 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaRAGe: A Benchmark with Grounding Annotations for RAG Evaluation
Jun 09, 2025We present GaRAGe, a large RAG benchmark with human-curated long-form answers and annotations of each grounding passage, allowing a fine-grained evaluation of whether LLMs can identify relevant grounding when generating RAG answers. Our benchmark contains 2366 questions of diverse complexity, dynamism, and topics, and includes over 35K annotated passages retrieved from both private document sets and the Web, to reflect real-world RAG use cases. This makes it an ideal test bed to evaluate an LLM's ability to identify only the relevant information necessary to compose a response, or provide a deflective response when there is insufficient information. Evaluations of multiple state-of-the-art LLMs on GaRAGe show that the models tend to over-summarise rather than (a) ground their answers strictly on the annotated relevant passages (reaching at most a Relevance-Aware Factuality Score of 60%), or (b) deflect when no relevant grounding is available (reaching at most 31% true positive rate in deflections). The F1 in attribution to relevant sources is at most 58.9%, and we show that performance is particularly reduced when answering time-sensitive questions and when having to draw knowledge from sparser private grounding sources.
Class-Agnostic Continual Learning of Alternating Languages and Domains
Apr 07, 2020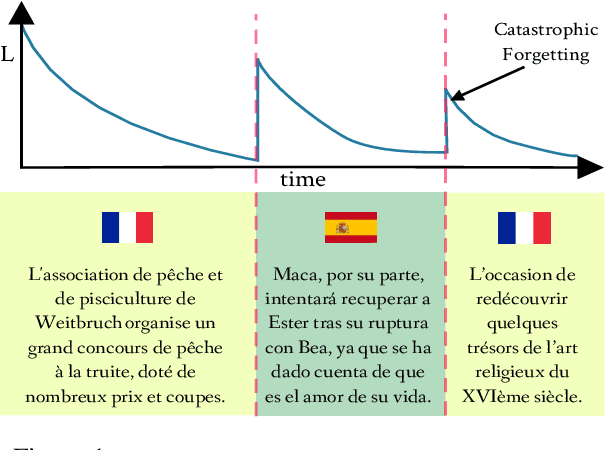

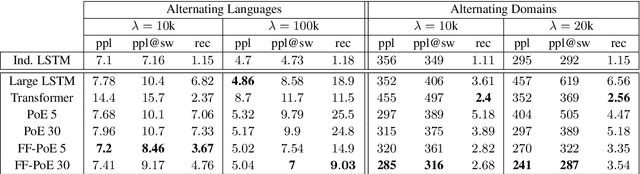
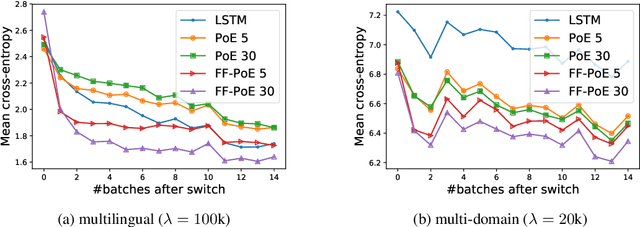
Continual Learning has been often framed as the problem of training a model in a sequence of tasks. In this regard, Neural Networks have been attested to forget the solutions to previous task as they learn new ones. Yet, modelling human life-long learning does not necessarily require any crisp notion of tasks. In this work, we propose a benchmark based on language modelling in a multilingual and multidomain setting that prescinds of any explicit delimitation of training examples into distinct tasks, and propose metrics to study continual learning and catastrophic forgetting in this setting. Then, we introduce a simple Product of Experts learning system that performs strongly on this problem while displaying interesting properties, and investigate its merits for avoiding forgetting.
Recurrent Instance Segmentation using Sequences of Referring Expressions
Nov 05, 2019
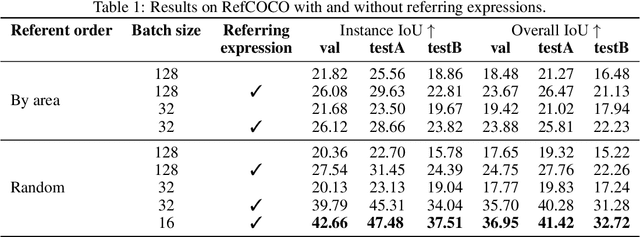
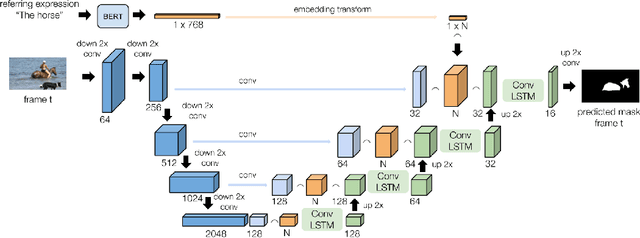

The goal of this work is to segment the objects in an image that are referred to by a sequence of linguistic descriptions (referring expressions). We propose a deep neural network with recurrent layers that output a sequence of binary masks, one for each referring expression provided by the user. The recurrent layers in the architecture allow the model to condition each predicted mask on the previous ones, from a spatial perspective within the same image. Our multimodal approach uses off-the-shelf architectures to encode both the image and the referring expressions. The visual branch provides a tensor of pixel embeddings that are concatenated with the phrase embeddings produced by a language encoder. Our experiments on the RefCOCO dataset for still images indicate how the proposed architecture successfully exploits the sequences of referring expressions to solve a pixel-wise task of instance segmentation.
What do Entity-Centric Models Learn? Insights from Entity Linking in Multi-Party Dialogue
May 16, 2019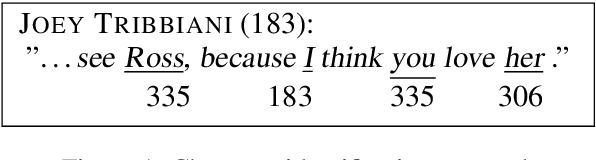
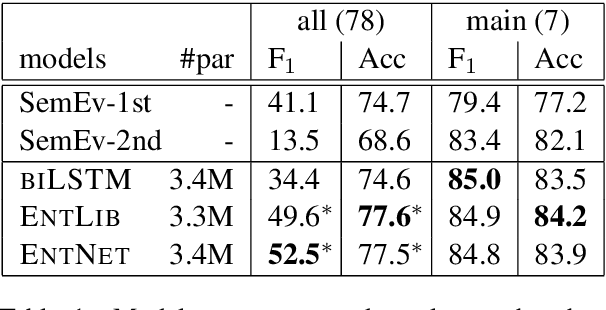

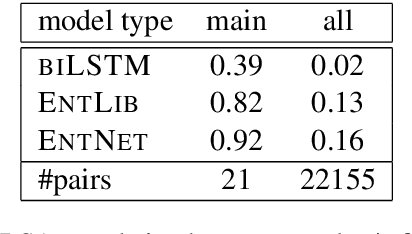
Humans use language to refer to entities in the external world. Motivated by this, in recent years several models that incorporate a bias towards learning entity representations have been proposed. Such entity-centric models have shown empirical success, but we still know little about why. In this paper we analyze the behavior of two recently proposed entity-centric models in a referential task, Entity Linking in Multi-party Dialogue (SemEval 2018 Task 4). We show that these models outperform the state of the art on this task, and that they do better on lower frequency entities than a counterpart model that is not entity-centric, with the same model size. We argue that making models entity-centric naturally fosters good architectural decisions. However, we also show that these models do not really build entity representations and that they make poor use of linguistic context. These negative results underscore the need for model analysis, to test whether the motivations for particular architectures are borne out in how models behave when deployed.
AMORE-UPF at SemEval-2018 Task 4: BiLSTM with Entity Library
May 14, 2018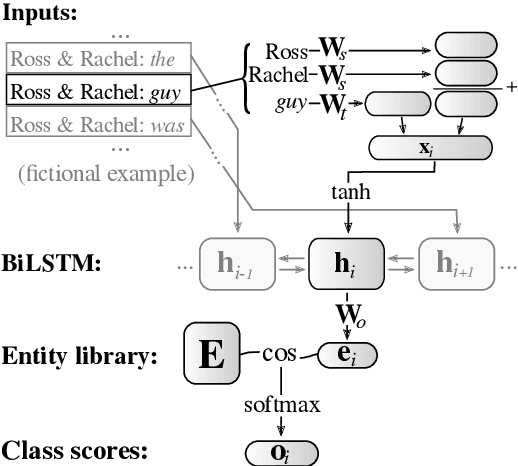

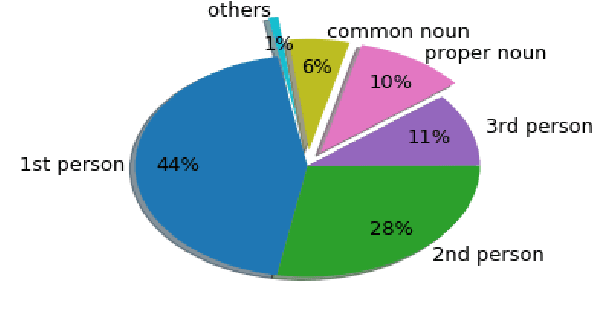
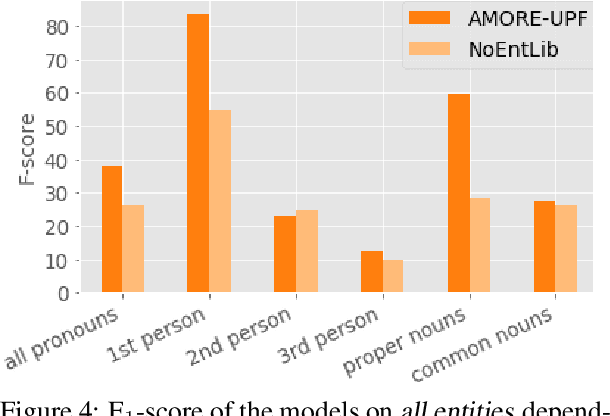
This paper describes our winning contribution to SemEval 2018 Task 4: Character Identification on Multiparty Dialogues. It is a simple, standard model with one key innovation, an entity library. Our results show that this innovation greatly facilitates the identification of infrequent characters. Because of the generic nature of our model, this finding is potentially relevant to any task that requires effective learning from sparse or unbalanced data.
Comparatives, Quantifiers, Proportions: A Multi-Task Model for the Learning of Quantities from Vision
Apr 13, 2018


The present work investigates whether different quantification mechanisms (set comparison, vague quantification, and proportional estimation) can be jointly learned from visual scenes by a multi-task computational model. The motivation is that, in humans, these processes underlie the same cognitive, non-symbolic ability, which allows an automatic estimation and comparison of set magnitudes. We show that when information about lower-complexity tasks is available, the higher-level proportional task becomes more accurate than when performed in isolation. Moreover, the multi-task model is able to generalize to unseen combinations of target/non-target objects. Consistently with behavioral evidence showing the interference of absolute number in the proportional task, the multi-task model no longer works when asked to provide the number of target objects in the scene.
* 12 pages (references included). To appear in the Proceedings of NAACL-HLT 2018