 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning in Complex Systems
Jul 11, 2023In this thesis, we explore the use of complex systems to study learning and adaptation in natural and artificial systems. The goal is to develop autonomous systems that can learn without supervision, develop on their own, and become increasingly complex over time. Complex systems are identified as a suitable framework for understanding these phenomena due to their ability to exhibit growth of complexity. Being able to build learning algorithms that require limited to no supervision would enable greater flexibility and adaptability in various applications. By understanding the fundamental principles of learning in complex systems, we hope to advance our ability to design and implement practical learning algorithms in the future. This thesis makes the following key contributions: the development of a general complexity metric that we apply to search for complex systems that exhibit growth of complexity, the introduction of a coarse-graining method to study computations in large-scale complex systems, and the development of a metric for learning efficiency as well as a benchmark dataset for evaluating the speed of learning algorithms. Our findings add substantially to our understanding of learning and adaptation in natural and artificial systems. Moreover, our approach contributes to a promising new direction for research in this area. We hope these findings will inspire the development of more effective and efficient learning algorithms in the future.
Preserving Semantics in Textual Adversarial Attacks
Nov 08, 2022Adversarial attacks in NLP challenge the way we look at language models. The goal of this kind of adversarial attack is to modify the input text to fool a classifier while maintaining the original meaning of the text. Although most existing adversarial attacks claim to fulfill the constraint of semantics preservation, careful scrutiny shows otherwise. We show that the problem lies in the text encoders used to determine the similarity of adversarial examples, specifically in the way they are trained. Unsupervised training methods make these encoders more susceptible to problems with antonym recognition. To overcome this, we introduce a simple, fully supervised sentence embedding technique called Semantics-Preserving-Encoder (SPE). The results show that our solution minimizes the variation in the meaning of the adversarial examples generated. It also significantly improves the overall quality of adversarial examples, as confirmed by human evaluators. Furthermore, it can be used as a component in any existing attack to speed up its execution while maintaining similar attack success.
Benchmarking Learning Efficiency in Deep Reservoir Computing
Sep 29, 2022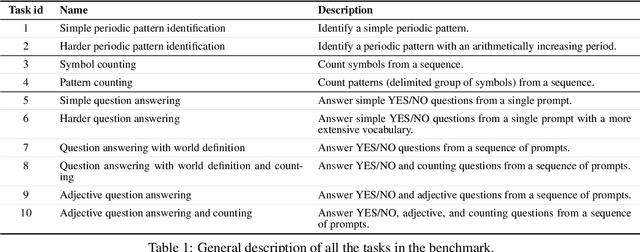


It is common to evaluate the performance of a machine learning model by measuring its predictive power on a test dataset. This approach favors complicated models that can smoothly fit complex functions and generalize well from training data points. Although essential components of intelligence, speed and data efficiency of this learning process are rarely reported or compared between different candidate models. In this paper, we introduce a benchmark of increasingly difficult tasks together with a data efficiency metric to measure how quickly machine learning models learn from training data. We compare the learning speed of some established sequential supervised models, such as RNNs, LSTMs, or Transformers, with relatively less known alternative models based on reservoir computing. The proposed tasks require a wide range of computational primitives, such as memory or the ability to compute Boolean functions, to be effectively solved. Surprisingly, we observe that reservoir computing systems that rely on dynamically evolving feature maps learn faster than fully supervised methods trained with stochastic gradient optimization while achieving comparable accuracy scores. The code, benchmark, trained models, and results to reproduce our experiments are available at https://github.com/hugcis/benchmark_learning_efficiency/ .
Visualizing computation in large-scale cellular automata
Apr 01, 2021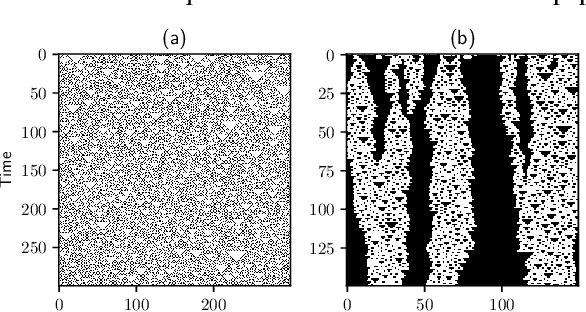
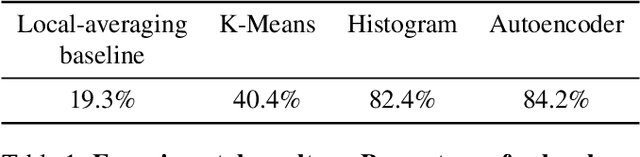
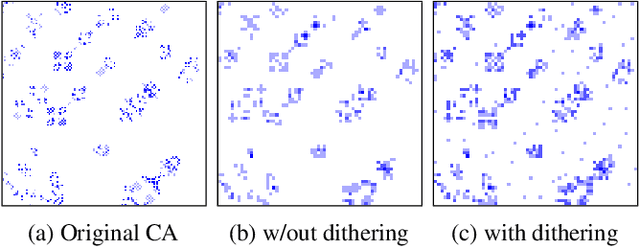
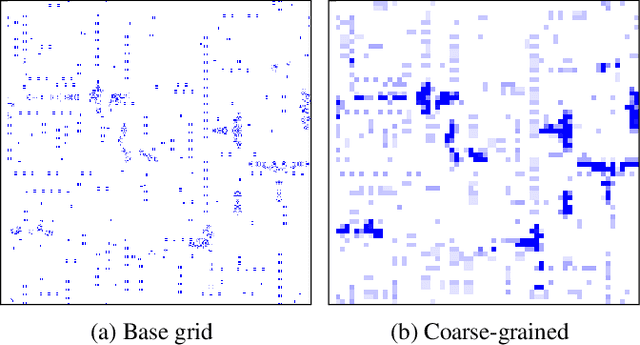
Emergent processes in complex systems such as cellular automata can perform computations of increasing complexity, and could possibly lead to artificial evolution. Such a feat would require scaling up current simulation sizes to allow for enough computational capacity. Understanding complex computations happening in cellular automata and other systems capable of emergence poses many challenges, especially in large-scale systems. We propose methods for coarse-graining cellular automata based on frequency analysis of cell states, clustering and autoencoders. These innovative techniques facilitate the discovery of large-scale structure formation and complexity analysis in those systems. They emphasize interesting behaviors in elementary cellular automata while filtering out background patterns. Moreover, our methods reduce large 2D automata to smaller sizes and enable identifying systems that behave interestingly at multiple scales.
Evolving Structures in Complex Systems
Nov 04, 2019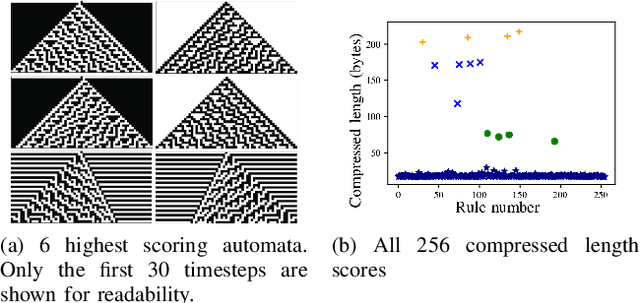



In this paper we propose an approach for measuring growth of complexity of emerging patterns in complex systems such as cellular automata. We discuss several ways how a metric for measuring the complexity growth can be defined. This includes approaches based on compression algorithms and artificial neural networks. We believe such a metric can be useful for designing systems that could exhibit open-ended evolution, which itself might be a prerequisite for development of general artificial intelligence. We conduct experiments on 1D and 2D grid worlds and demonstrate that using the proposed metric we can automatically construct computational models with emerging properties similar to those found in the Conway's Game of Life, as well as many other emergent phenomena. Interestingly, some of the patterns we observe resemble forms of artificial life. Our metric of structural complexity growth can be applied to a wide range of complex systems, as it is not limited to cellular automata.
* IEEE Symposium Series on Computational Intelligence 2019 (IEEE SSCI 2019)
Hybrid Approaches for our Participation to the n2c2 Challenge on Cohort Selection for Clinical Trials
Mar 19, 2019

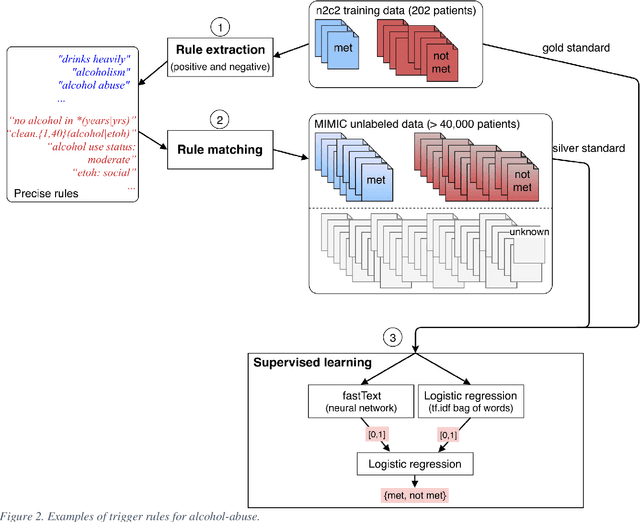
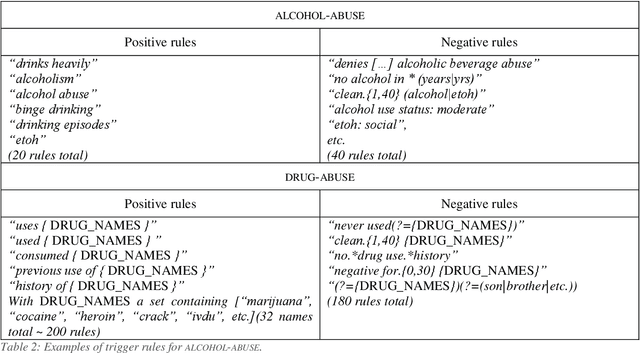
Objective: Natural language processing can help minimize human intervention in identifying patients meeting eligibility criteria for clinical trials, but there is still a long way to go to obtain a general and systematic approach that is useful for researchers. We describe two methods taking a step in this direction and present their results obtained during the n2c2 challenge on cohort selection for clinical trials. Materials and Methods: The first method is a weakly supervised method using an unlabeled corpus (MIMIC) to build a silver standard, by producing semi-automatically a small and very precise set of rules to detect some samples of positive and negative patients. This silver standard is then used to train a traditional supervised model. The second method is a terminology-based approach where a medical expert selects the appropriate concepts, and a procedure is defined to search the terms and check the structural or temporal constraints. Results: On the n2c2 dataset containing annotated data about 13 selection criteria on 288 patients, we obtained an overall F1-measure of 0.8969, which is the third best result out of 45 participant teams, with no statistically significant difference with the best-ranked team. Discussion: Both approaches obtained very encouraging results and apply to different types of criteria. The weakly supervised method requires explicit descriptions of positive and negative examples in some reports. The terminology-based method is very efficient when medical concepts carry most of the relevant information. Conclusion: It is unlikely that much more annotated data will be soon available for the task of identifying a wide range of patient phenotypes. One must focus on weakly or non-supervised learning methods using both structured and unstructured data and relying on a comprehensive representation of the patients.