 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Tokens for Language Modeling
May 14, 2024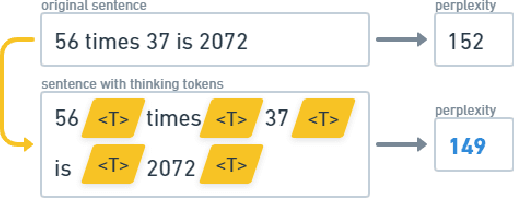

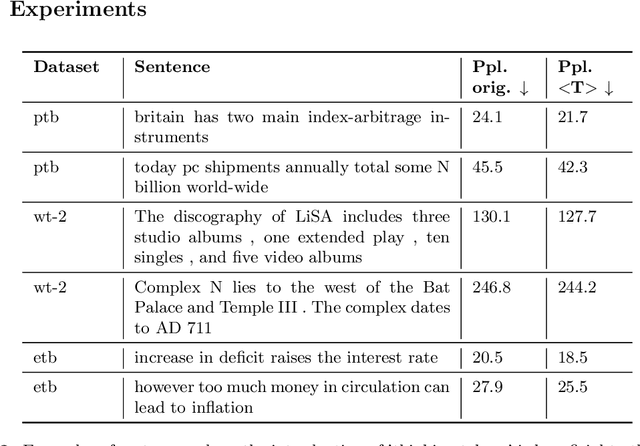
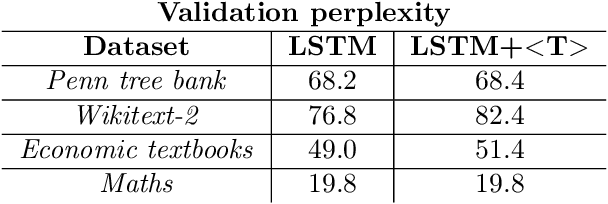
How much is 56 times 37? Language models often make mistakes in these types of difficult calculations. This is usually explained by their inability to perform complex reasoning. Since language models rely on large training sets and great memorization capability, naturally they are not equipped to run complex calculations. However, one can argue that humans also cannot perform this calculation immediately and require a considerable amount of time to construct the solution. In order to enhance the generalization capability of language models, and as a parallel to human behavior, we propose to use special 'thinking tokens' which allow the model to perform much more calculations whenever a complex problem is encountered.
Collapse of Self-trained Language Models
Apr 02, 2024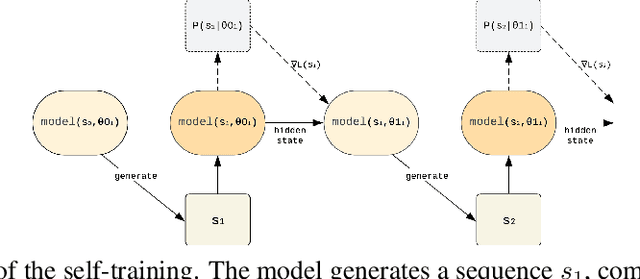

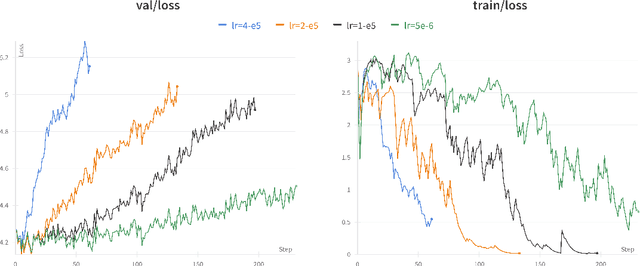
In various fields of knowledge creation, including science, new ideas often build on pre-existing information. In this work, we explore this concept within the context of language models. Specifically, we explore the potential of self-training models on their own outputs, akin to how humans learn and build on their previous thoughts and actions. While this approach is intuitively appealing, our research reveals its practical limitations. We find that extended self-training of the GPT-2 model leads to a significant degradation in performance, resulting in repetitive and collapsed token output.
Large Language Models: A Survey
Feb 20, 2024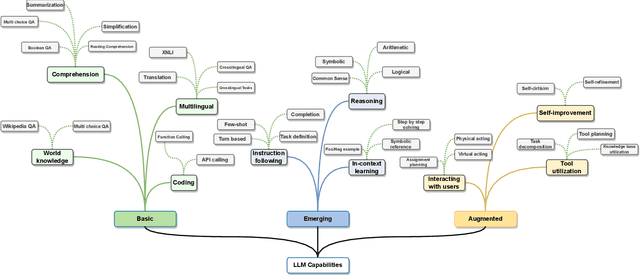
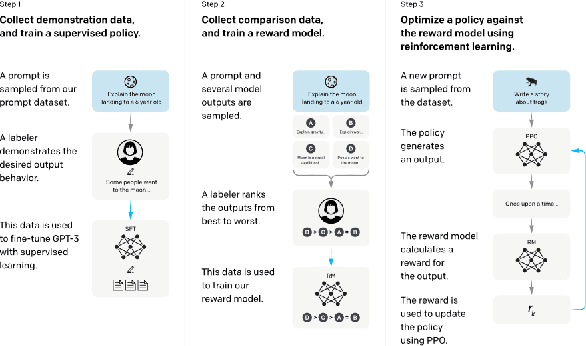
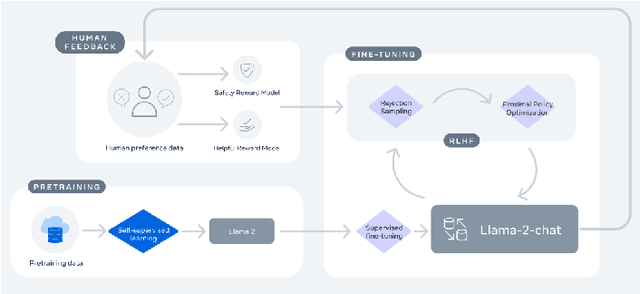
Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs' ability of general-purpose language understanding and generation is acquired by training billions of model's parameters on massive amounts of text data, as predicted by scaling laws \cite{kaplan2020scaling,hoffmann2022training}. The research area of LLMs, while very recent, is evolving rapidly in many different ways. In this paper, we review some of the most prominent LLMs, including three popular LLM families (GPT, LLaMA, PaLM), and discuss their characteristics, contributions and limitations. We also give an overview of techniques developed to build, and augment LLMs. We then survey popular datasets prepared for LLM training, fine-tuning, and evaluation, review widely used LLM evaluation metrics, and compare the performance of several popular LLMs on a set of representative benchmarks. Finally, we conclude the paper by discussing open challenges and future research directions.
Advancing State of the Art in Language Modeling
Nov 28, 2023Generalization is arguably the most important goal of statistical language modeling research. Publicly available benchmarks and papers published with an open-source code have been critical to advancing the field. However, it is often very difficult, and sometimes even impossible, to reproduce the results fully as reported in publications. In this paper, we propose a simple framework that should help advance the state of the art in language modeling in terms of generalization. We propose to publish not just the code, but also probabilities on dev and test sets with future publications so that one can easily add the new model into an ensemble. This has crucial advantages: it is much easier to determine whether a newly proposed model is actually complementary to the current baseline. Therefore, instead of inventing new names for the old tricks, the scientific community can advance faster. Finally, this approach promotes diversity of ideas: one does not need to create an individual model that is the new state of the art to attract attention; it will be sufficient to develop a new model that learns patterns which other models do not. Thus, even a suboptimal model can be found to have value. Remarkably, our approach has yielded new state-of-the-art results across various language modeling benchmarks up to 10%.
Preserving Semantics in Textual Adversarial Attacks
Nov 08, 2022Adversarial attacks in NLP challenge the way we look at language models. The goal of this kind of adversarial attack is to modify the input text to fool a classifier while maintaining the original meaning of the text. Although most existing adversarial attacks claim to fulfill the constraint of semantics preservation, careful scrutiny shows otherwise. We show that the problem lies in the text encoders used to determine the similarity of adversarial examples, specifically in the way they are trained. Unsupervised training methods make these encoders more susceptible to problems with antonym recognition. To overcome this, we introduce a simple, fully supervised sentence embedding technique called Semantics-Preserving-Encoder (SPE). The results show that our solution minimizes the variation in the meaning of the adversarial examples generated. It also significantly improves the overall quality of adversarial examples, as confirmed by human evaluators. Furthermore, it can be used as a component in any existing attack to speed up its execution while maintaining similar attack success.
Benchmarking Learning Efficiency in Deep Reservoir Computing
Sep 29, 2022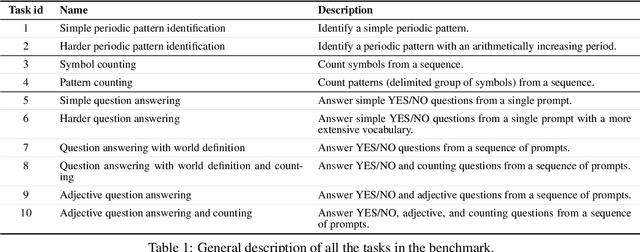

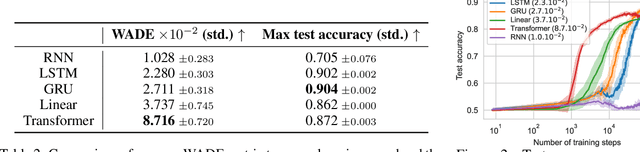

It is common to evaluate the performance of a machine learning model by measuring its predictive power on a test dataset. This approach favors complicated models that can smoothly fit complex functions and generalize well from training data points. Although essential components of intelligence, speed and data efficiency of this learning process are rarely reported or compared between different candidate models. In this paper, we introduce a benchmark of increasingly difficult tasks together with a data efficiency metric to measure how quickly machine learning models learn from training data. We compare the learning speed of some established sequential supervised models, such as RNNs, LSTMs, or Transformers, with relatively less known alternative models based on reservoir computing. The proposed tasks require a wide range of computational primitives, such as memory or the ability to compute Boolean functions, to be effectively solved. Surprisingly, we observe that reservoir computing systems that rely on dynamically evolving feature maps learn faster than fully supervised methods trained with stochastic gradient optimization while achieving comparable accuracy scores. The code, benchmark, trained models, and results to reproduce our experiments are available at https://github.com/hugcis/benchmark_learning_efficiency/ .
Visualizing computation in large-scale cellular automata
Apr 01, 2021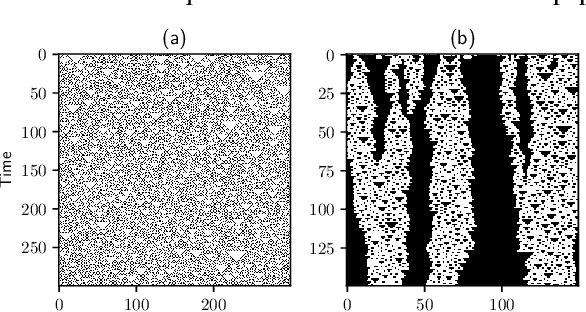
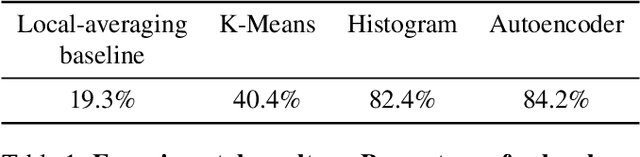
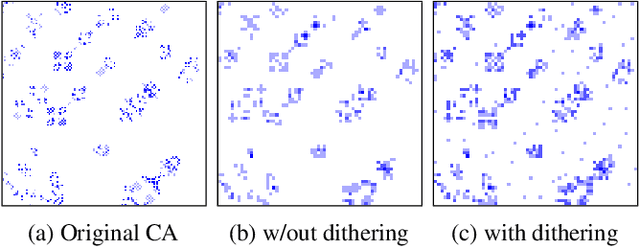
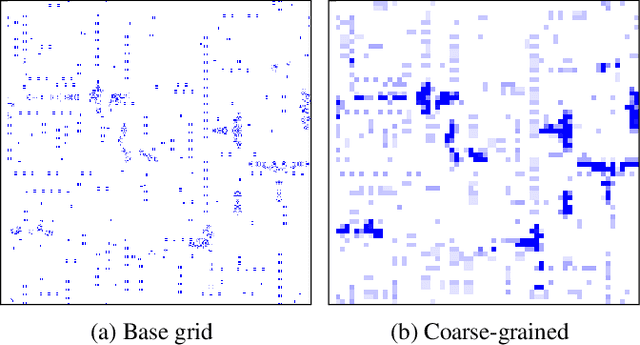
Emergent processes in complex systems such as cellular automata can perform computations of increasing complexity, and could possibly lead to artificial evolution. Such a feat would require scaling up current simulation sizes to allow for enough computational capacity. Understanding complex computations happening in cellular automata and other systems capable of emergence poses many challenges, especially in large-scale systems. We propose methods for coarse-graining cellular automata based on frequency analysis of cell states, clustering and autoencoders. These innovative techniques facilitate the discovery of large-scale structure formation and complexity analysis in those systems. They emphasize interesting behaviors in elementary cellular automata while filtering out background patterns. Moreover, our methods reduce large 2D automata to smaller sizes and enable identifying systems that behave interestingly at multiple scales.
Emergence of self-reproducing metabolisms as recursive algorithms in an Artificial Chemistry
Mar 15, 2021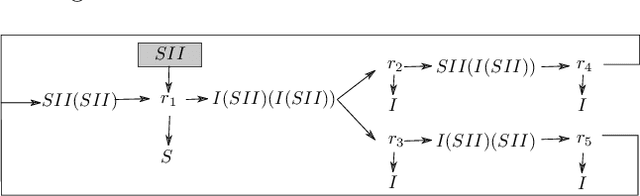
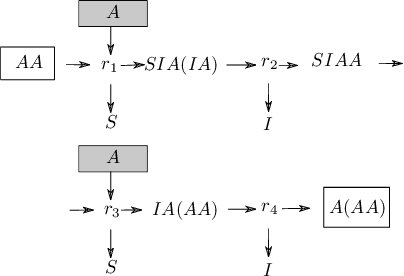
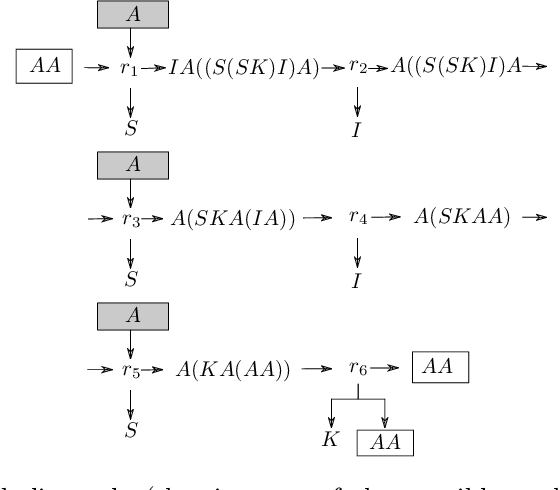
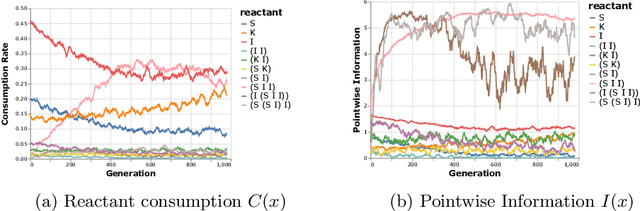
Researching the conditions for the emergence of life -- not necessarily as it is, but as it could be -- is one of the main goals of Artificial Life. Artificial Chemistries are one of the most important tools in this endeavour, as they allow us to investigate the process by which metabolisms capable of self-reproduction and -- ultimately -- of evolving, might have emerged. While previous work has shown promising results in this direction, it is still unclear which are the fundamental properties of a chemical system that enable emergent structures to arise. To this end, here we present an Artificial Chemistry based on Combinatory Logic, a Turing-complete rewriting system, which relies on a minimal set of possible reactions. Our experiments show that a single run of this chemistry starting from a tabula rasa state discovers with no external intervention a wide range of emergent structures, including autopoietic structures that maintain their organisation unchanged, others that grow recursively, and most notably, patterns that reproduce themselves, duplicating their number on each cycle. All of these structures take the form of recursive algorithms that acquire basic constituents from the environment and decompose them in a process that is remarkably similar to biological metabolisms.
Classification of Complex Systems Based on Transients
Aug 31, 2020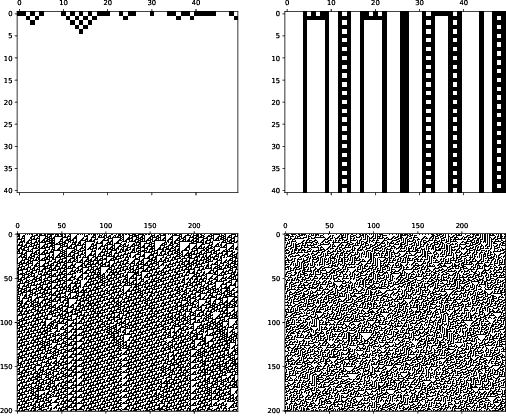
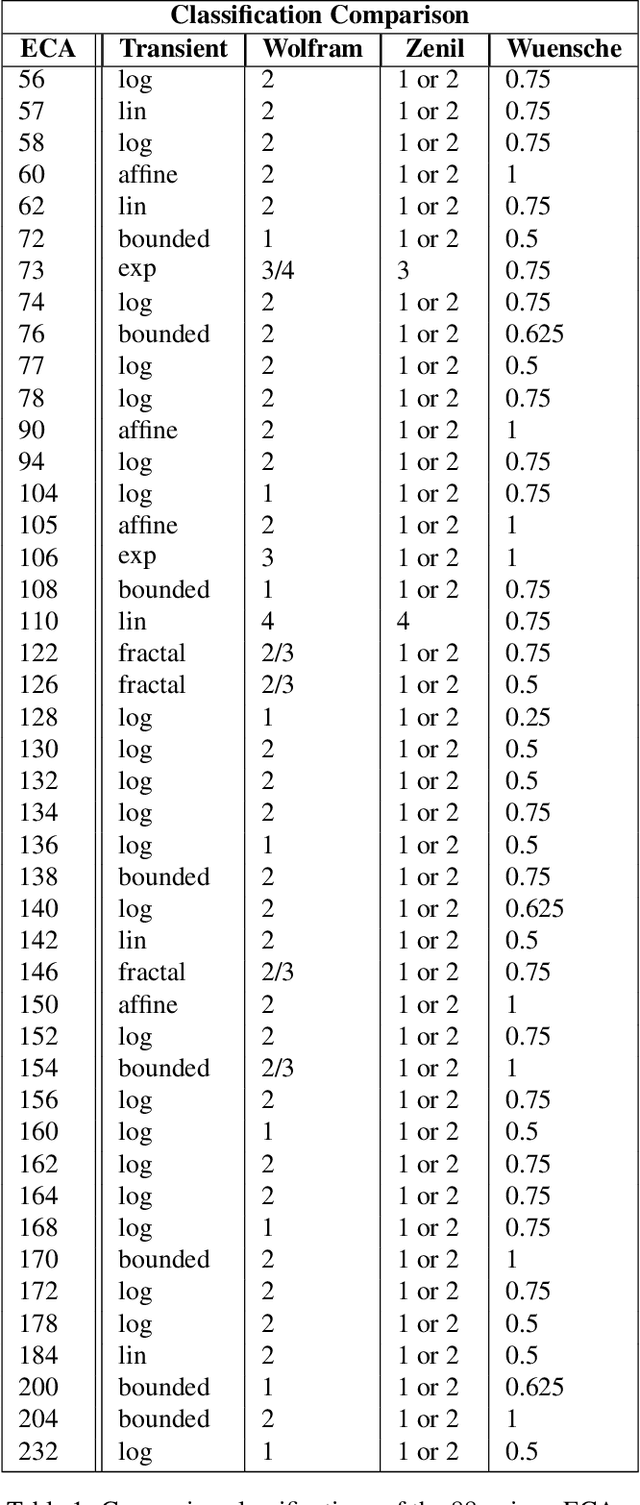
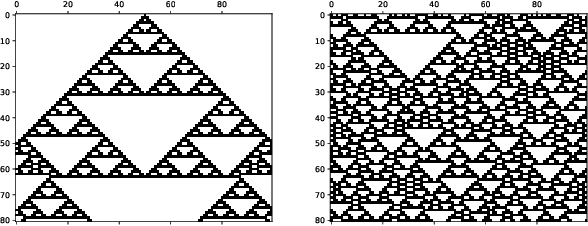
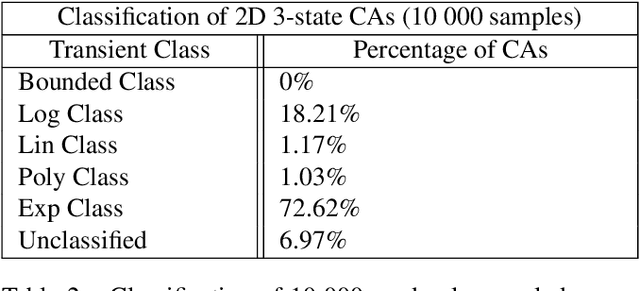
In order to develop systems capable of modeling artificial life, we need to identify, which systems can produce complex behavior. We present a novel classification method applicable to any class of deterministic discrete space and time dynamical systems. The method distinguishes between different asymptotic behaviors of a system's average computation time before entering a loop. When applied to elementary cellular automata, we obtain classification results, which correlate very well with Wolfram's manual classification. Further, we use it to classify 2D cellular automata to show that our technique can easily be applied to more complex models of computation. We believe this classification method can help to develop systems, in which complex structures emerge.
* 9 pages
Class-Agnostic Continual Learning of Alternating Languages and Domains
Apr 07, 2020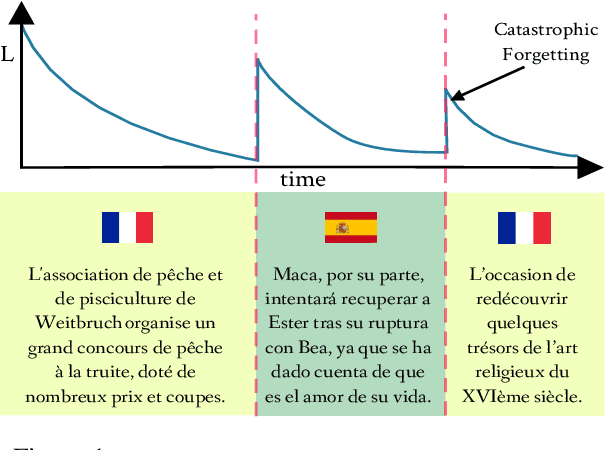

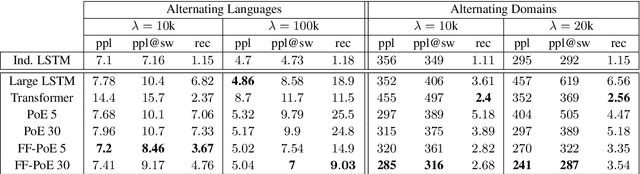
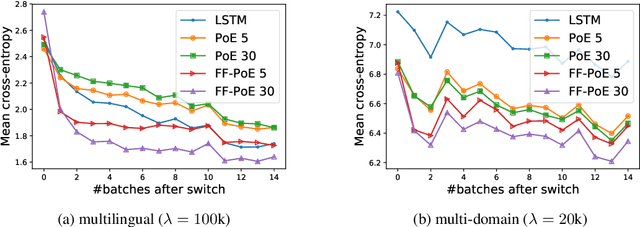
Continual Learning has been often framed as the problem of training a model in a sequence of tasks. In this regard, Neural Networks have been attested to forget the solutions to previous task as they learn new ones. Yet, modelling human life-long learning does not necessarily require any crisp notion of tasks. In this work, we propose a benchmark based on language modelling in a multilingual and multidomain setting that prescinds of any explicit delimitation of training examples into distinct tasks, and propose metrics to study continual learning and catastrophic forgetting in this setting. Then, we introduce a simple Product of Experts learning system that performs strongly on this problem while displaying interesting properties, and investigate its merits for avoiding forgetting.