 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDonate or Create? Comparing Data Collection Strategies for Emotion-labeled Multimodal Social Media Posts
May 30, 2025Accurate modeling of subjective phenomena such as emotion expression requires data annotated with authors' intentions. Commonly such data is collected by asking study participants to donate and label genuine content produced in the real world, or create content fitting particular labels during the study. Asking participants to create content is often simpler to implement and presents fewer risks to participant privacy than data donation. However, it is unclear if and how study-created content may differ from genuine content, and how differences may impact models. We collect study-created and genuine multimodal social media posts labeled for emotion and compare them on several dimensions, including model performance. We find that compared to genuine posts, study-created posts are longer, rely more on their text and less on their images for emotion expression, and focus more on emotion-prototypical events. The samples of participants willing to donate versus create posts are demographically different. Study-created data is valuable to train models that generalize well to genuine data, but realistic effectiveness estimates require genuine data.
Implicit Affordance Acquisition via Causal Action-Effect Modeling in the Video Domain
Dec 18, 2023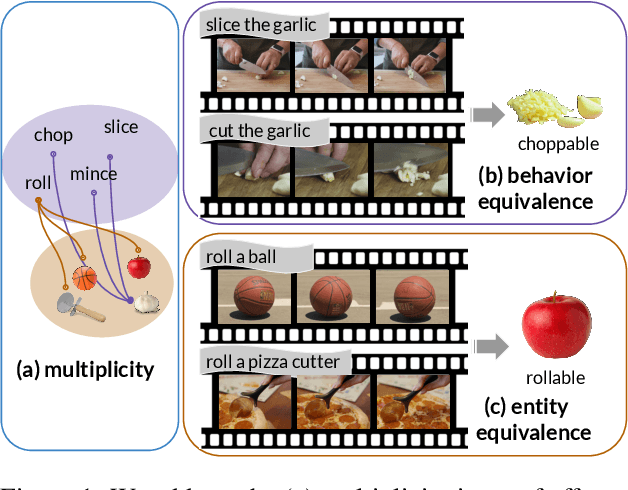
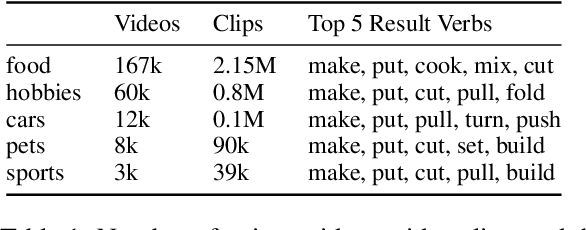

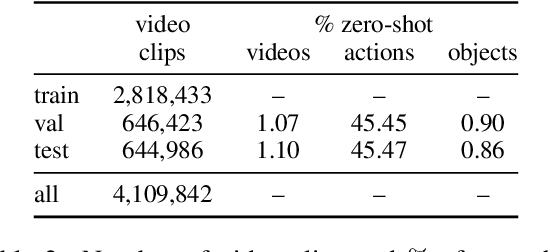
Affordance knowledge is a fundamental aspect of commonsense knowledge. Recent findings indicate that world knowledge emerges through large-scale self-supervised pretraining, motivating our exploration of acquiring affordance knowledge from the visual domain. To this end, we augment an existing instructional video resource to create the new Causal Action-Effect (CAE) dataset and design two novel pretraining tasks -- Masked Action Modeling (MAM) and Masked Effect Modeling (MEM) -- promoting the acquisition of two affordance properties in models: behavior and entity equivalence, respectively. We empirically demonstrate the effectiveness of our proposed methods in learning affordance properties. Furthermore, we show that a model pretrained on both tasks outperforms a strong image-based visual-linguistic foundation model (FLAVA) as well as pure linguistic models on a zero-shot physical reasoning probing task.
On the Complementarity of Images and Text for the Expression of Emotions in Social Media
Feb 11, 2022
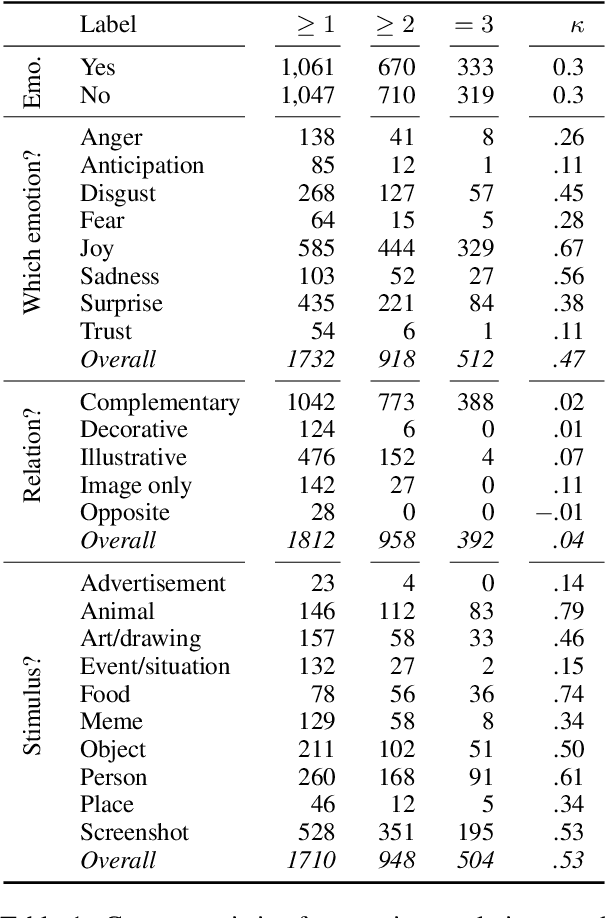


Authors of posts in social media communicate their emotions and what causes them with text and images. While there is work on emotion and stimulus detection for each modality separately, it is yet unknown if the modalities contain complementary emotion information in social media. We aim at filling this research gap and contribute a novel, annotated corpus of English multimodal Reddit posts. On this resource, we develop models to automatically detect the relation between image and text, an emotion stimulus category and the emotion class. We evaluate if these tasks require both modalities and find for the image-text relations, that text alone is sufficient for most categories (complementary, illustrative, opposing): the information in the text allows to predict if an image is required for emotion understanding. The emotions of anger and sadness are best predicted with a multimodal model, while text alone is sufficient for disgust, joy, and surprise. Stimuli depicted by objects, animals, food, or a person are best predicted by image-only models, while multimodal models are most effective on art, events, memes, places, or screenshots.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 09, 2021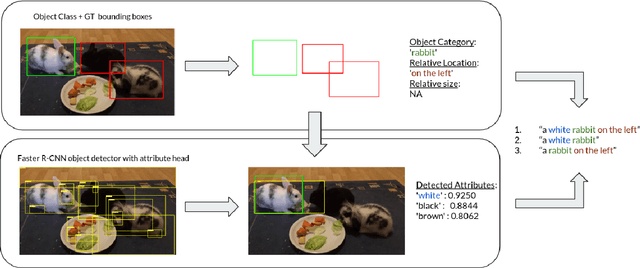



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
RefVOS: A Closer Look at Referring Expressions for Video Object Segmentation
Oct 01, 2020

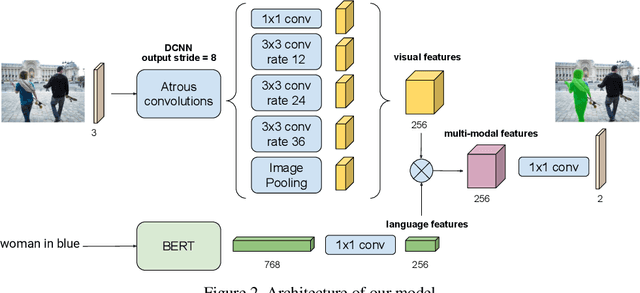
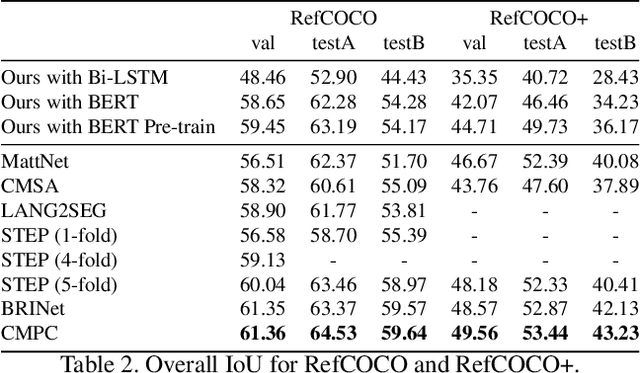
The task of video object segmentation with referring expressions (language-guided VOS) is to, given a linguistic phrase and a video, generate binary masks for the object to which the phrase refers. Our work argues that existing benchmarks used for this task are mainly composed of trivial cases, in which referents can be identified with simple phrases. Our analysis relies on a new categorization of the phrases in the DAVIS-2017 and Actor-Action datasets into trivial and non-trivial REs, with the non-trivial REs annotated with seven RE semantic categories. We leverage this data to analyze the results of RefVOS, a novel neural network that obtains competitive results for the task of language-guided image segmentation and state of the art results for language-guided VOS. Our study indicates that the major challenges for the task are related to understanding motion and static actions.
Recurrent Instance Segmentation using Sequences of Referring Expressions
Nov 05, 2019
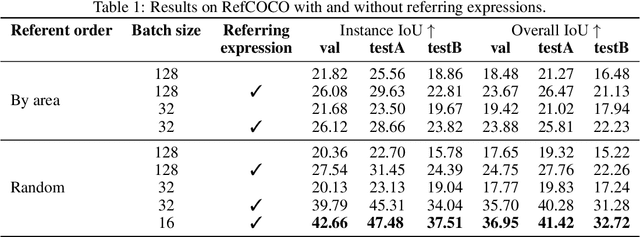
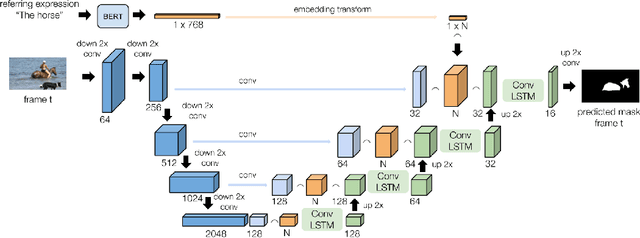

The goal of this work is to segment the objects in an image that are referred to by a sequence of linguistic descriptions (referring expressions). We propose a deep neural network with recurrent layers that output a sequence of binary masks, one for each referring expression provided by the user. The recurrent layers in the architecture allow the model to condition each predicted mask on the previous ones, from a spatial perspective within the same image. Our multimodal approach uses off-the-shelf architectures to encode both the image and the referring expressions. The visual branch provides a tensor of pixel embeddings that are concatenated with the phrase embeddings produced by a language encoder. Our experiments on the RefCOCO dataset for still images indicate how the proposed architecture successfully exploits the sequences of referring expressions to solve a pixel-wise task of instance segmentation.
What do Entity-Centric Models Learn? Insights from Entity Linking in Multi-Party Dialogue
May 16, 2019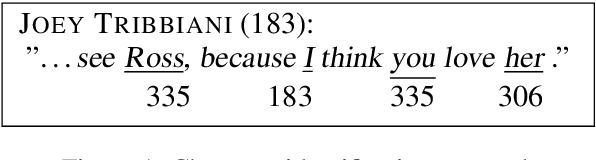
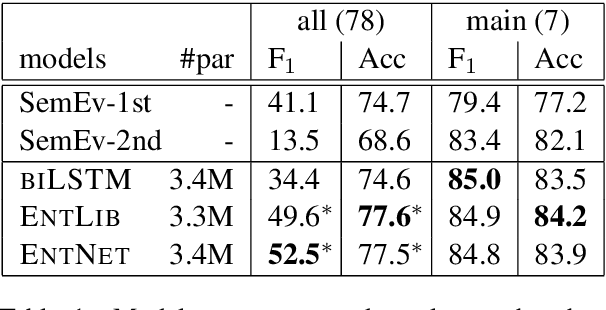

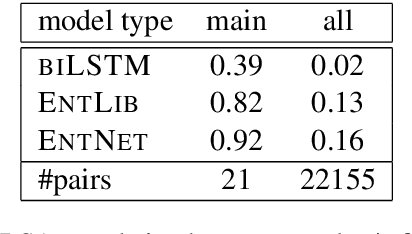
Humans use language to refer to entities in the external world. Motivated by this, in recent years several models that incorporate a bias towards learning entity representations have been proposed. Such entity-centric models have shown empirical success, but we still know little about why. In this paper we analyze the behavior of two recently proposed entity-centric models in a referential task, Entity Linking in Multi-party Dialogue (SemEval 2018 Task 4). We show that these models outperform the state of the art on this task, and that they do better on lower frequency entities than a counterpart model that is not entity-centric, with the same model size. We argue that making models entity-centric naturally fosters good architectural decisions. However, we also show that these models do not really build entity representations and that they make poor use of linguistic context. These negative results underscore the need for model analysis, to test whether the motivations for particular architectures are borne out in how models behave when deployed.
AMORE-UPF at SemEval-2018 Task 4: BiLSTM with Entity Library
May 14, 2018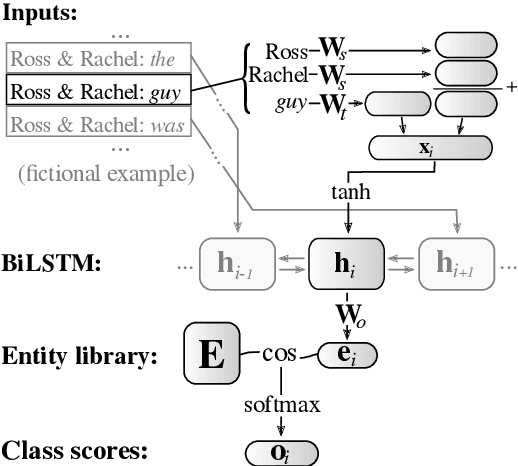

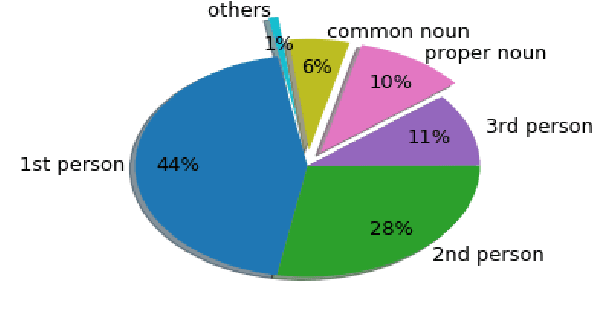
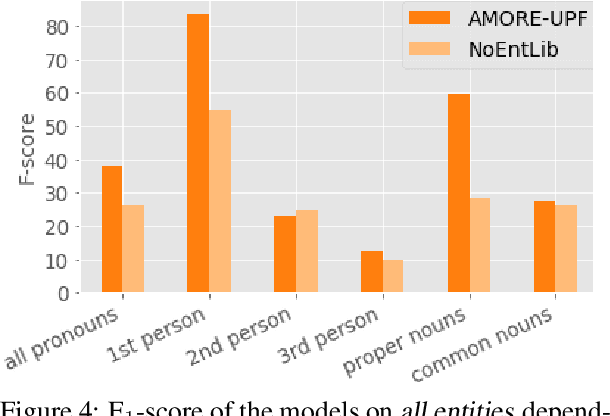
This paper describes our winning contribution to SemEval 2018 Task 4: Character Identification on Multiparty Dialogues. It is a simple, standard model with one key innovation, an entity library. Our results show that this innovation greatly facilitates the identification of infrequent characters. Because of the generic nature of our model, this finding is potentially relevant to any task that requires effective learning from sparse or unbalanced data.