 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-guided sample selection for Semi-Supervised Instance Segmentation
Paper and Code
Aug 25, 2020


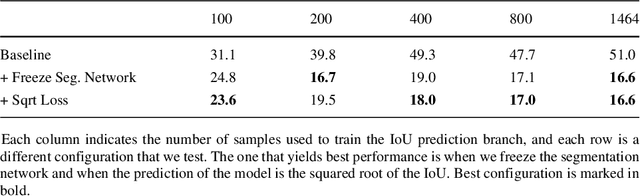
Image segmentation methods are usually trained with pixel-level annotations, which require significant human effort to collect. The most common solution to address this constraint is to implement weakly-supervised pipelines trained with lower forms of supervision, such as bounding boxes or scribbles. Another option are semi-supervised methods, which leverage a large amount of unlabeled data and a limited number of strongly-labeled samples. In this second setup, samples to be strongly-annotated can be selected randomly or with an active learning mechanism that chooses the ones that will maximize the model performance. In this work, we propose a sample selection approach to decide which samples to annotate for semi-supervised instance segmentation. Our method consists in first predicting pseudo-masks for the unlabeled pool of samples, together with a score predicting the quality of the mask. This score is an estimate of the Intersection Over Union (IoU) of the segment with the ground truth mask. We study which samples are better to annotate given the quality score, and show how our approach outperforms a random selection, leading to improved performance for semi-supervised instance segmentation with low annotation budgets.