Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting words in context: LSTM language models and lexical ambiguity
Paper and Code
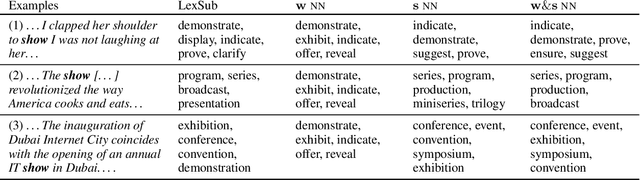
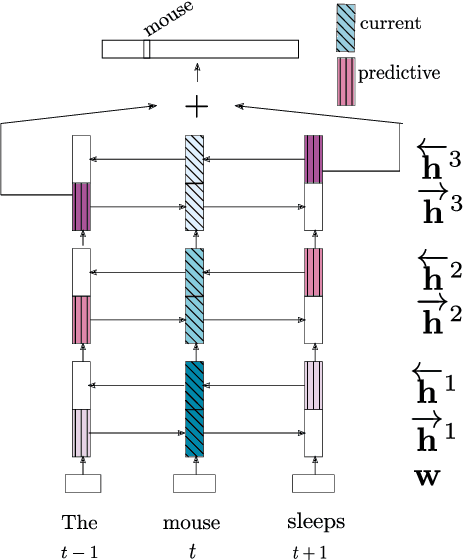
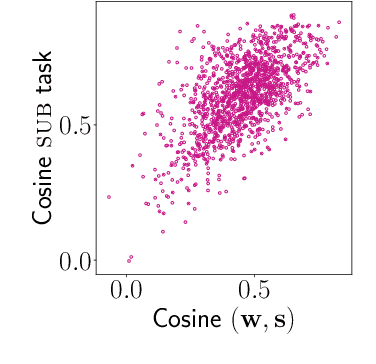
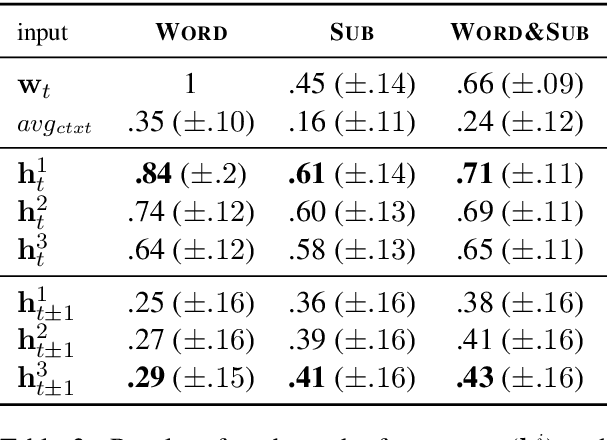
In neural network models of language, words are commonly represented using context-invariant representations (word embeddings) which are then put in context in the hidden layers. Since words are often ambiguous, representing the contextually relevant information is not trivial. We investigate how an LSTM language model deals with lexical ambiguity in English, designing a method to probe its hidden representations for lexical and contextual information about words. We find that both types of information are represented to a large extent, but also that there is room for improvement for contextual information.
* To appear in Proceedings of the 57th Annual Meeting of the
Association for Computational Linguistics (ACL)
View paper on