 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning for Feature Shift Detection and Correction
Dec 07, 2023



Data shift is a phenomenon present in many real-world applications, and while there are multiple methods attempting to detect shifts, the task of localizing and correcting the features originating such shifts has not been studied in depth. Feature shifts can occur in many datasets, including in multi-sensor data, where some sensors are malfunctioning, or in tabular and structured data, including biomedical, financial, and survey data, where faulty standardization and data processing pipelines can lead to erroneous features. In this work, we explore using the principles of adversarial learning, where the information from several discriminators trained to distinguish between two distributions is used to both detect the corrupted features and fix them in order to remove the distribution shift between datasets. We show that mainstream supervised classifiers, such as random forest or gradient boosting trees, combined with simple iterative heuristics, can localize and correct feature shifts, outperforming current statistical and neural network-based techniques. The code is available at https://github.com/AI-sandbox/DataFix.
Towards Robust Image-in-Audio Deep Steganography
Mar 14, 2023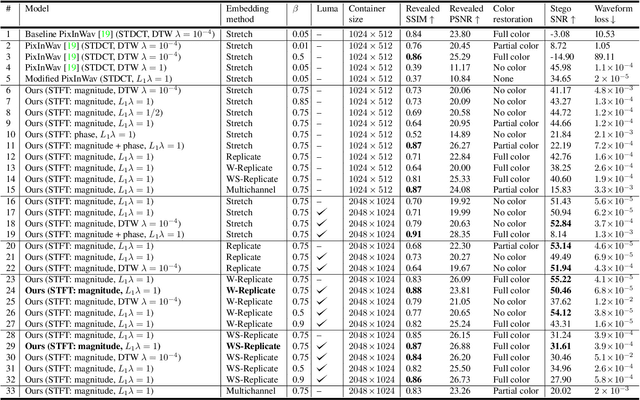
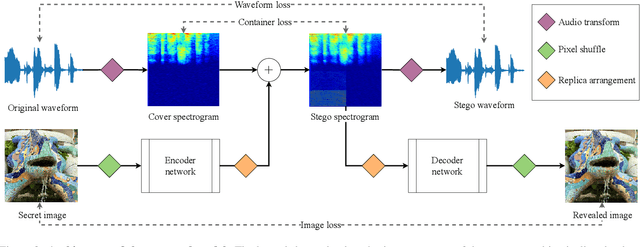
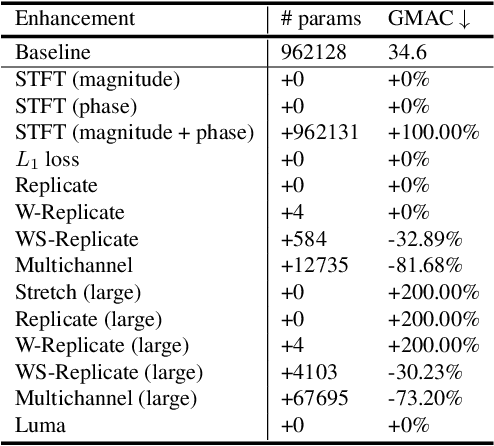

The field of steganography has experienced a surge of interest due to the recent advancements in AI-powered techniques, particularly in the context of multimodal setups that enable the concealment of signals within signals of a different nature. The primary objectives of all steganographic methods are to achieve perceptual transparency, robustness, and large embedding capacity - which often present conflicting goals that classical methods have struggled to reconcile. This paper extends and enhances an existing image-in-audio deep steganography method by focusing on improving its robustness. The proposed enhancements include modifications to the loss function, utilization of the Short-Time Fourier Transform (STFT), introduction of redundancy in the encoding process for error correction, and buffering of additional information in the pixel subconvolution operation. The results demonstrate that our approach outperforms the existing method in terms of robustness and perceptual transparency.
SIRA: Relightable Avatars from a Single Image
Sep 07, 2022
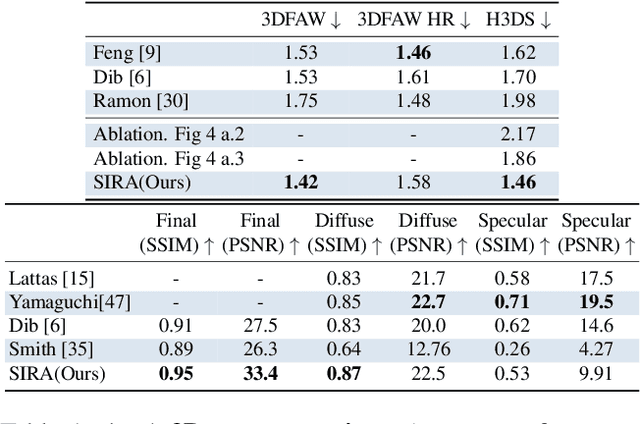


Recovering the geometry of a human head from a single image, while factorizing the materials and illumination is a severely ill-posed problem that requires prior information to be solved. Methods based on 3D Morphable Models (3DMM), and their combination with differentiable renderers, have shown promising results. However, the expressiveness of 3DMMs is limited, and they typically yield over-smoothed and identity-agnostic 3D shapes limited to the face region. Highly accurate full head reconstructions have recently been obtained with neural fields that parameterize the geometry using multilayer perceptrons. The versatility of these representations has also proved effective for disentangling geometry, materials and lighting. However, these methods require several tens of input images. In this paper, we introduce SIRA, a method which, from a single image, reconstructs human head avatars with high fidelity geometry and factorized lights and surface materials. Our key ingredients are two data-driven statistical models based on neural fields that resolve the ambiguities of single-view 3D surface reconstruction and appearance factorization. Experiments show that SIRA obtains state of the art results in 3D head reconstruction while at the same time it successfully disentangles the global illumination, and the diffuse and specular albedos. Furthermore, our reconstructions are amenable to physically-based appearance editing and head model relighting.
Topic Detection in Continuous Sign Language Videos
Sep 01, 2022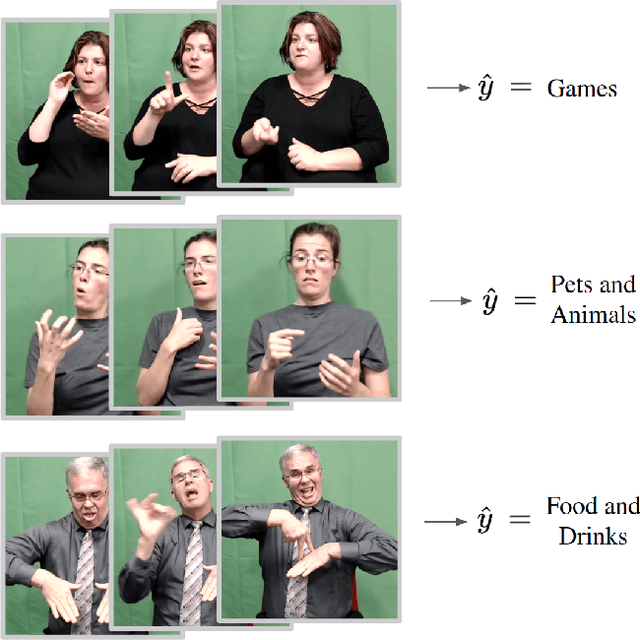
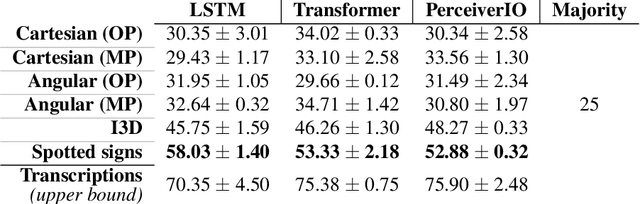
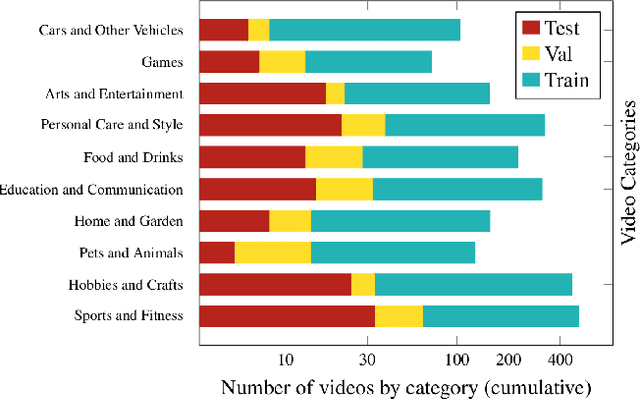
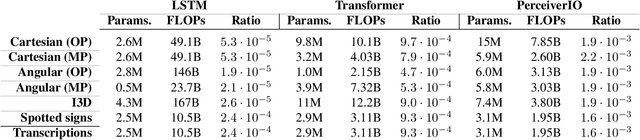
Significant progress has been made recently on challenging tasks in automatic sign language understanding, such as sign language recognition, translation and production. However, these works have focused on datasets with relatively few samples, short recordings and limited vocabulary and signing space. In this work, we introduce the novel task of sign language topic detection. We base our experiments on How2Sign, a large-scale video dataset spanning multiple semantic domains. We provide strong baselines for the task of topic detection and present a comparison between different visual features commonly used in the domain of sign language.
* Presented as an extended abstract in the "AVA: Accessibility, Vision, and Autonomy Meet" CVPR 2022 Workshop
H3D-Net: Few-Shot High-Fidelity 3D Head Reconstruction
Jul 26, 2021
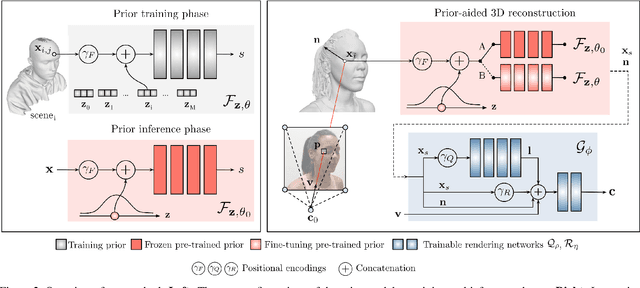


Recent learning approaches that implicitly represent surface geometry using coordinate-based neural representations have shown impressive results in the problem of multi-view 3D reconstruction. The effectiveness of these techniques is, however, subject to the availability of a large number (several tens) of input views of the scene, and computationally demanding optimizations. In this paper, we tackle these limitations for the specific problem of few-shot full 3D head reconstruction, by endowing coordinate-based representations with a probabilistic shape prior that enables faster convergence and better generalization when using few input images (down to three). First, we learn a shape model of 3D heads from thousands of incomplete raw scans using implicit representations. At test time, we jointly overfit two coordinate-based neural networks to the scene, one modeling the geometry and another estimating the surface radiance, using implicit differentiable rendering. We devise a two-stage optimization strategy in which the learned prior is used to initialize and constrain the geometry during an initial optimization phase. Then, the prior is unfrozen and fine-tuned to the scene. By doing this, we achieve high-fidelity head reconstructions, including hair and shoulders, and with a high level of detail that consistently outperforms both state-of-the-art 3D Morphable Models methods in the few-shot scenario, and non-parametric methods when large sets of views are available.
Unsupervised Skill-Discovery and Skill-Learning in Minecraft
Jul 18, 2021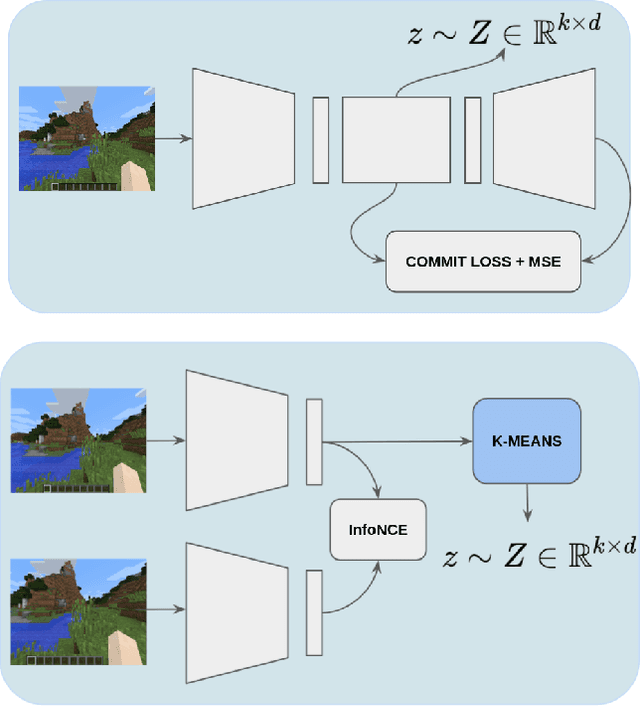
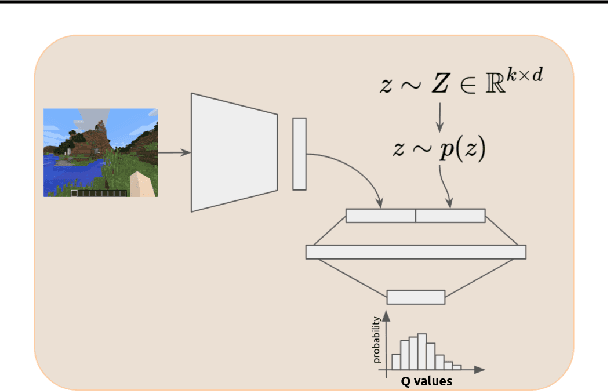


Pre-training Reinforcement Learning agents in a task-agnostic manner has shown promising results. However, previous works still struggle in learning and discovering meaningful skills in high-dimensional state-spaces, such as pixel-spaces. We approach the problem by leveraging unsupervised skill discovery and self-supervised learning of state representations. In our work, we learn a compact latent representation by making use of variational and contrastive techniques. We demonstrate that both enable RL agents to learn a set of basic navigation skills by maximizing an information theoretic objective. We assess our method in Minecraft 3D pixel maps with different complexities. Our results show that representations and conditioned policies learned from pixels are enough for toy examples, but do not scale to realistic and complex maps. To overcome these limitations, we explore alternative input observations such as the relative position of the agent along with the raw pixels.
PixInWav: Residual Steganography for Hiding Pixels in Audio
Jun 17, 2021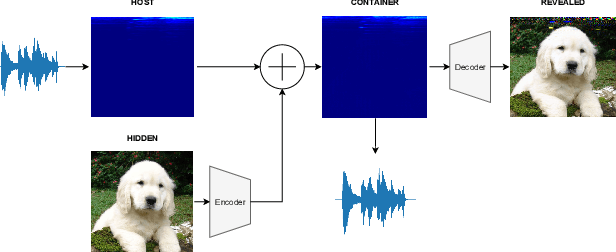



Steganography comprises the mechanics of hiding data in a host media that may be publicly available. While previous works focused on unimodal setups (e.g., hiding images in images, or hiding audio in audio), PixInWav targets the multimodal case of hiding images in audio. To this end, we propose a novel residual architecture operating on top of short-time discrete cosine transform (STDCT) audio spectrograms. Among our results, we find that the residual audio steganography setup we propose allows independent encoding of the hidden image from the host audio without compromising quality. Accordingly, while previous works require both host and hidden signals to hide a signal, PixInWav can encode images offline -- which can be later hidden, in a residual fashion, into any audio signal. Finally, we test our scheme in a lab setting to transmit images over airwaves from a loudspeaker to a microphone verifying our theoretical insights and obtaining promising results.
SynthRef: Generation of Synthetic Referring Expressions for Object Segmentation
Jun 09, 2021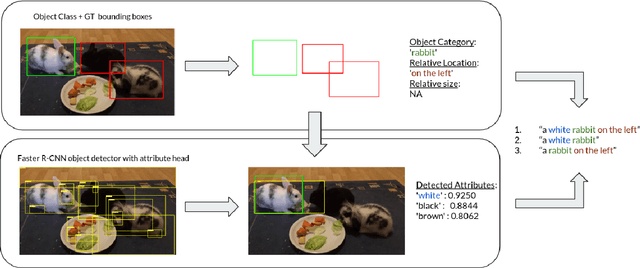



Recent advances in deep learning have brought significant progress in visual grounding tasks such as language-guided video object segmentation. However, collecting large datasets for these tasks is expensive in terms of annotation time, which represents a bottleneck. To this end, we propose a novel method, namely SynthRef, for generating synthetic referring expressions for target objects in an image (or video frame), and we also present and disseminate the first large-scale dataset with synthetic referring expressions for video object segmentation. Our experiments demonstrate that by training with our synthetic referring expressions one can improve the ability of a model to generalize across different datasets, without any additional annotation cost. Moreover, our formulation allows its application to any object detection or segmentation dataset.
Seasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data
Mar 30, 2021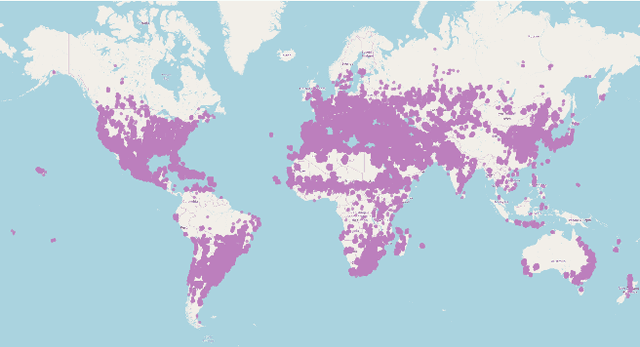
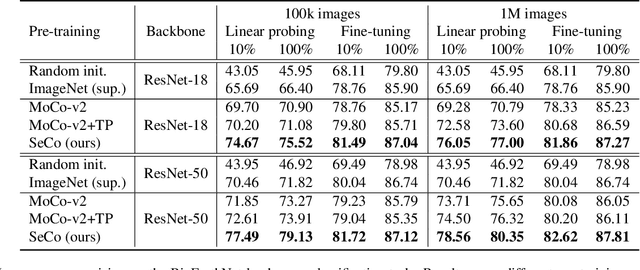
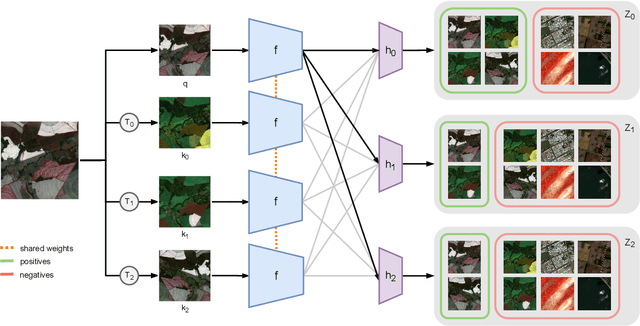

Remote sensing and automatic earth monitoring are key to solve global-scale challenges such as disaster prevention, land use monitoring, or tackling climate change. Although there exist vast amounts of remote sensing data, most of it remains unlabeled and thus inaccessible for supervised learning algorithms. Transfer learning approaches can reduce the data requirements of deep learning algorithms. However, most of these methods are pre-trained on ImageNet and their generalization to remote sensing imagery is not guaranteed due to the domain gap. In this work, we propose Seasonal Contrast (SeCo), an effective pipeline to leverage unlabeled data for in-domain pre-training of re-mote sensing representations. The SeCo pipeline is com-posed of two parts. First, a principled procedure to gather large-scale, unlabeled and uncurated remote sensing datasets containing images from multiple Earth locations at different timestamps. Second, a self-supervised algorithm that takes advantage of time and position invariance to learn transferable representations for re-mote sensing applications. We empirically show that models trained with SeCo achieve better performance than their ImageNet pre-trained counterparts and state-of-the-art self-supervised learning methods on multiple downstream tasks. The datasets and models in SeCo will be made public to facilitate transfer learning and enable rapid progress in re-mote sensing applications.
Can Everybody Sign Now? Exploring Sign Language Video Generation from 2D Poses
Jan 04, 2021



Recent work have addressed the generation of human poses represented by 2D/3D coordinates of human joints for sign language. We use the state of the art in Deep Learning for motion transfer and evaluate them on How2Sign, an American Sign Language dataset, to generate videos of signers performing sign language given a 2D pose skeleton. We evaluate the generated videos quantitatively and qualitatively showing that the current models are not enough to generated adequate videos for Sign Language due to lack of detail in hands.