 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioMiXR: Spatial Audio Object Manipulation with 6DoF for Sound Design in Augmented Reality
Feb 05, 2025



We present AudioMiXR, an augmented reality (AR) interface intended to assess how users manipulate virtual audio objects situated in their physical space using six degrees of freedom (6DoF) deployed on a head-mounted display (Apple Vision Pro) for 3D sound design. Existing tools for 3D sound design are typically constrained to desktop displays, which may limit spatial awareness of mixing within the execution environment. Utilizing an XR HMD to create soundscapes may provide a real-time test environment for 3D sound design, as modern HMDs can provide precise spatial localization assisted by cross-modal interactions. However, there is no research on design guidelines specific to sound design with six degrees of freedom (6DoF) in XR. To provide a first step toward identifying design-related research directions in this space, we conducted an exploratory study where we recruited 27 participants, consisting of expert and non-expert sound designers. The goal was to assess design lessons that can be used to inform future research venues in 3D sound design. We ran a within-subjects study where users designed both a music and cinematic soundscapes. After thematically analyzing participant data, we constructed two design lessons: 1. Proprioception for AR Sound Design, and 2. Balancing Audio-Visual Modalities in AR GUIs. Additionally, we provide application domains that can benefit most from 6DoF sound design based on our results.
Adversarial Learning for Feature Shift Detection and Correction
Dec 07, 2023



Data shift is a phenomenon present in many real-world applications, and while there are multiple methods attempting to detect shifts, the task of localizing and correcting the features originating such shifts has not been studied in depth. Feature shifts can occur in many datasets, including in multi-sensor data, where some sensors are malfunctioning, or in tabular and structured data, including biomedical, financial, and survey data, where faulty standardization and data processing pipelines can lead to erroneous features. In this work, we explore using the principles of adversarial learning, where the information from several discriminators trained to distinguish between two distributions is used to both detect the corrupted features and fix them in order to remove the distribution shift between datasets. We show that mainstream supervised classifiers, such as random forest or gradient boosting trees, combined with simple iterative heuristics, can localize and correct feature shifts, outperforming current statistical and neural network-based techniques. The code is available at https://github.com/AI-sandbox/DataFix.
Maestro: A Gamified Platform for Teaching AI Robustness
Jun 14, 2023Although the prevention of AI vulnerabilities is critical to preserve the safety and privacy of users and businesses, educational tools for robust AI are still underdeveloped worldwide. We present the design, implementation, and assessment of Maestro. Maestro is an effective open-source game-based platform that contributes to the advancement of robust AI education. Maestro provides goal-based scenarios where college students are exposed to challenging life-inspired assignments in a competitive programming environment. We assessed Maestro's influence on students' engagement, motivation, and learning success in robust AI. This work also provides insights into the design features of online learning tools that promote active learning opportunities in the robust AI domain. We analyzed the reflection responses (measured with Likert scales) of 147 undergraduate students using Maestro in two quarterly college courses in AI. According to the results, students who felt the acquisition of new skills in robust AI tended to appreciate highly Maestro and scored highly on material consolidation, curiosity, and mastery in robust AI. Moreover, the leaderboard, our key gamification element in Maestro, has effectively contributed to students' engagement and learning. Results also indicate that Maestro can be effectively adapted to any course length and depth without losing its educational quality.
Towards Robust Image-in-Audio Deep Steganography
Mar 14, 2023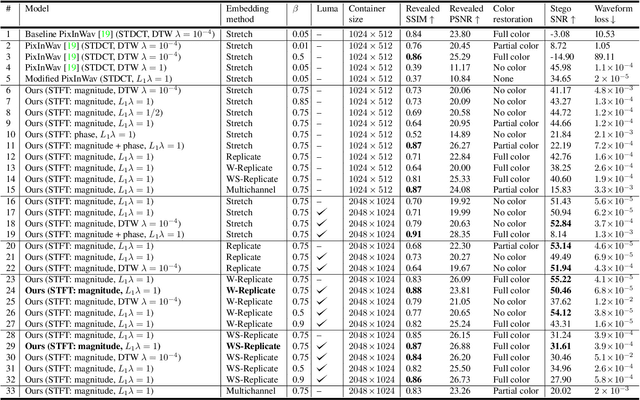
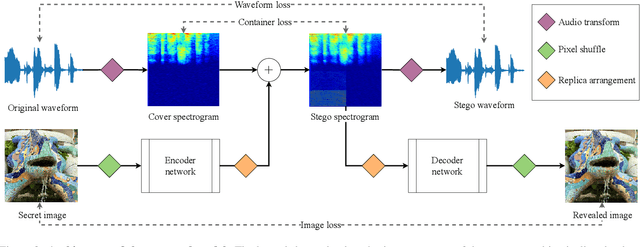
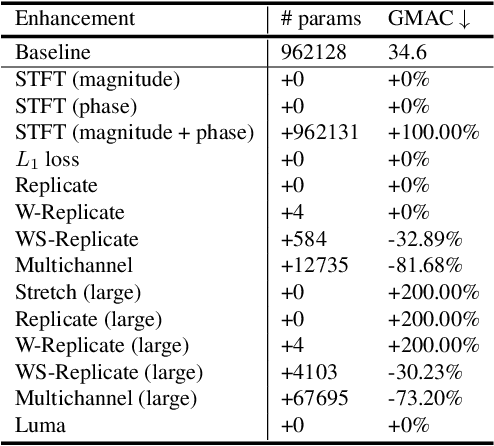

The field of steganography has experienced a surge of interest due to the recent advancements in AI-powered techniques, particularly in the context of multimodal setups that enable the concealment of signals within signals of a different nature. The primary objectives of all steganographic methods are to achieve perceptual transparency, robustness, and large embedding capacity - which often present conflicting goals that classical methods have struggled to reconcile. This paper extends and enhances an existing image-in-audio deep steganography method by focusing on improving its robustness. The proposed enhancements include modifications to the loss function, utilization of the Short-Time Fourier Transform (STFT), introduction of redundancy in the encoding process for error correction, and buffering of additional information in the pixel subconvolution operation. The results demonstrate that our approach outperforms the existing method in terms of robustness and perceptual transparency.
PixInWav: Residual Steganography for Hiding Pixels in Audio
Jun 17, 2021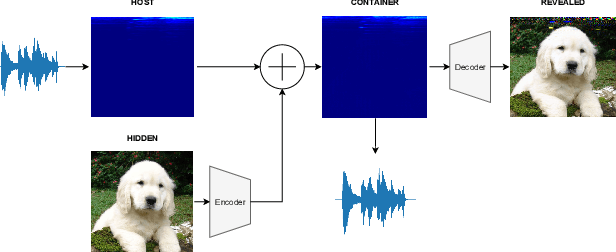



Steganography comprises the mechanics of hiding data in a host media that may be publicly available. While previous works focused on unimodal setups (e.g., hiding images in images, or hiding audio in audio), PixInWav targets the multimodal case of hiding images in audio. To this end, we propose a novel residual architecture operating on top of short-time discrete cosine transform (STDCT) audio spectrograms. Among our results, we find that the residual audio steganography setup we propose allows independent encoding of the hidden image from the host audio without compromising quality. Accordingly, while previous works require both host and hidden signals to hide a signal, PixInWav can encode images offline -- which can be later hidden, in a residual fashion, into any audio signal. Finally, we test our scheme in a lab setting to transmit images over airwaves from a loudspeaker to a microphone verifying our theoretical insights and obtaining promising results.
MT-Adapted Datasheets for Datasets: Template and Repository
May 27, 2020
In this report we are taking the standardized model proposed by Gebru et al. (2018) for documenting the popular machine translation datasets of the EuroParl (Koehn, 2005) and News-Commentary (Barrault et al., 2019). Within this documentation process, we have adapted the original datasheet to the particular case of data consumers within the Machine Translation area. We are also proposing a repository for collecting the adapted datasheets in this research area