 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Skill-Discovery and Skill-Learning in Minecraft
Jul 18, 2021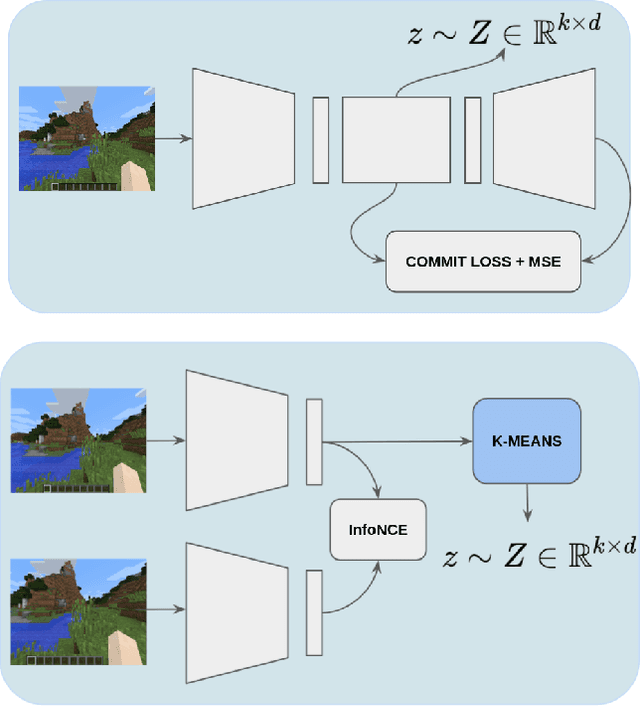
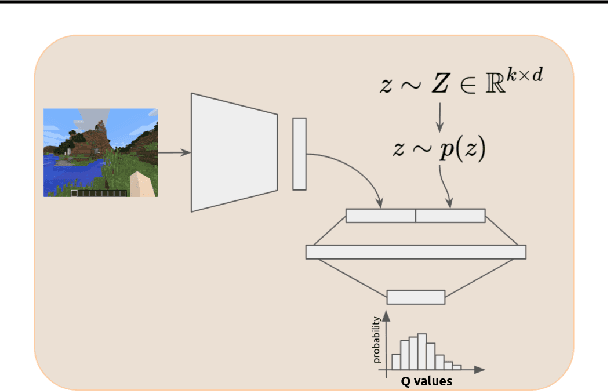


Pre-training Reinforcement Learning agents in a task-agnostic manner has shown promising results. However, previous works still struggle in learning and discovering meaningful skills in high-dimensional state-spaces, such as pixel-spaces. We approach the problem by leveraging unsupervised skill discovery and self-supervised learning of state representations. In our work, we learn a compact latent representation by making use of variational and contrastive techniques. We demonstrate that both enable RL agents to learn a set of basic navigation skills by maximizing an information theoretic objective. We assess our method in Minecraft 3D pixel maps with different complexities. Our results show that representations and conditioned policies learned from pixels are enough for toy examples, but do not scale to realistic and complex maps. To overcome these limitations, we explore alternative input observations such as the relative position of the agent along with the raw pixels.
MT-Adapted Datasheets for Datasets: Template and Repository
May 27, 2020
In this report we are taking the standardized model proposed by Gebru et al. (2018) for documenting the popular machine translation datasets of the EuroParl (Koehn, 2005) and News-Commentary (Barrault et al., 2019). Within this documentation process, we have adapted the original datasheet to the particular case of data consumers within the Machine Translation area. We are also proposing a repository for collecting the adapted datasheets in this research area