 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Summarization of Czech News Articles Using Named Entities
Paper and Code
Apr 21, 2021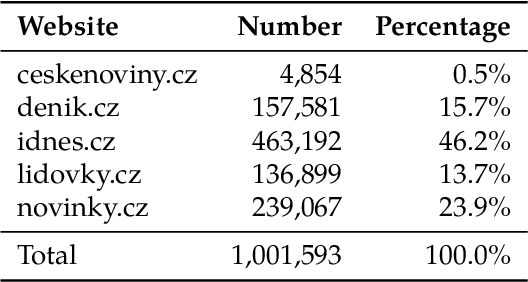
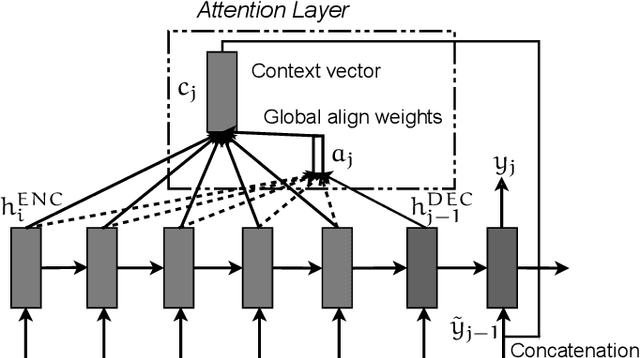
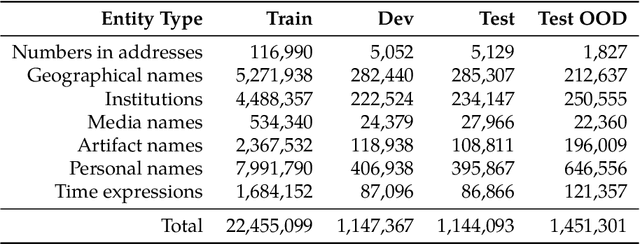
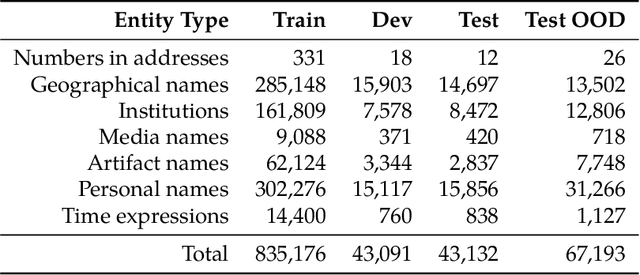
The foundation for the research of summarization in the Czech language was laid by the work of Straka et al. (2018). They published the SumeCzech, a large Czech news-based summarization dataset, and proposed several baseline approaches. However, it is clear from the achieved results that there is a large space for improvement. In our work, we focus on the impact of named entities on the summarization of Czech news articles. First, we annotate SumeCzech with named entities. We propose a new metric ROUGE_NE that measures the overlap of named entities between the true and generated summaries, and we show that it is still challenging for summarization systems to reach a high score in it. We propose an extractive summarization approach Named Entity Density that selects a sentence with the highest ratio between a number of entities and the length of the sentence as the summary of the article. The experiments show that the proposed approach reached results close to the solid baseline in the domain of news articles selecting the first sentence. Moreover, we demonstrate that the selected sentence reflects the style of reports concisely identifying to whom, when, where, and what happened. We propose that such a summary is beneficial in combination with the first sentence of an article in voice applications presenting news articles. We propose two abstractive summarization approaches based on Seq2Seq architecture. The first approach uses the tokens of the article. The second approach has access to the named entity annotations. The experiments show that both approaches exceed state-of-the-art results previously reported by Straka et al. (2018), with the latter achieving slightly better results on SumeCzech's out-of-domain testing set.