 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactual Confidence of LLMs: on Reliability and Robustness of Current Estimators
Jun 19, 2024Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM's confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual confidence. We define an experimental framework allowing for fair comparison, covering both fact-verification and question answering. Our experiments across a series of LLMs indicate that trained hidden-state probes provide the most reliable confidence estimates, albeit at the expense of requiring access to weights and training data. We also conduct a deeper assessment of factual confidence by measuring the consistency of model behavior under meaning-preserving variations in the input. We find that the confidence of LLMs is often unstable across semantically equivalent inputs, suggesting that there is much room for improvement of the stability of models' parametric knowledge. Our code is available at (https://github.com/amazon-science/factual-confidence-of-llms).
Does referent predictability affect the choice of referential form? A computational approach using masked coreference resolution
Sep 27, 2021
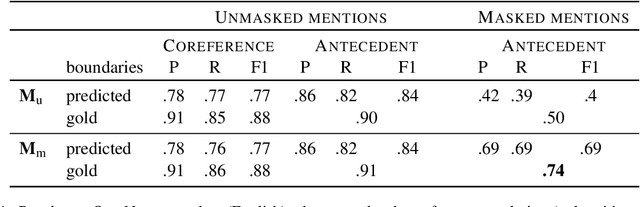
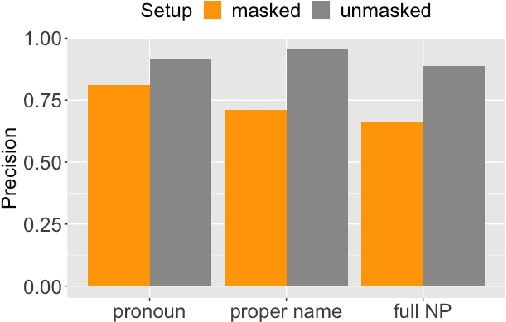

It is often posited that more predictable parts of a speaker's meaning tend to be made less explicit, for instance using shorter, less informative words. Studying these dynamics in the domain of referring expressions has proven difficult, with existing studies, both psycholinguistic and corpus-based, providing contradictory results. We test the hypothesis that speakers produce less informative referring expressions (e.g., pronouns vs. full noun phrases) when the context is more informative about the referent, using novel computational estimates of referent predictability. We obtain these estimates training an existing coreference resolution system for English on a new task, masked coreference resolution, giving us a probability distribution over referents that is conditioned on the context but not the referring expression. The resulting system retains standard coreference resolution performance while yielding a better estimate of human-derived referent predictability than previous attempts. A statistical analysis of the relationship between model output and mention form supports the hypothesis that predictability affects the form of a mention, both its morphosyntactic type and its length.
The Language Model Understood the Prompt was Ambiguous: Probing Syntactic Uncertainty Through Generation
Sep 16, 2021
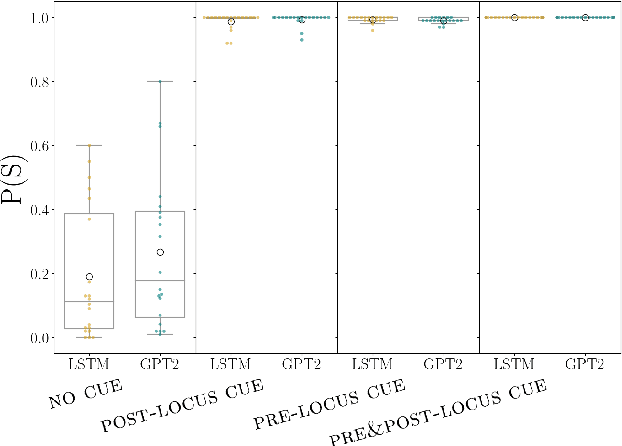

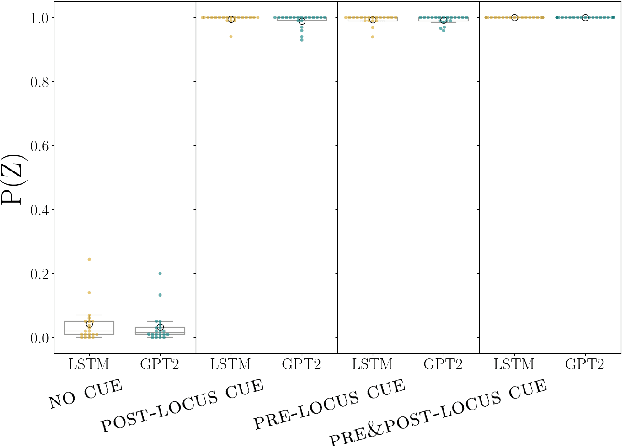
Temporary syntactic ambiguities arise when the beginning of a sentence is compatible with multiple syntactic analyses. We inspect to which extent neural language models (LMs) exhibit uncertainty over such analyses when processing temporarily ambiguous inputs, and how that uncertainty is modulated by disambiguating cues. We probe the LM's expectations by generating from it: we use stochastic decoding to derive a set of sentence completions, and estimate the probability that the LM assigns to each interpretation based on the distribution of parses across completions. Unlike scoring-based methods for targeted syntactic evaluation, this technique makes it possible to explore completions that are not hypothesized in advance by the researcher. We apply this method to study the behavior of two LMs (GPT2 and an LSTM) on three types of temporary ambiguity, using materials from human sentence processing experiments. We find that LMs can track multiple analyses simultaneously; the degree of uncertainty varies across constructions and contexts. As a response to disambiguating cues, the LMs often select the correct interpretation, but occasional errors point to potential areas of improvement.
Putting words in context: LSTM language models and lexical ambiguity
Jun 12, 2019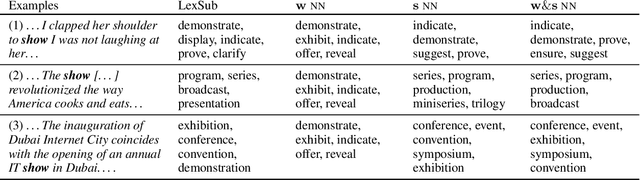
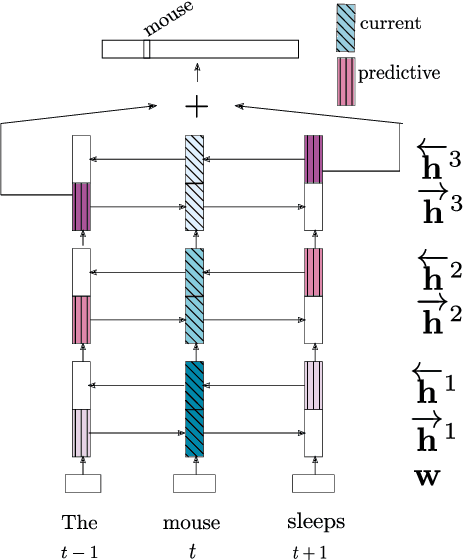
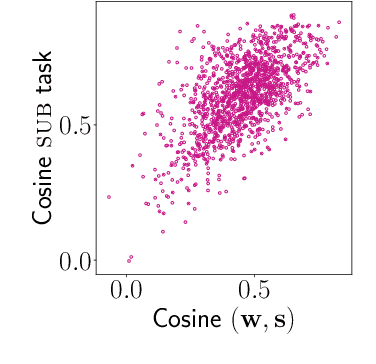
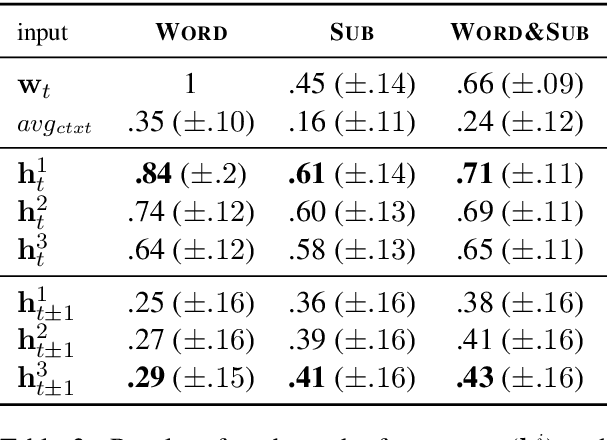
In neural network models of language, words are commonly represented using context-invariant representations (word embeddings) which are then put in context in the hidden layers. Since words are often ambiguous, representing the contextually relevant information is not trivial. We investigate how an LSTM language model deals with lexical ambiguity in English, designing a method to probe its hidden representations for lexical and contextual information about words. We find that both types of information are represented to a large extent, but also that there is room for improvement for contextual information.
What do Entity-Centric Models Learn? Insights from Entity Linking in Multi-Party Dialogue
May 16, 2019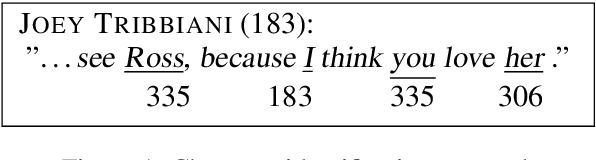
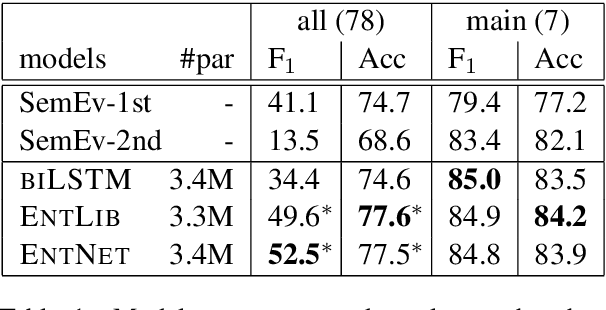

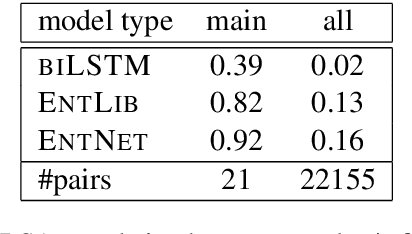
Humans use language to refer to entities in the external world. Motivated by this, in recent years several models that incorporate a bias towards learning entity representations have been proposed. Such entity-centric models have shown empirical success, but we still know little about why. In this paper we analyze the behavior of two recently proposed entity-centric models in a referential task, Entity Linking in Multi-party Dialogue (SemEval 2018 Task 4). We show that these models outperform the state of the art on this task, and that they do better on lower frequency entities than a counterpart model that is not entity-centric, with the same model size. We argue that making models entity-centric naturally fosters good architectural decisions. However, we also show that these models do not really build entity representations and that they make poor use of linguistic context. These negative results underscore the need for model analysis, to test whether the motivations for particular architectures are borne out in how models behave when deployed.
AMORE-UPF at SemEval-2018 Task 4: BiLSTM with Entity Library
May 14, 2018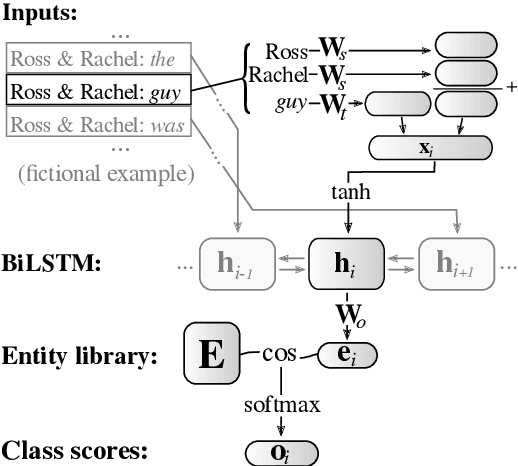

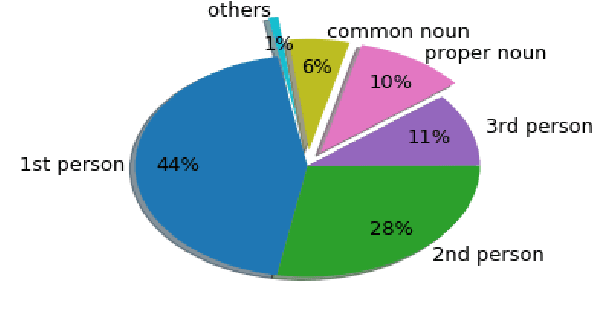
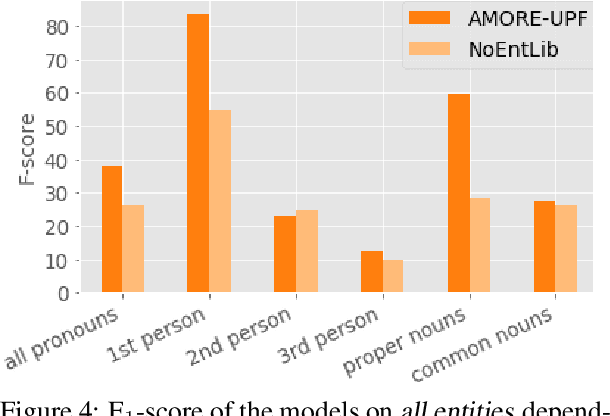
This paper describes our winning contribution to SemEval 2018 Task 4: Character Identification on Multiparty Dialogues. It is a simple, standard model with one key innovation, an entity library. Our results show that this innovation greatly facilitates the identification of infrequent characters. Because of the generic nature of our model, this finding is potentially relevant to any task that requires effective learning from sparse or unbalanced data.