform functionality benefits from out-of-the-box components, such as the one responsible for extracting data from utterances or working with crawled data. Additionally, it can be extended using a custom code directly in the platform. One of the essential features of the platform is the possibility to reuse the created assets across applications. There is a library of prepared assets where each developer can contribute. All of the features are available through a user-friendly visual editor.
Metric Learning and Adaptive Boundary for Out-of-Domain Detection
Apr 22, 2022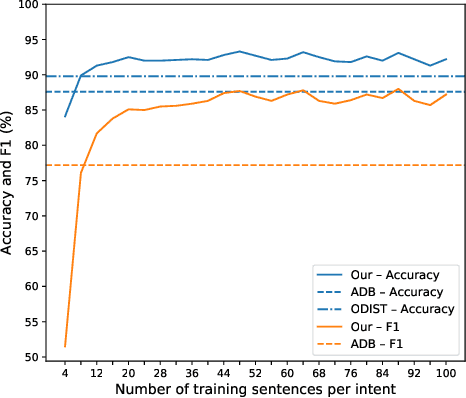
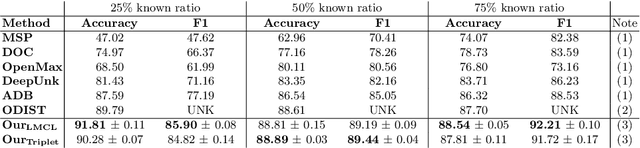
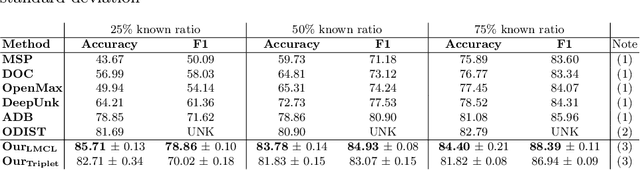
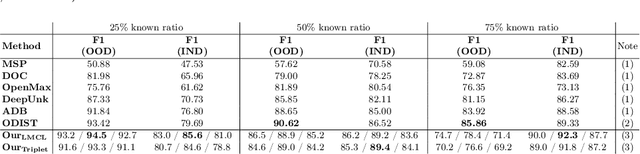
Conversational agents are usually designed for closed-world environments. Unfortunately, users can behave unexpectedly. Based on the open-world environment, we often encounter the situation that the training and test data are sampled from different distributions. Then, data from different distributions are called out-of-domain (OOD). A robust conversational agent needs to react to these OOD utterances adequately. Thus, the importance of robust OOD detection is emphasized. Unfortunately, collecting OOD data is a challenging task. We have designed an OOD detection algorithm independent of OOD data that outperforms a wide range of current state-of-the-art algorithms on publicly available datasets. Our algorithm is based on a simple but efficient approach of combining metric learning with adaptive decision boundary. Furthermore, compared to other algorithms, we have found that our proposed algorithm has significantly improved OOD performance in a scenario with a lower number of classes while preserving the accuracy for in-domain (IND) classes.
Alquist 4.0: Towards Social Intelligence Using Generative Models and Dialogue Personalization
Sep 16, 2021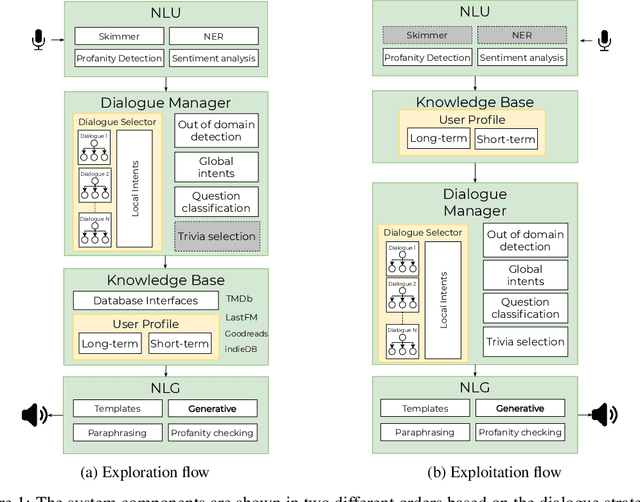
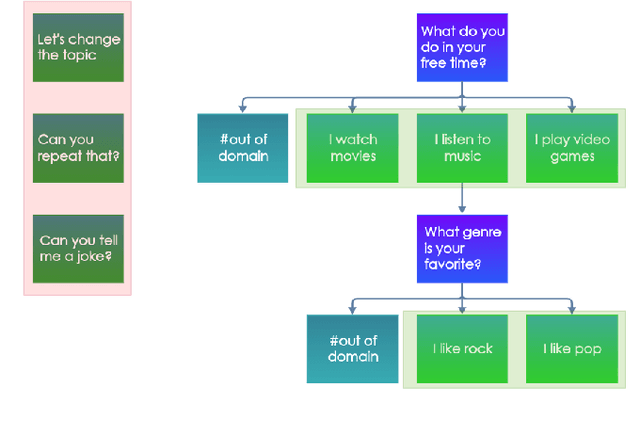
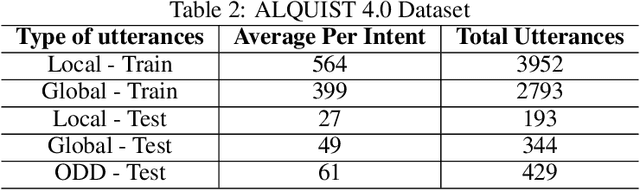
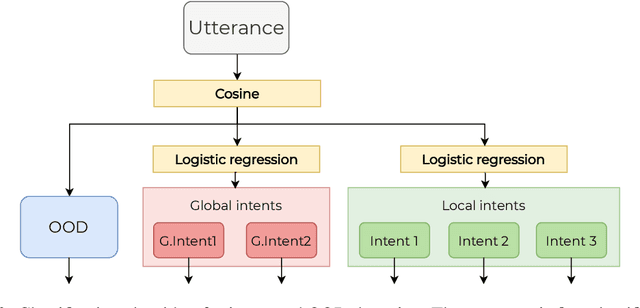
The open domain-dialogue system Alquist has a goal to conduct a coherent and engaging conversation that can be considered as one of the benchmarks of social intelligence. The fourth version of the system, developed within the Alexa Prize Socialbot Grand Challenge 4, brings two main innovations. The first addresses coherence, and the second addresses the engagingness of the conversation. For innovations regarding coherence, we propose a novel hybrid approach combining hand-designed responses and a generative model. The proposed approach utilizes hand-designed dialogues, out-of-domain detection, and a neural response generator. Hand-designed dialogues walk the user through high-quality conversational flows. The out-of-domain detection recognizes that the user diverges from the predefined flow and prevents the system from producing a scripted response that might not make sense for unexpected user input. Finally, the neural response generator generates a response based on the context of the dialogue that correctly reacts to the unexpected user input and returns the dialogue to the boundaries of hand-designed dialogues. The innovations for engagement that we propose are mostly inspired by the famous exploration-exploitation dilemma. To conduct an engaging conversation with the dialogue partners, one has to learn their preferences and interests -- exploration. Moreover, to engage the partner, we have to utilize the knowledge we have already learned -- exploitation. In this work, we present the principles and inner workings of individual components of the open-domain dialogue system Alquist developed within the Alexa Prize Socialbot Grand Challenge 4 and the experiments we have conducted to evaluate them.
Text Summarization of Czech News Articles Using Named Entities
Apr 21, 2021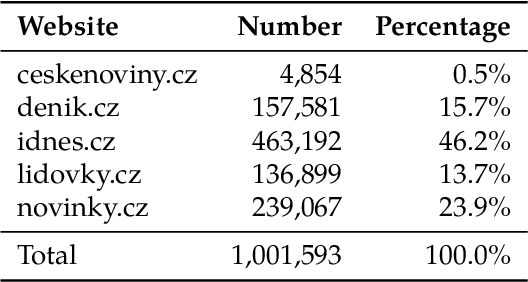
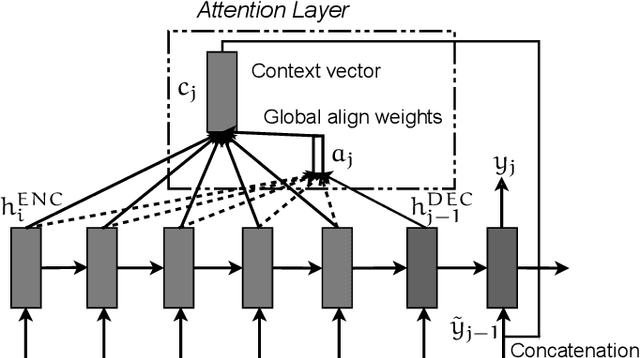
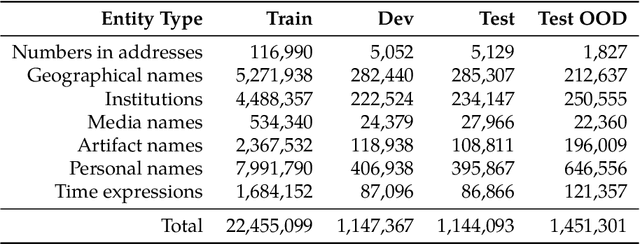
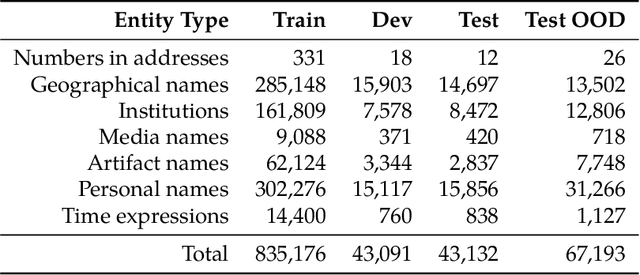
The foundation for the research of summarization in the Czech language was laid by the work of Straka et al. (2018). They published the SumeCzech, a large Czech news-based summarization dataset, and proposed several baseline approaches. However, it is clear from the achieved results that there is a large space for improvement. In our work, we focus on the impact of named entities on the summarization of Czech news articles. First, we annotate SumeCzech with named entities. We propose a new metric ROUGE_NE that measures the overlap of named entities between the true and generated summaries, and we show that it is still challenging for summarization systems to reach a high score in it. We propose an extractive summarization approach Named Entity Density that selects a sentence with the highest ratio between a number of entities and the length of the sentence as the summary of the article. The experiments show that the proposed approach reached results close to the solid baseline in the domain of news articles selecting the first sentence. Moreover, we demonstrate that the selected sentence reflects the style of reports concisely identifying to whom, when, where, and what happened. We propose that such a summary is beneficial in combination with the first sentence of an article in voice applications presenting news articles. We propose two abstractive summarization approaches based on Seq2Seq architecture. The first approach uses the tokens of the article. The second approach has access to the named entity annotations. The experiments show that both approaches exceed state-of-the-art results previously reported by Straka et al. (2018), with the latter achieving slightly better results on SumeCzech's out-of-domain testing set.
OodGAN: Generative Adversarial Network for Out-of-Domain Data Generation
Apr 06, 2021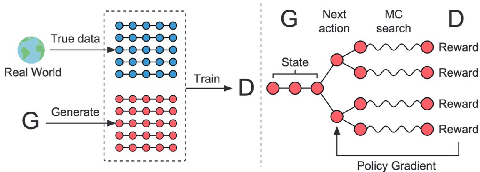
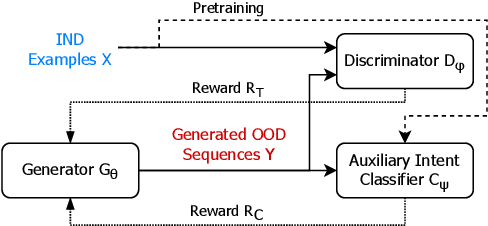
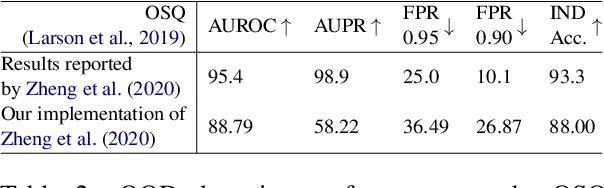
Detecting an Out-of-Domain (OOD) utterance is crucial for a robust dialog system. Most dialog systems are trained on a pool of annotated OOD data to achieve this goal. However, collecting the annotated OOD data for a given domain is an expensive process. To mitigate this issue, previous works have proposed generative adversarial networks (GAN) based models to generate OOD data for a given domain automatically. However, these proposed models do not work directly with the text. They work with the text's latent space instead, enforcing these models to include components responsible for encoding text into latent space and decoding it back, such as auto-encoder. These components increase the model complexity, making it difficult to train. We propose OodGAN, a sequential generative adversarial network (SeqGAN) based model for OOD data generation. Our proposed model works directly on the text and hence eliminates the need to include an auto-encoder. OOD data generated using OodGAN model outperforms state-of-the-art in OOD detection metrics for ROSTD (67% relative improvement in FPR 0.95) and OSQ datasets (28% relative improvement in FPR 0.95) (Zheng et al., 2020).
Do We Need Online NLU Tools?
Nov 19, 2020

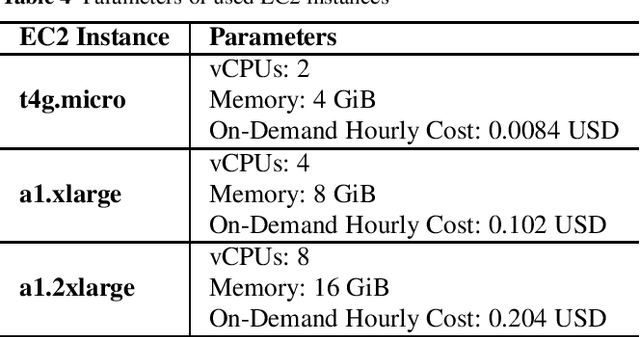
The intent recognition is an essential algorithm of any conversational AI application. It is responsible for the classification of an input message into meaningful classes. In many bot development platforms, we can configure the NLU pipeline. Several intent recognition services are currently available as an API, or we choose from many open-source alternatives. However, there is no comparison of intent recognition services and open-source algorithms. Many factors make the selection of the right approach to the intent recognition challenging in practice. In this paper, we suggest criteria to choose the best intent recognition algorithm for an application. We present a dataset for evaluation. Finally, we compare selected public NLU services with selected open-source algorithms for intent recognition.
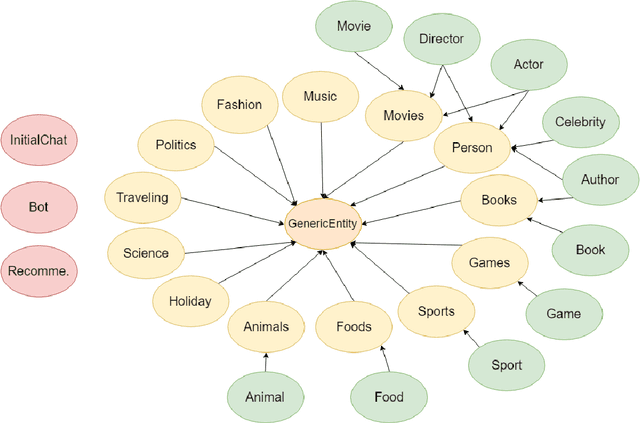
Alquist 3.0: Alexa Prize Bot Using Conversational Knowledge Graph
Nov 06, 2020
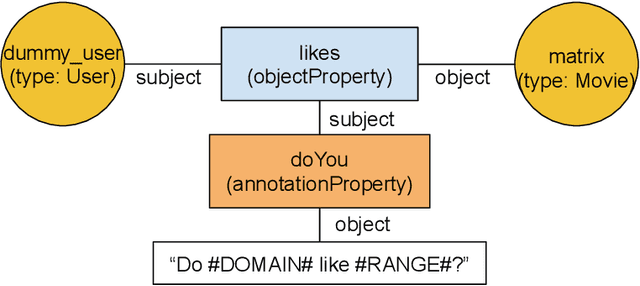
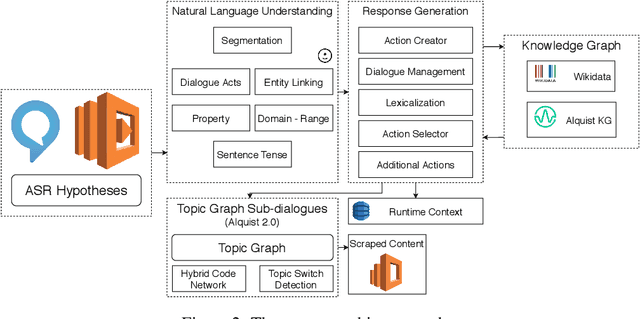

The third version of the open-domain dialogue system Alquist developed within the Alexa Prize 2020 competition is designed to conduct coherent and engaging conversations on popular topics. The main novel contribution is the introduction of a system leveraging an innovative approach based on a conversational knowledge graph and adjacency pairs. The conversational knowledge graph allows the system to utilize knowledge expressed during the dialogue in consequent turns and across conversations. Dialogue adjacency pairs divide the conversation into small conversational structures, which can be combined and allow the system to react to a wide range of user inputs flexibly. We discuss and describe Alquist's pipeline, data acquisition and processing, dialogue manager, NLG, knowledge aggregation, and a hierarchy of adjacency pairs. We present the experimental results of the individual parts of the system.
Alquist 2.0: Alexa Prize Socialbot Based on Sub-Dialogue Models
Nov 06, 2020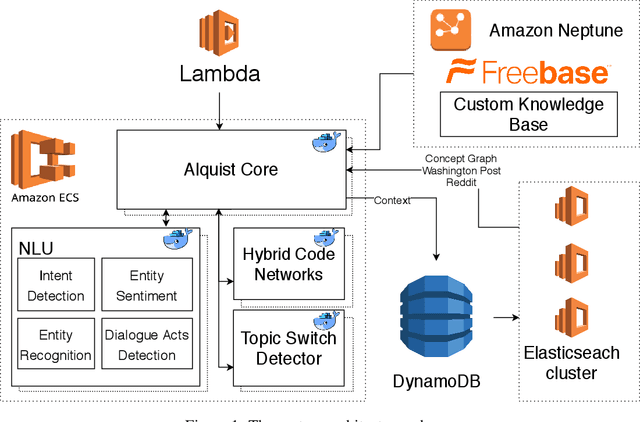
This paper presents the second version of the dialogue system named Alquist competing in Amazon Alexa Prize 2018. We introduce a system leveraging ontology-based topic structure called topic nodes. Each of the nodes consists of several sub-dialogues, and each sub-dialogue has its own LSTM-based model for dialogue management. The sub-dialogues can be triggered according to the topic hierarchy or a user intent which allows the bot to create a unique experience during each session.
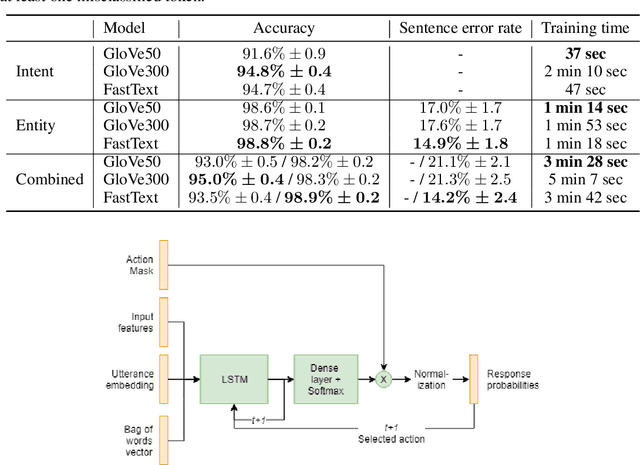
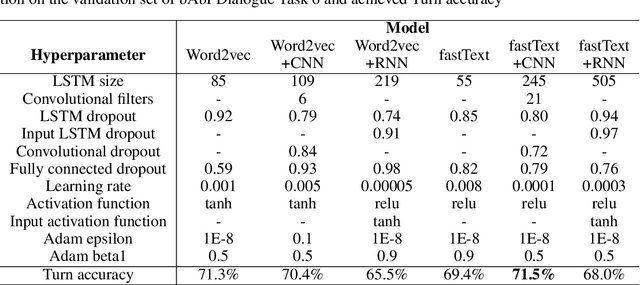
Hybrid Code Networks using a convolutional neural network as an input layer achieves higher turn accuracy
Jul 28, 2019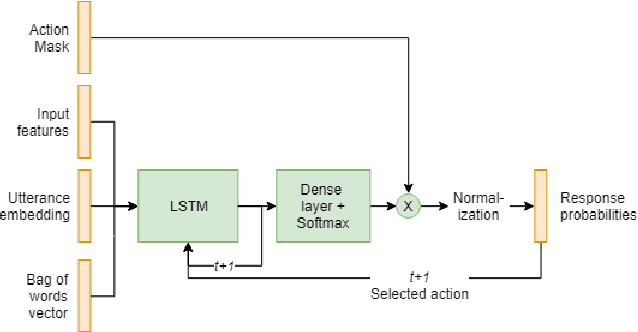
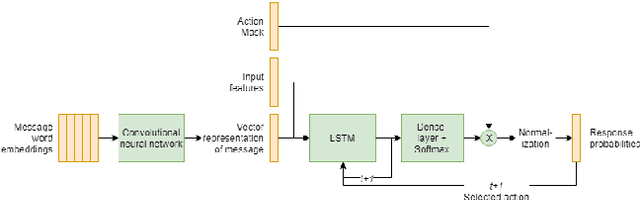
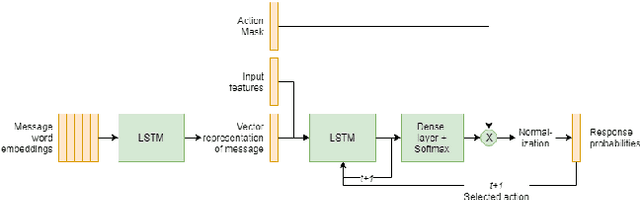
The dialogue management is a task of conversational artificial intelligence. The goal of the dialogue manager is to select the appropriate response to the conversational partner conditioned by the input message and recent dialogue state. Hybrid Code Networks is one of the models of dialogue managers, which uses an average of word embeddings and bag-of-words as input features. We perform experiments on Dialogue bAbI Task 6 and Alquist Conversational Dataset. The experiments show that the convolutional neural network used as an input layer of the Hybrid Code Network improves the model's turn accuracy.