 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Human-Like Color Naming Behavior in Context
Apr 28, 2026Modeling the emergence of human-like lexicons in computational systems has advanced through the use of interacting neural agents, which simulate both learning and communicative pressures. The NeLLCom-Lex framework (Zhang et al., 2025) allows neural agents to develop pragmatic color naming behavior and human-like lexicons through supervised learning (SL) from human data and reinforcement learning (RL) in referential games. Despite these successes, the lexicons that emerge diverge systematically from human color categories, producing highly non-convex regions in color space, which contrast with the convexity typical of human categories. To address this, we introduce two factors, upsampling rare color terms during SL and multi-listener RL interactions, and adopt a convexity measure to quantify geometric coherence. We find that upsampling improves lexical diversity and system-level informativeness of the color lexicon, while many-listener setups promote more convex color categories. The combination of moderate upsampling and multiple listeners produces lexicons most similar to human systems.
Sparse or Dense? A Mechanistic Estimation of Computation Density in Transformer-based LLMs
Jan 30, 2026Transformer-based large language models (LLMs) are comprised of billions of parameters arranged in deep and wide computational graphs. Several studies on LLM efficiency optimization argue that it is possible to prune a significant portion of the parameters, while only marginally impacting performance. This suggests that the computation is not uniformly distributed across the parameters. We introduce here a technique to systematically quantify computation density in LLMs. In particular, we design a density estimator drawing on mechanistic interpretability. We experimentally test our estimator and find that: (1) contrary to what has been often assumed, LLM processing generally involves dense computation; (2) computation density is dynamic, in the sense that models shift between sparse and dense processing regimes depending on the input; (3) per-input density is significantly correlated across LLMs, suggesting that the same inputs trigger either low or high density. Investigating the factors influencing density, we observe that predicting rarer tokens requires higher density, and increasing context length often decreases the density. We believe that our computation density estimator will contribute to a better understanding of the processing at work in LLMs, challenging their symbolic interpretation.
NeLLCom-Lex: A Neural-agent Framework to Study the Interplay between Lexical Systems and Language Use
Sep 26, 2025



Lexical semantic change has primarily been investigated with observational and experimental methods; however, observational methods (corpus analysis, distributional semantic modeling) cannot get at causal mechanisms, and experimental paradigms with humans are hard to apply to semantic change due to the extended diachronic processes involved. This work introduces NeLLCom-Lex, a neural-agent framework designed to simulate semantic change by first grounding agents in a real lexical system (e.g. English) and then systematically manipulating their communicative needs. Using a well-established color naming task, we simulate the evolution of a lexical system within a single generation, and study which factors lead agents to: (i) develop human-like naming behavior and lexicons, and (ii) change their behavior and lexicons according to their communicative needs. Our experiments with different supervised and reinforcement learning pipelines show that neural agents trained to 'speak' an existing language can reproduce human-like patterns in color naming to a remarkable extent, supporting the further use of NeLLCom-Lex to elucidate the mechanisms of semantic change.
Outlier dimensions favor frequent tokens in language model
Mar 27, 2025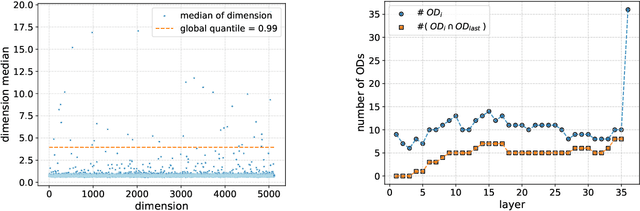



We study last-layer outlier dimensions, i.e.dimensions that display extreme activations for the majority of inputs. We show that outlier dimensions arise in many different modern language models, and trace their function back to the heuristic of constantly predicting frequent words. We further show how a model can block this heuristic when it is not contextually appropriate, by assigning a counterbalancing weight mass to the remaining dimensions, and we investigate which model parameters boost outlier dimensions and when they arise during training. We conclude that outlier dimensions are a specialized mechanism discovered by many distinct models to implement a useful token prediction heuristic.
LLMs as a synthesis between symbolic and continuous approaches to language
Feb 17, 2025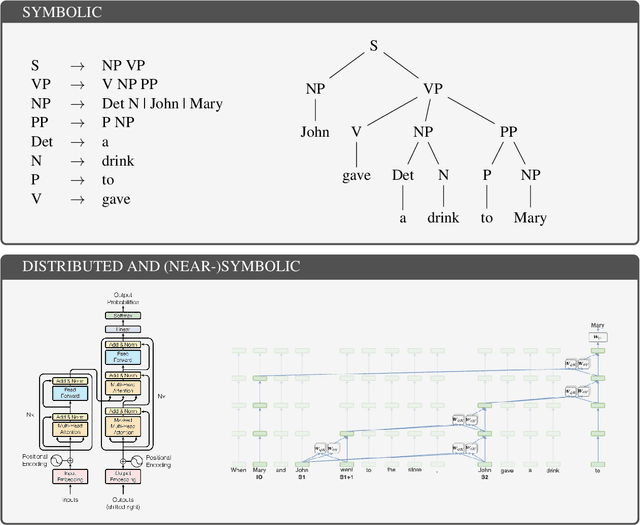
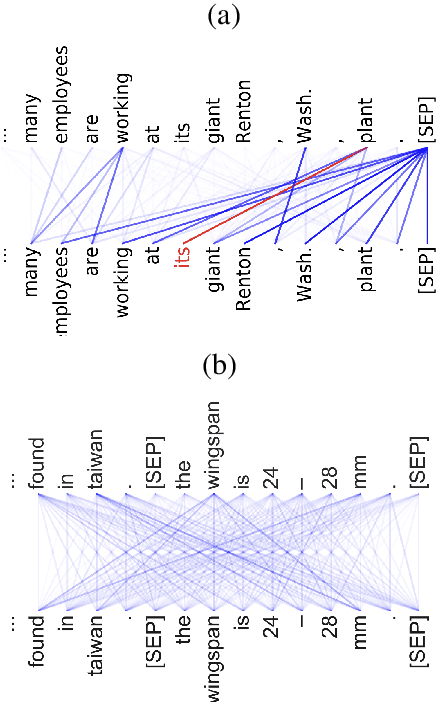
Since the middle of the 20th century, a fierce battle is being fought between symbolic and continuous approaches to language and cognition. The success of deep learning models, and LLMs in particular, has been alternatively taken as showing that the continuous camp has won, or dismissed as an irrelevant engineering development. However, in this position paper I argue that deep learning models for language actually represent a synthesis between the two traditions. This is because 1) deep learning architectures allow for both continuous/distributed and symbolic/discrete-like representations and computations; 2) models trained on language make use this flexibility. In particular, I review recent research in mechanistic interpretability that showcases how a substantial part of morphosyntactic knowledge is encoded in a near-discrete fashion in LLMs. This line of research suggests that different behaviors arise in an emergent fashion, and models flexibly alternate between the two modes (and everything in between) as needed. This is possibly one of the main reasons for their wild success; and it is also what makes them particularly interesting for the study of language and cognition. Is it time for peace?
Why do objects have many names? A study on word informativeness in language use and lexical systems
Oct 10, 2024
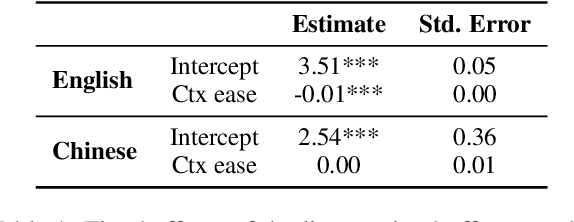
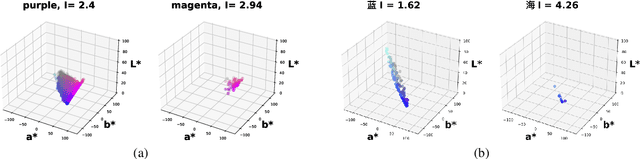
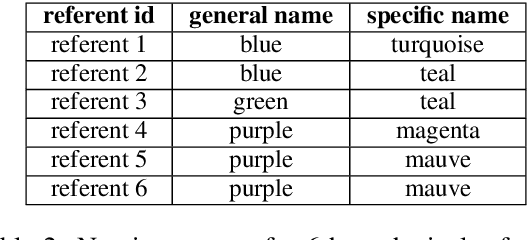
Human lexicons contain many different words that speakers can use to refer to the same object, e.g., "purple" or "magenta" for the same shade of color. On the one hand, studies on language use have explored how speakers adapt their referring expressions to successfully communicate in context, without focusing on properties of the lexical system. On the other hand, studies in language evolution have discussed how competing pressures for informativeness and simplicity shape lexical systems, without tackling in-context communication. We aim at bridging the gap between these traditions, and explore why a soft mapping between referents and words is a good solution for communication, by taking into account both in-context communication and the structure of the lexicon. We propose a simple measure of informativeness for words and lexical systems, grounded in a visual space, and analyze color naming data for English and Mandarin Chinese. We conclude that optimal lexical systems are those where multiple words can apply to the same referent, conveying different amounts of information. Such systems allow speakers to maximize communication accuracy and minimize the amount of information they convey when communicating about referents in contexts.
The Impact of Familiarity on Naming Variation: A Study on Object Naming in Mandarin Chinese
Nov 16, 2023



Different speakers often produce different names for the same object or entity (e.g., "woman" vs. "tourist" for a female tourist). The reasons behind variation in naming are not well understood. We create a Language and Vision dataset for Mandarin Chinese that provides an average of 20 names for 1319 naturalistic images, and investigate how familiarity with a given kind of object relates to the degree of naming variation it triggers across subjects. We propose that familiarity influences naming variation in two competing ways: increasing familiarity can either expand vocabulary, leading to higher variation, or promote convergence on conventional names, thereby reducing variation. We find evidence for both factors being at play. Our study illustrates how computational resources can be used to address research questions in Cognitive Science.
Run Like a Girl! Sports-Related Gender Bias in Language and Vision
May 23, 2023
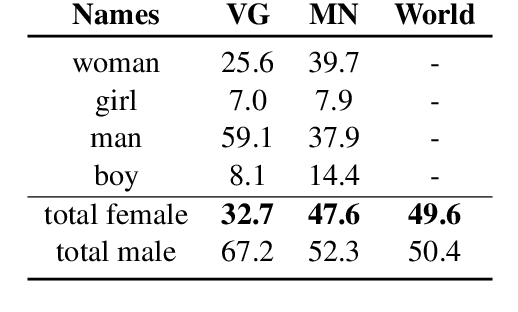
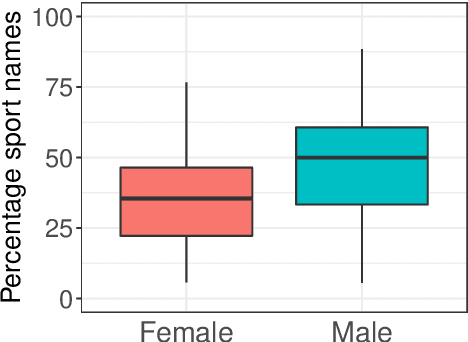
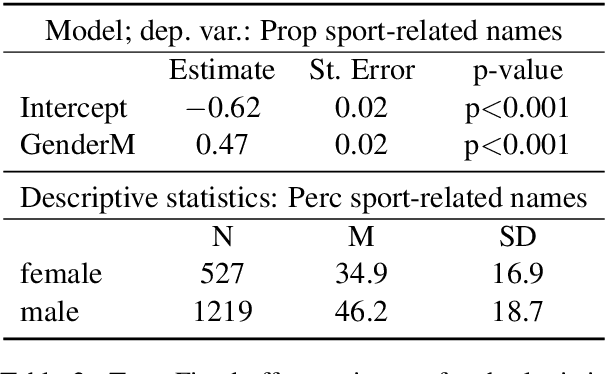
Gender bias in Language and Vision datasets and models has the potential to perpetuate harmful stereotypes and discrimination. We analyze gender bias in two Language and Vision datasets. Consistent with prior work, we find that both datasets underrepresent women, which promotes their invisibilization. Moreover, we hypothesize and find that a bias affects human naming choices for people playing sports: speakers produce names indicating the sport (e.g. 'tennis player' or 'surfer') more often when it is a man or a boy participating in the sport than when it is a woman or a girl, with an average of 46% vs. 35% of sports-related names for each gender. A computational model trained on these naming data reproduces the bias. We argue that both the data and the model result in representational harm against women.
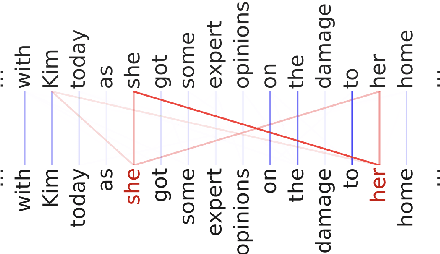
Does referent predictability affect the choice of referential form? A computational approach using masked coreference resolution
Sep 27, 2021
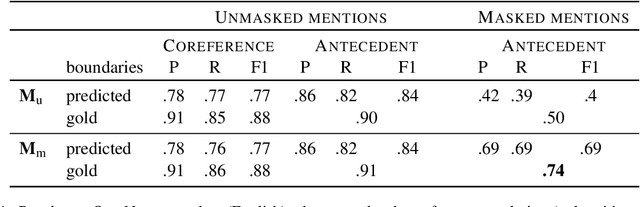
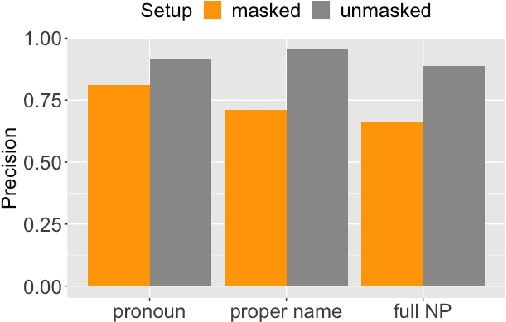

It is often posited that more predictable parts of a speaker's meaning tend to be made less explicit, for instance using shorter, less informative words. Studying these dynamics in the domain of referring expressions has proven difficult, with existing studies, both psycholinguistic and corpus-based, providing contradictory results. We test the hypothesis that speakers produce less informative referring expressions (e.g., pronouns vs. full noun phrases) when the context is more informative about the referent, using novel computational estimates of referent predictability. We obtain these estimates training an existing coreference resolution system for English on a new task, masked coreference resolution, giving us a probability distribution over referents that is conditioned on the context but not the referring expression. The resulting system retains standard coreference resolution performance while yielding a better estimate of human-derived referent predictability than previous attempts. A statistical analysis of the relationship between model output and mention form supports the hypothesis that predictability affects the form of a mention, both its morphosyntactic type and its length.
Which one is the dax? Achieving mutual exclusivity with neural networks
Apr 08, 2020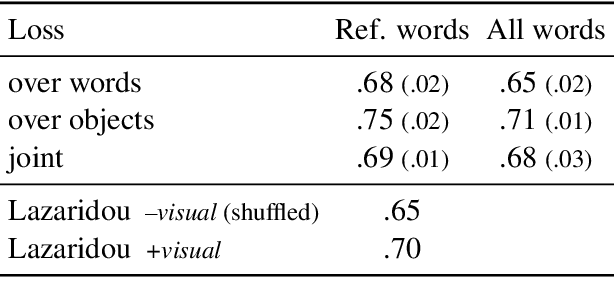
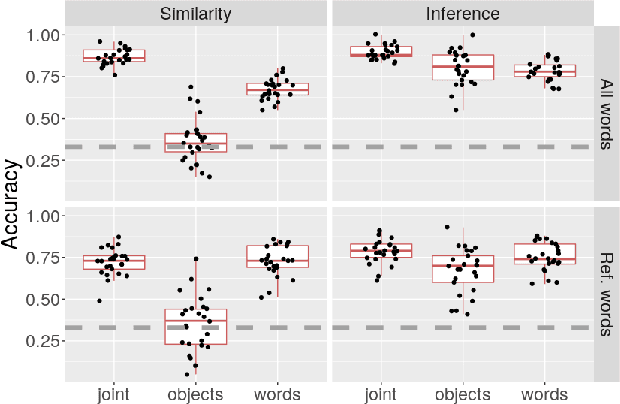
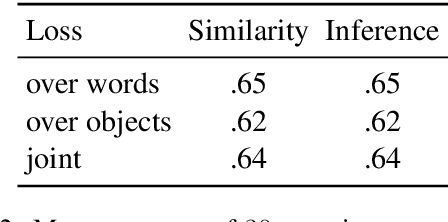
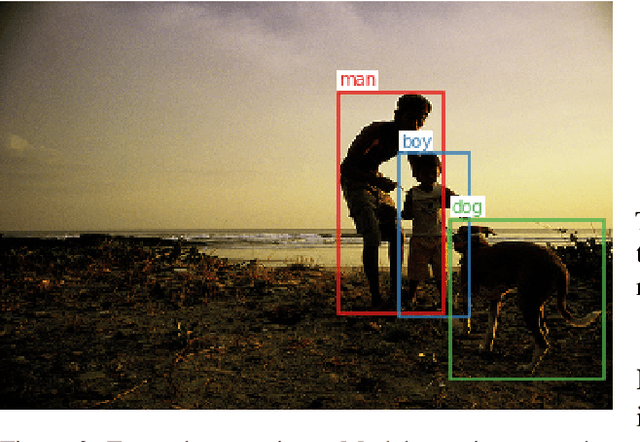
Learning words is a challenge for children and neural networks alike. However, what they struggle with can differ. When prompted by novel words, children have been shown to tend to associate them with unfamiliar referents. This has been taken to reflect a propensity toward mutual exclusivity. In this study, we investigate whether and under which circumstances neural models can exhibit analogous behavior. To this end, we evaluate cross-situational neural models on novel items with distractors, contrasting the interaction between different word learning and referent selection strategies. We find that, as long as they bring about competition between words, constraints in both learning and referent selection can improve success in tasks with novel words and referents. For neural network research, our findings clarify the role of available options for enhanced performance in tasks where mutual exclusivity is advantageous. For cognitive research, they highlight latent interactions between word learning, referent selection mechanisms, and the structure of stimuli.