 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Driven Optimization of GPU efficiency for Distributed LLM Adapter Serving
Feb 27, 2026Large Language Model (LLM) adapters enable low-cost model specialization, but introduce complex caching and scheduling challenges in distributed serving systems where hundreds of adapters must be hosted concurrently. While prior work has largely focused on latency minimization, resource efficiency through throughput maximization remains underexplored. This paper presents a data-driven pipeline that, for a given workload, computes an adapter placement that serves the workload with the minimum number of GPUs while avoiding request starvation and GPU memory errors. To that end, the approach identifies the maximum feasible throughput attainable on each GPU by leveraging accurate performance predictions learned from real serving behavior. The proposed pipeline integrates three components: (i) a Digital Twin (DT) tailored to LLM-adapter serving, (ii) a distilled machine learning (ML) model trained on DT-generated data, and (iii) a greedy placement algorithm that exploits ML-based performance estimates to maximize GPU efficiency. The DT emulates real system dynamics with high fidelity, achieving below 5% throughput estimation error while executing up to 90 times faster than full LLM benchmarking across both predictable and unpredictable workloads. The learned ML models further accelerate performance estimation with marginal accuracy degradation, enabling scalable optimization. Experimental results demonstrate that the pipeline substantially improves GPU efficiency by reducing the number of GPUs required to sustain target workloads. Beyond GPU efficiency, the pipeline can be adapted to alternative objectives, such as latency minimization, highlighting its versatility for future large-scale LLM serving infrastructures.
Maximizing GPU Efficiency via Optimal Adapter Caching: An Analytical Approach for Multi-Tenant LLM Serving
Aug 11, 2025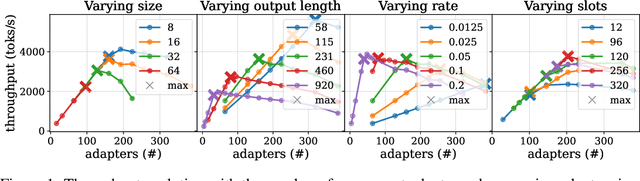
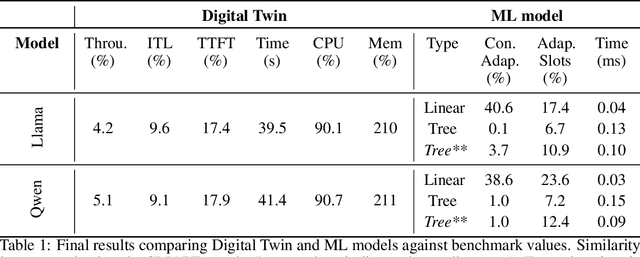
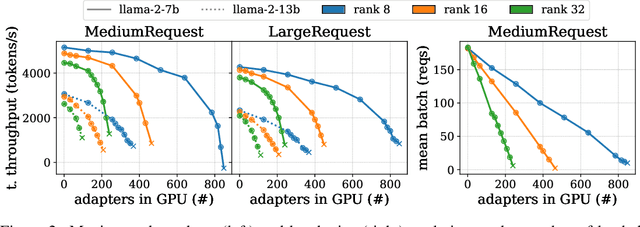
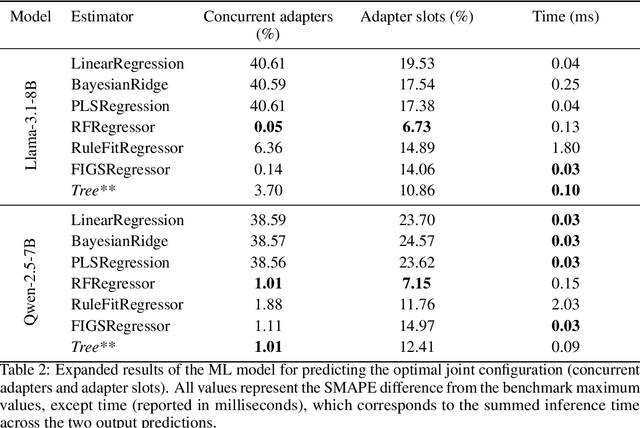
Serving LLM adapters has gained significant attention as an effective approach to adapt general-purpose language models to diverse, task-specific use cases. However, serving a wide range of adapters introduces several and substantial overheads, leading to performance degradation and challenges in optimal placement. To address these challenges, we present an analytical, AI-driven pipeline that accurately determines the optimal allocation of adapters in single-node setups. This allocation maximizes performance, effectively using GPU resources, while preventing request starvation. Crucially, the proposed allocation is given based on current workload patterns. These insights in single-node setups can be leveraged in multi-replica deployments for overall placement, load balancing and server configuration, ultimately enhancing overall performance and improving resource efficiency. Our approach builds on an in-depth analysis of LLM adapter serving, accounting for overheads and performance variability, and includes the development of the first Digital Twin capable of replicating online LLM-adapter serving systems with matching key performance metrics. The experimental results demonstrate that the Digital Twin achieves a SMAPE difference of no more than 5.5% in throughput compared to real results, and the proposed pipeline accurately predicts the optimal placement with minimal latency.
In-Context Bias Propagation in LLM-Based Tabular Data Generation
Jun 11, 2025Large Language Models (LLMs) are increasingly used for synthetic tabular data generation through in-context learning (ICL), offering a practical solution for data augmentation in data scarce scenarios. While prior work has shown the potential of LLMs to improve downstream task performance through augmenting underrepresented groups, these benefits often assume access to a subset of unbiased in-context examples, representative of the real dataset. In real-world settings, however, data is frequently noisy and demographically skewed. In this paper, we systematically study how statistical biases within in-context examples propagate to the distribution of synthetic tabular data, showing that even mild in-context biases lead to global statistical distortions. We further introduce an adversarial scenario where a malicious contributor can inject bias into the synthetic dataset via a subset of in-context examples, ultimately compromising the fairness of downstream classifiers for a targeted and protected subgroup. Our findings demonstrate a new vulnerability associated with LLM-based data generation pipelines that rely on in-context prompts with in sensitive domains.
Mind the Memory Gap: Unveiling GPU Bottlenecks in Large-Batch LLM Inference
Mar 11, 2025Large language models have been widely adopted across different tasks, but their auto-regressive generation nature often leads to inefficient resource utilization during inference. While batching is commonly used to increase throughput, performance gains plateau beyond a certain batch size, especially with smaller models, a phenomenon that existing literature typically explains as a shift to the compute-bound regime. In this paper, through an in-depth GPU-level analysis, we reveal that large-batch inference remains memory-bound, with most GPU compute capabilities underutilized due to DRAM bandwidth saturation as the primary bottleneck. To address this, we propose a Batching Configuration Advisor (BCA) that optimizes memory allocation, reducing GPU memory requirements with minimal impact on throughput. The freed memory and underutilized GPU compute capabilities can then be leveraged by concurrent workloads. Specifically, we use model replication to improve serving throughput and GPU utilization. Our findings challenge conventional assumptions about LLM inference, offering new insights and practical strategies for improving resource utilization, particularly for smaller language models.
FRIDA: Free-Rider Detection using Privacy Attacks
Oct 07, 2024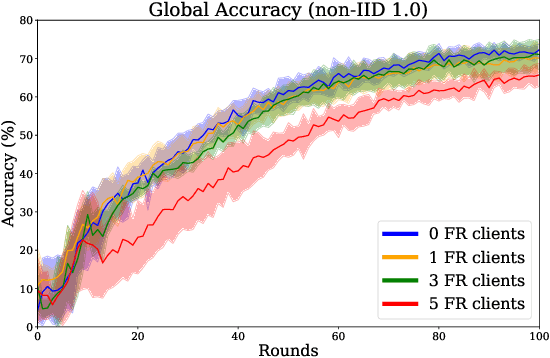
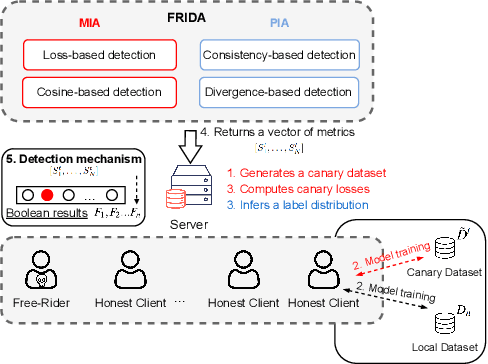
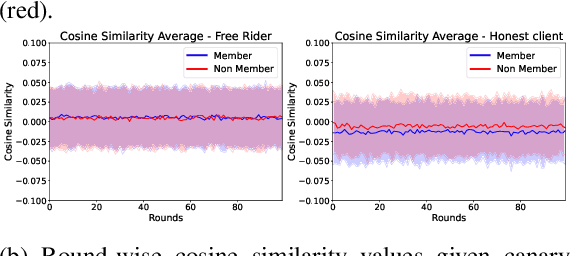
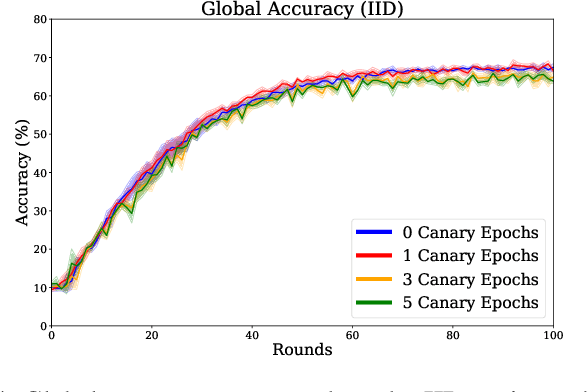
Federated learning is increasingly popular as it enables multiple parties with limited datasets and resources to train a high-performing machine learning model collaboratively. However, similarly to other collaborative systems, federated learning is vulnerable to free-riders -- participants who do not contribute to the training but still benefit from the shared model. Free-riders not only compromise the integrity of the learning process but also slow down the convergence of the global model, resulting in increased costs for the honest participants. To address this challenge, we propose FRIDA: free-rider detection using privacy attacks, a framework that leverages inference attacks to detect free-riders. Unlike traditional methods that only capture the implicit effects of free-riding, FRIDA directly infers details of the underlying training datasets, revealing characteristics that indicate free-rider behaviour. Through extensive experiments, we demonstrate that membership and property inference attacks are effective for this purpose. Our evaluation shows that FRIDA outperforms state-of-the-art methods, especially in non-IID settings.
Towards Pareto Optimal Throughput in Small Language Model Serving
Apr 04, 2024Large language models (LLMs) have revolutionized the state-of-the-art of many different natural language processing tasks. Although serving LLMs is computationally and memory demanding, the rise of Small Language Models (SLMs) offers new opportunities for resource-constrained users, who now are able to serve small models with cutting-edge performance. In this paper, we present a set of experiments designed to benchmark SLM inference at performance and energy levels. Our analysis provides a new perspective in serving, highlighting that the small memory footprint of SLMs allows for reaching the Pareto-optimal throughput within the resource capacity of a single accelerator. In this regard, we present an initial set of findings demonstrating how model replication can effectively improve resource utilization for serving SLMs.
Sign Language Translation from Instructional Videos
Apr 14, 2023



The advances in automatic sign language translation (SLT) to spoken languages have been mostly benchmarked with datasets of limited size and restricted domains. Our work advances the state of the art by providing the first baseline results on How2Sign, a large and broad dataset. We train a Transformer over I3D video features, using the reduced BLEU as a reference metric for validation, instead of the widely used BLEU score. We report a result of 8.03 on the BLEU score, and publish the first open-source implementation of its kind to promote further advances.
Tackling Low-Resourced Sign Language Translation: UPC at WMT-SLT 22
Dec 02, 2022This paper describes the system developed at the Universitat Polit\`ecnica de Catalunya for the Workshop on Machine Translation 2022 Sign Language Translation Task, in particular, for the sign-to-text direction. We use a Transformer model implemented with the Fairseq modeling toolkit. We have experimented with the vocabulary size, data augmentation techniques and pretraining the model with the PHOENIX-14T dataset. Our system obtains 0.50 BLEU score for the test set, improving the organizers' baseline by 0.38 BLEU. We remark the poor results for both the baseline and our system, and thus, the unreliability of our findings.
Topic Detection in Continuous Sign Language Videos
Sep 01, 2022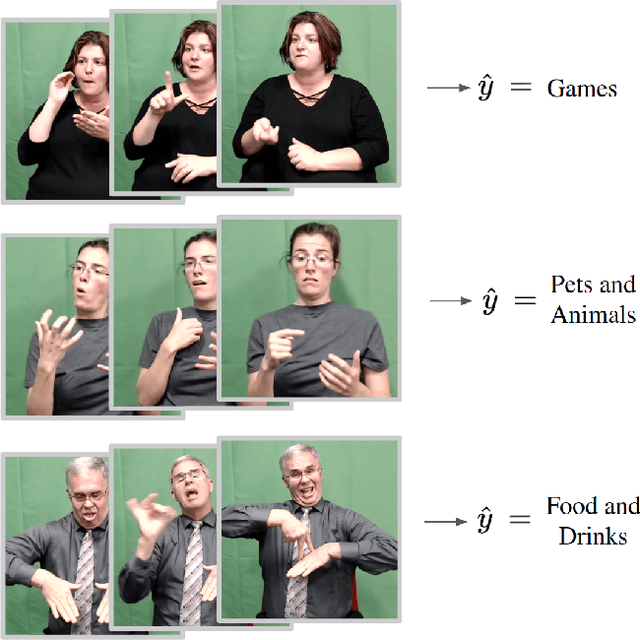
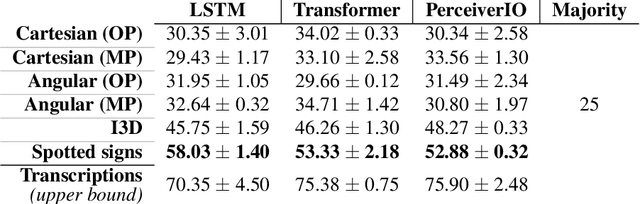
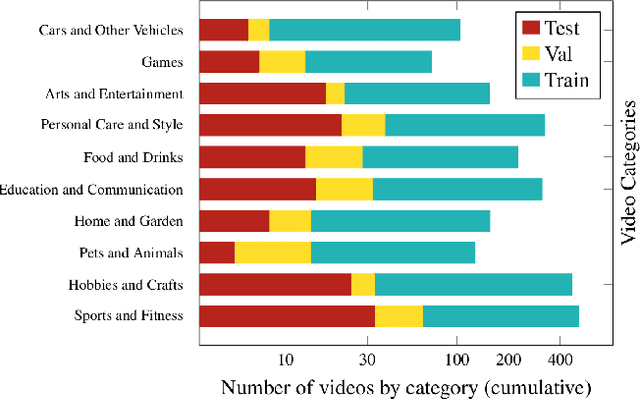
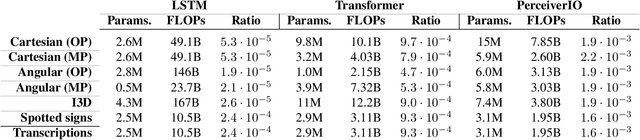
Significant progress has been made recently on challenging tasks in automatic sign language understanding, such as sign language recognition, translation and production. However, these works have focused on datasets with relatively few samples, short recordings and limited vocabulary and signing space. In this work, we introduce the novel task of sign language topic detection. We base our experiments on How2Sign, a large-scale video dataset spanning multiple semantic domains. We provide strong baselines for the task of topic detection and present a comparison between different visual features commonly used in the domain of sign language.
* Presented as an extended abstract in the "AVA: Accessibility, Vision, and Autonomy Meet" CVPR 2022 Workshop
Distributing Deep Learning Hyperparameter Tuning for 3D Medical Image Segmentation
Oct 29, 2021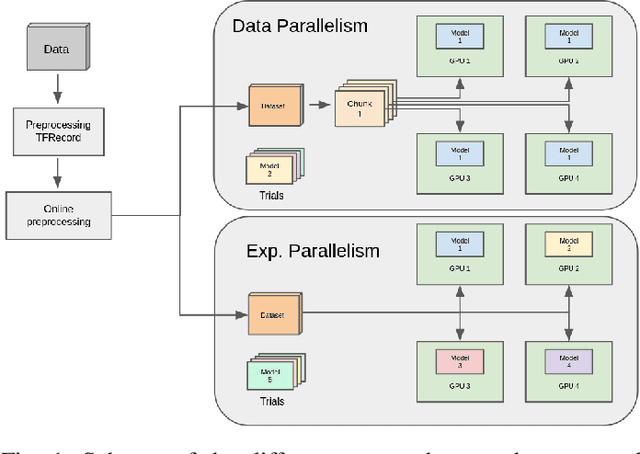
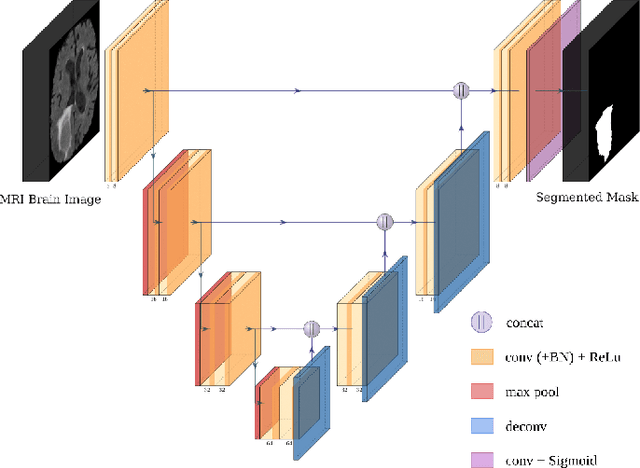
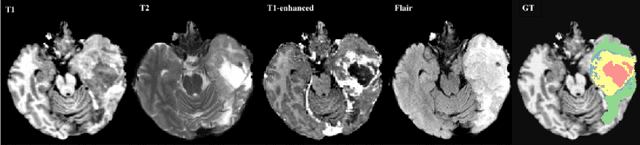
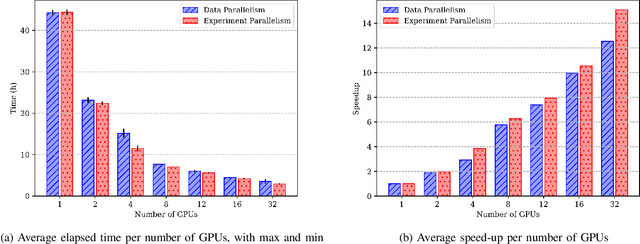
Most research on novel techniques for 3D Medical Image Segmentation (MIS) is currently done using Deep Learning with GPU accelerators. The principal challenge of such technique is that a single input can easily cope computing resources, and require prohibitive amounts of time to be processed. Distribution of deep learning and scalability over computing devices is an actual need for progressing on such research field. Conventional distribution of neural networks consist in data parallelism, where data is scattered over resources (e.g., GPUs) to parallelize the training of the model. However, experiment parallelism is also an option, where different training processes are parallelized across resources. While the first option is much more common on 3D image segmentation, the second provides a pipeline design with less dependence among parallelized processes, allowing overhead reduction and more potential scalability. In this work we present a design for distributed deep learning training pipelines, focusing on multi-node and multi-GPU environments, where the two different distribution approaches are deployed and benchmarked. We take as proof of concept the 3D U-Net architecture, using the MSD Brain Tumor Segmentation dataset, a state-of-art problem in medical image segmentation with high computing and space requirements. Using the BSC MareNostrum supercomputer as benchmarking environment, we use TensorFlow and Ray as neural network training and experiment distribution platforms. We evaluate the experiment speed-up, showing the potential for scaling out on GPUs and nodes. Also comparing the different parallelism techniques, showing how experiment distribution leverages better such resources through scaling. Finally, we provide the implementation of the design open to the community, and the non-trivial steps and methodology for adapting and deploying a MIS case as the here presented.