 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Reasoning in the Embedding Space
Apr 02, 2025
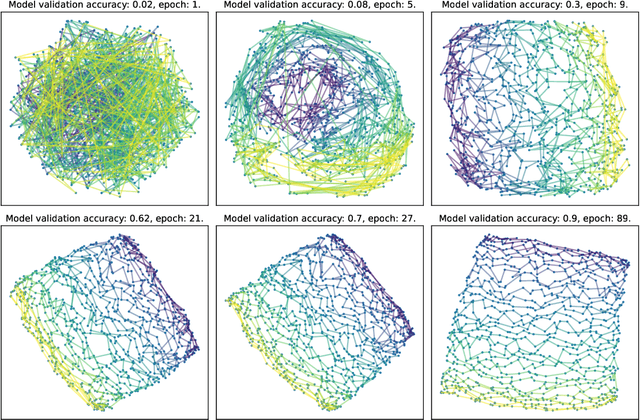
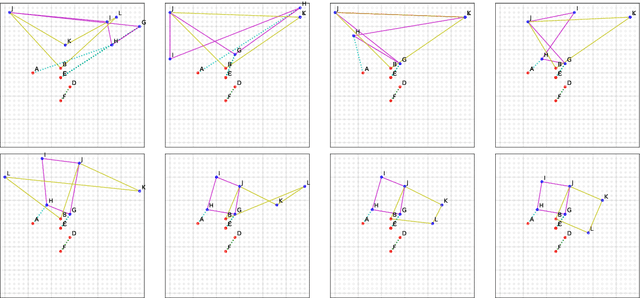
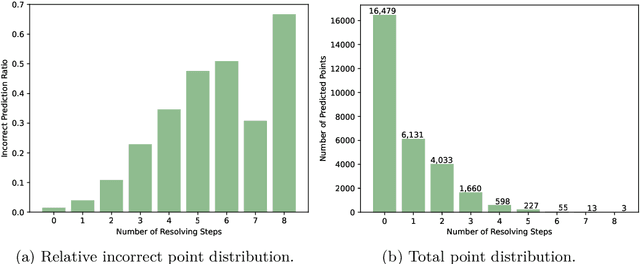
In this contribution, we demonstrate that Graph Neural Networks and Transformers can learn to reason about geometric constraints. We train them to predict spatial position of points in a discrete 2D grid from a set of constraints that uniquely describe hidden figures containing these points. Both models are able to predict the position of points and interestingly, they form the hidden figures described by the input constraints in the embedding space during the reasoning process. Our analysis shows that both models recover the grid structure during training so that the embeddings corresponding to the points within the grid organize themselves in a 2D subspace and reflect the neighborhood structure of the grid. We also show that the Graph Neural Network we design for the task performs significantly better than the Transformer and is also easier to scale.
Rethinking Thinking Tokens: Understanding Why They Underperform in Practice
Nov 18, 2024Thinking Tokens (TT) have been proposed as an unsupervised method to facilitate reasoning in language models. However, despite their conceptual appeal, our findings show that TTs marginally improves performance and consistently underperforms compared to Chain-of-Thought (CoT) reasoning across multiple benchmarks. We hypothesize that this underperformance stems from the reliance on a single embedding for TTs, which results in inconsistent learning signals and introduces noisy gradients. This paper provides a comprehensive empirical analysis to validate this hypothesis and discusses the implications for future research on unsupervised reasoning in LLMs.
Thinking Tokens for Language Modeling
May 14, 2024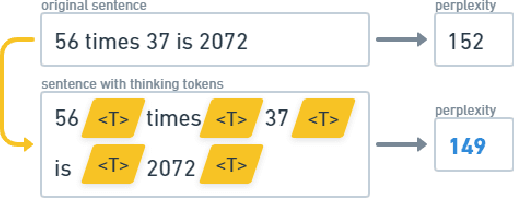

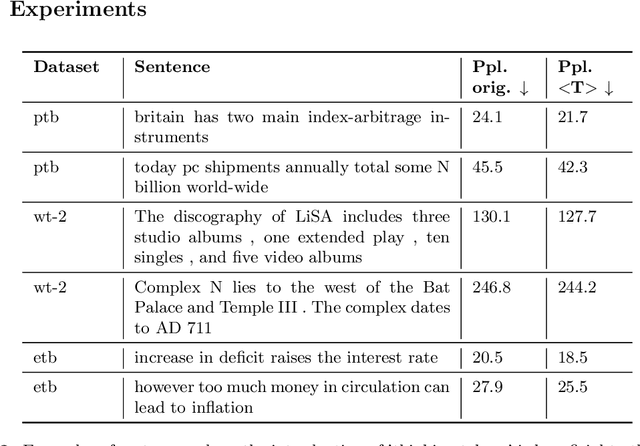
How much is 56 times 37? Language models often make mistakes in these types of difficult calculations. This is usually explained by their inability to perform complex reasoning. Since language models rely on large training sets and great memorization capability, naturally they are not equipped to run complex calculations. However, one can argue that humans also cannot perform this calculation immediately and require a considerable amount of time to construct the solution. In order to enhance the generalization capability of language models, and as a parallel to human behavior, we propose to use special 'thinking tokens' which allow the model to perform much more calculations whenever a complex problem is encountered.
Collapse of Self-trained Language Models
Apr 02, 2024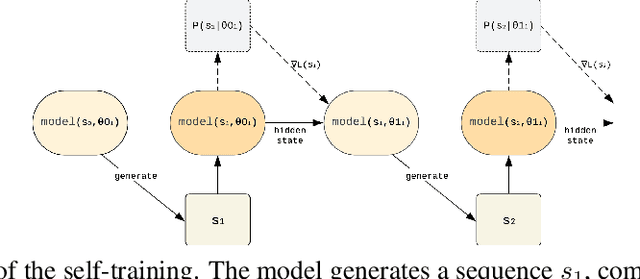

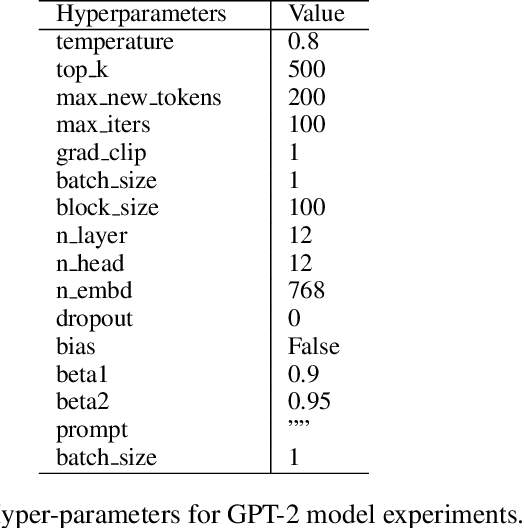
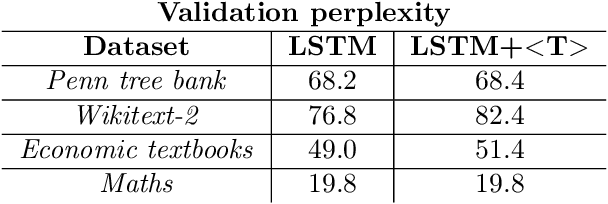
In various fields of knowledge creation, including science, new ideas often build on pre-existing information. In this work, we explore this concept within the context of language models. Specifically, we explore the potential of self-training models on their own outputs, akin to how humans learn and build on their previous thoughts and actions. While this approach is intuitively appealing, our research reveals its practical limitations. We find that extended self-training of the GPT-2 model leads to a significant degradation in performance, resulting in repetitive and collapsed token output.
On Difficulties of Attention Factorization through Shared Memory
Mar 31, 2024



Transformers have revolutionized deep learning in numerous fields, including natural language processing, computer vision, and audio processing. Their strength lies in their attention mechanism, which allows for the discovering of complex input relationships. However, this mechanism's quadratic time and memory complexity pose challenges for larger inputs. Researchers are now investigating models like Linear Unified Nested Attention (Luna) or Memory Augmented Transformer, which leverage external learnable memory to either reduce the attention computation complexity down to linear, or to propagate information between chunks in chunk-wise processing. Our findings challenge the conventional thinking on these models, revealing that interfacing with the memory directly through an attention operation is suboptimal, and that the performance may be considerably improved by filtering the input signal before communicating with memory.
Advancing State of the Art in Language Modeling
Nov 28, 2023Generalization is arguably the most important goal of statistical language modeling research. Publicly available benchmarks and papers published with an open-source code have been critical to advancing the field. However, it is often very difficult, and sometimes even impossible, to reproduce the results fully as reported in publications. In this paper, we propose a simple framework that should help advance the state of the art in language modeling in terms of generalization. We propose to publish not just the code, but also probabilities on dev and test sets with future publications so that one can easily add the new model into an ensemble. This has crucial advantages: it is much easier to determine whether a newly proposed model is actually complementary to the current baseline. Therefore, instead of inventing new names for the old tricks, the scientific community can advance faster. Finally, this approach promotes diversity of ideas: one does not need to create an individual model that is the new state of the art to attract attention; it will be sufficient to develop a new model that learns patterns which other models do not. Thus, even a suboptimal model can be found to have value. Remarkably, our approach has yielded new state-of-the-art results across various language modeling benchmarks up to 10%.
Alquist 5.0: Dialogue Trees Meet Generative Models. A Novel Approach for Enhancing SocialBot Conversations
Oct 24, 2023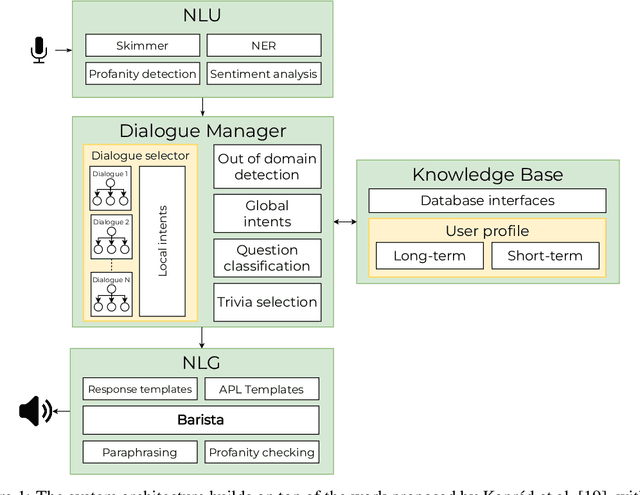

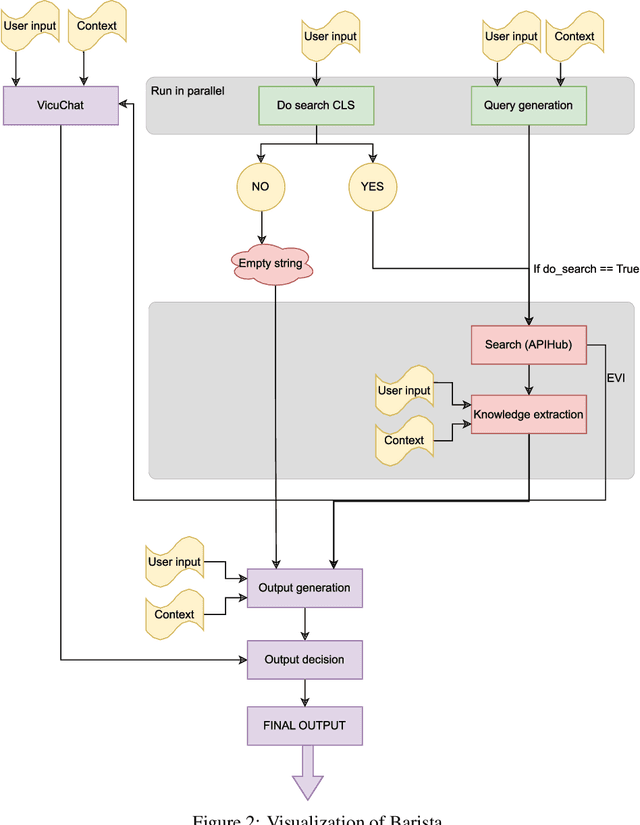
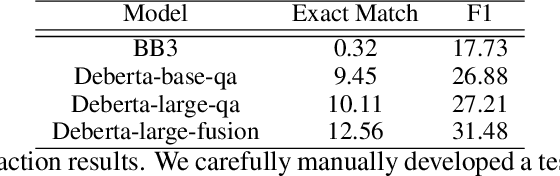
We present our SocialBot -- Alquist~5.0 -- developed for the Alexa Prize SocialBot Grand Challenge~5. Building upon previous versions of our system, we introduce the NRG Barista and outline several innovative approaches for integrating Barista into our SocialBot, improving the overall conversational experience. Additionally, we extend our SocialBot to support multimodal devices. This paper offers insights into the development of Alquist~5.0, which meets evolving user expectations while maintaining empathetic and knowledgeable conversational abilities across diverse topics.
Preserving Semantics in Textual Adversarial Attacks
Nov 08, 2022Adversarial attacks in NLP challenge the way we look at language models. The goal of this kind of adversarial attack is to modify the input text to fool a classifier while maintaining the original meaning of the text. Although most existing adversarial attacks claim to fulfill the constraint of semantics preservation, careful scrutiny shows otherwise. We show that the problem lies in the text encoders used to determine the similarity of adversarial examples, specifically in the way they are trained. Unsupervised training methods make these encoders more susceptible to problems with antonym recognition. To overcome this, we introduce a simple, fully supervised sentence embedding technique called Semantics-Preserving-Encoder (SPE). The results show that our solution minimizes the variation in the meaning of the adversarial examples generated. It also significantly improves the overall quality of adversarial examples, as confirmed by human evaluators. Furthermore, it can be used as a component in any existing attack to speed up its execution while maintaining similar attack success.