 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich one is the dax? Achieving mutual exclusivity with neural networks
Apr 08, 2020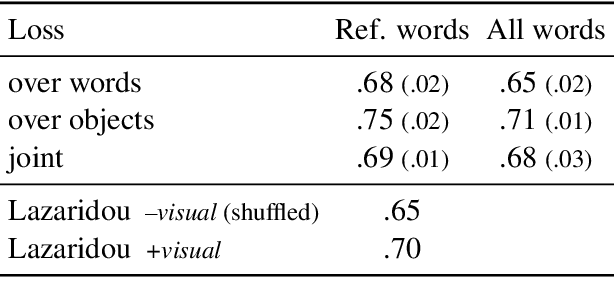
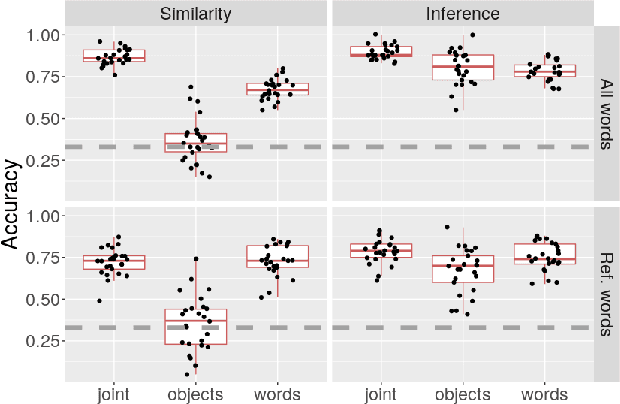
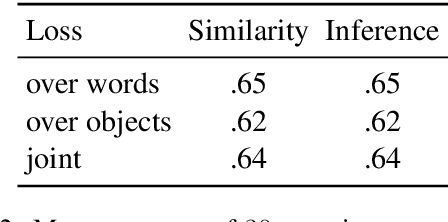
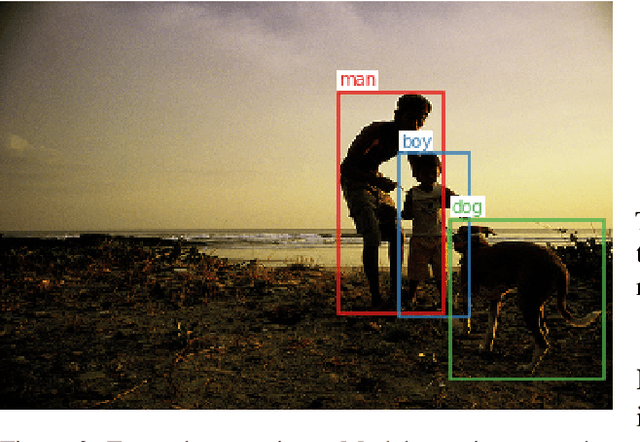
Learning words is a challenge for children and neural networks alike. However, what they struggle with can differ. When prompted by novel words, children have been shown to tend to associate them with unfamiliar referents. This has been taken to reflect a propensity toward mutual exclusivity. In this study, we investigate whether and under which circumstances neural models can exhibit analogous behavior. To this end, we evaluate cross-situational neural models on novel items with distractors, contrasting the interaction between different word learning and referent selection strategies. We find that, as long as they bring about competition between words, constraints in both learning and referent selection can improve success in tasks with novel words and referents. For neural network research, our findings clarify the role of available options for enhanced performance in tasks where mutual exclusivity is advantageous. For cognitive research, they highlight latent interactions between word learning, referent selection mechanisms, and the structure of stimuli.
Putting words in context: LSTM language models and lexical ambiguity
Jun 12, 2019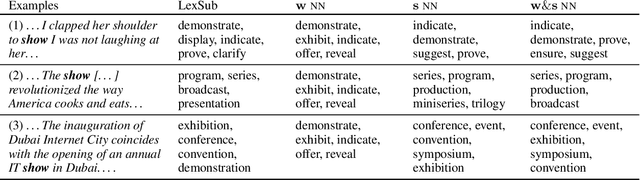
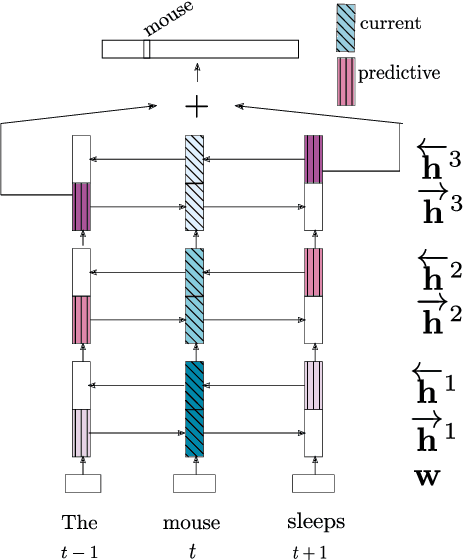
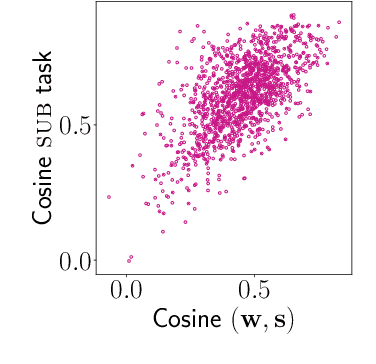
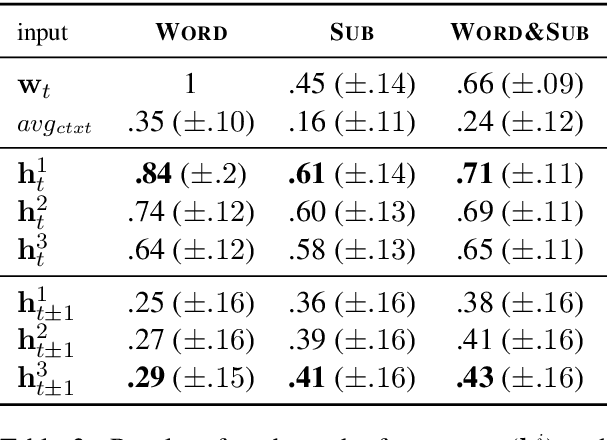
In neural network models of language, words are commonly represented using context-invariant representations (word embeddings) which are then put in context in the hidden layers. Since words are often ambiguous, representing the contextually relevant information is not trivial. We investigate how an LSTM language model deals with lexical ambiguity in English, designing a method to probe its hidden representations for lexical and contextual information about words. We find that both types of information are represented to a large extent, but also that there is room for improvement for contextual information.
Colorless green recurrent networks dream hierarchically
Mar 29, 2018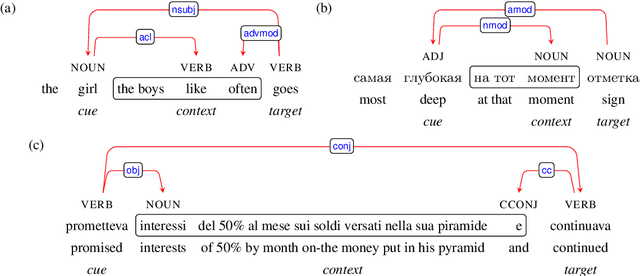
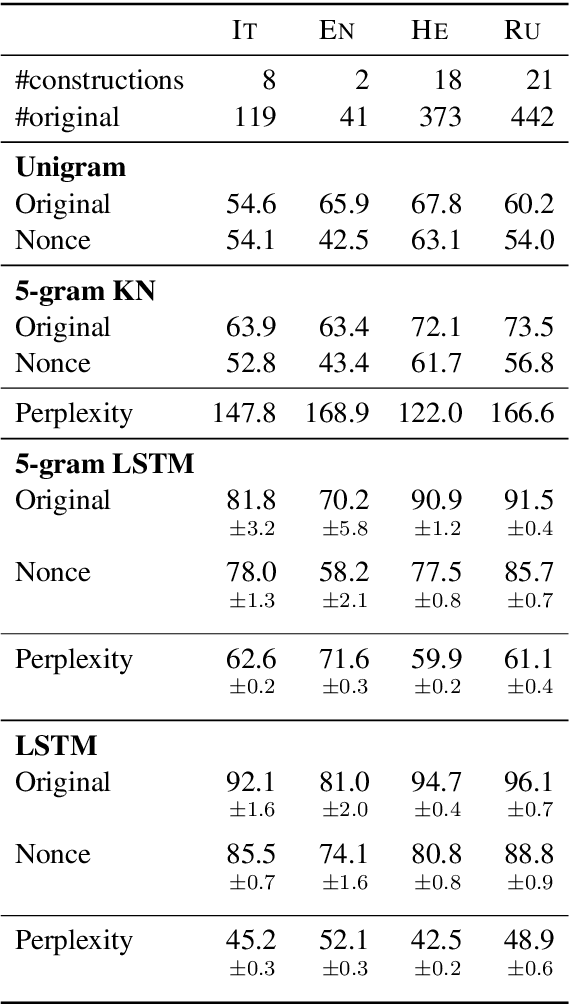
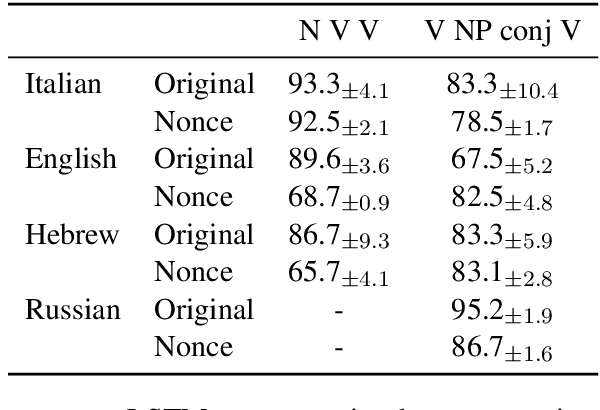
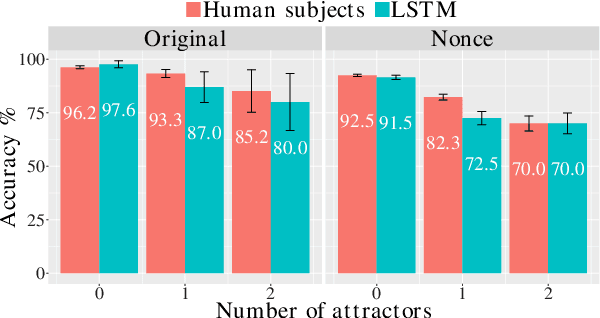
Recurrent neural networks (RNNs) have achieved impressive results in a variety of linguistic processing tasks, suggesting that they can induce non-trivial properties of language. We investigate here to what extent RNNs learn to track abstract hierarchical syntactic structure. We test whether RNNs trained with a generic language modeling objective in four languages (Italian, English, Hebrew, Russian) can predict long-distance number agreement in various constructions. We include in our evaluation nonsensical sentences where RNNs cannot rely on semantic or lexical cues ("The colorless green ideas I ate with the chair sleep furiously"), and, for Italian, we compare model performance to human intuitions. Our language-model-trained RNNs make reliable predictions about long-distance agreement, and do not lag much behind human performance. We thus bring support to the hypothesis that RNNs are not just shallow-pattern extractors, but they also acquire deeper grammatical competence.