 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Guidance for Controllable Latent Audio Diffusion
Mar 04, 2026Generative audio requires fine-grained controllable outputs, yet most existing methods require model retraining on specific controls or inference-time controls (\textit{e.g.}, guidance) that can also be computationally demanding. By examining the bottlenecks of existing guidance-based controls, in particular their high cost-per-step due to decoder backpropagation, we introduce a guidance-based approach through selective TFG and Latent-Control Heads (LatCHs), which enables controlling latent audio diffusion models with low computational overhead. LatCHs operate directly in latent space, avoiding the expensive decoder step, and requiring minimal training resources (7M parameters and $\approx$ 4 hours of training). Experiments with Stable Audio Open demonstrate effective control over intensity, pitch, and beats (and a combination of those) while maintaining generation quality. Our method balances precision and audio fidelity with far lower computational costs than standard end-to-end guidance. Demo examples can be found at https://zacharynovack.github.io/latch/latch.html.
Fast Text-to-Audio Generation with Adversarial Post-Training
May 14, 2025Text-to-audio systems, while increasingly performant, are slow at inference time, thus making their latency unpractical for many creative applications. We present Adversarial Relativistic-Contrastive (ARC) post-training, the first adversarial acceleration algorithm for diffusion/flow models not based on distillation. While past adversarial post-training methods have struggled to compare against their expensive distillation counterparts, ARC post-training is a simple procedure that (1) extends a recent relativistic adversarial formulation to diffusion/flow post-training and (2) combines it with a novel contrastive discriminator objective to encourage better prompt adherence. We pair ARC post-training with a number optimizations to Stable Audio Open and build a model capable of generating $\approx$12s of 44.1kHz stereo audio in $\approx$75ms on an H100, and $\approx$7s on a mobile edge-device, the fastest text-to-audio model to our knowledge.
Scaling Transformers for Low-Bitrate High-Quality Speech Coding
Nov 29, 2024



The tokenization of speech with neural audio codec models is a vital part of modern AI pipelines for the generation or understanding of speech, alone or in a multimodal context. Traditionally such tokenization models have concentrated on low parameter-count architectures using only components with strong inductive biases. In this work we show that by scaling a transformer architecture with large parameter count to this problem, and applying a flexible Finite Scalar Quantization (FSQ) based bottleneck, it is possible to reach state-of-the-art speech quality at extremely low bit-rates of $400$ or $700$ bits-per-second. The trained models strongly out-perform existing baselines in both objective and subjective tests.
Stable Audio Open
Jul 19, 2024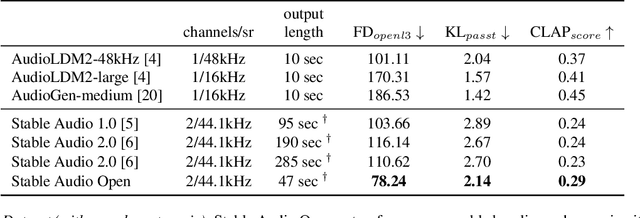
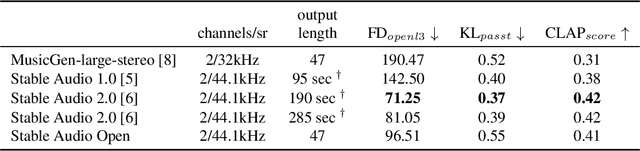
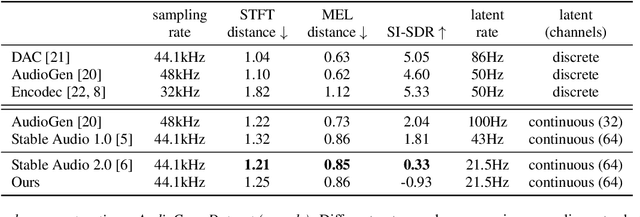
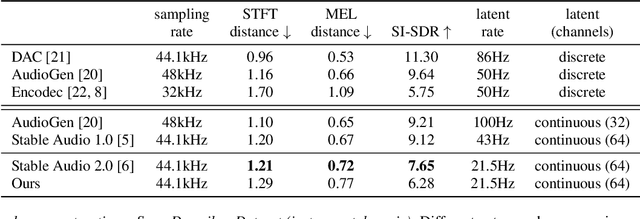
Open generative models are vitally important for the community, allowing for fine-tunes and serving as baselines when presenting new models. However, most current text-to-audio models are private and not accessible for artists and researchers to build upon. Here we describe the architecture and training process of a new open-weights text-to-audio model trained with Creative Commons data. Our evaluation shows that the model's performance is competitive with the state-of-the-art across various metrics. Notably, the reported FDopenl3 results (measuring the realism of the generations) showcase its potential for high-quality stereo sound synthesis at 44.1kHz.
Long-form music generation with latent diffusion
Apr 16, 2024Audio-based generative models for music have seen great strides recently, but so far have not managed to produce full-length music tracks with coherent musical structure. We show that by training a generative model on long temporal contexts it is possible to produce long-form music of up to 4m45s. Our model consists of a diffusion-transformer operating on a highly downsampled continuous latent representation (latent rate of 21.5Hz). It obtains state-of-the-art generations according to metrics on audio quality and prompt alignment, and subjective tests reveal that it produces full-length music with coherent structure.
Fast Timing-Conditioned Latent Audio Diffusion
Feb 08, 2024Generating long-form 44.1kHz stereo audio from text prompts can be computationally demanding. Further, most previous works do not tackle that music and sound effects naturally vary in their duration. Our research focuses on the efficient generation of long-form, variable-length stereo music and sounds at 44.1kHz using text prompts with a generative model. Stable Audio is based on latent diffusion, with its latent defined by a fully-convolutional variational autoencoder. It is conditioned on text prompts as well as timing embeddings, allowing for fine control over both the content and length of the generated music and sounds. Stable Audio is capable of rendering stereo signals of up to 95 sec at 44.1kHz in 8 sec on an A100 GPU. Despite its compute efficiency and fast inference, it is one of the best in two public text-to-music and -audio benchmarks and, differently from state-of-the-art models, can generate music with structure and stereo sounds.
GASS: Generalizing Audio Source Separation with Large-scale Data
Sep 29, 2023
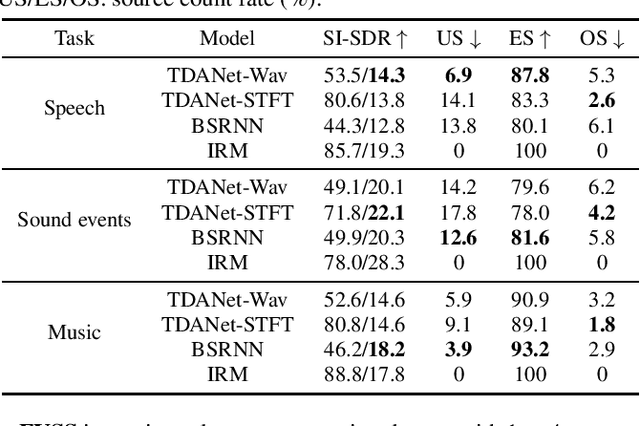
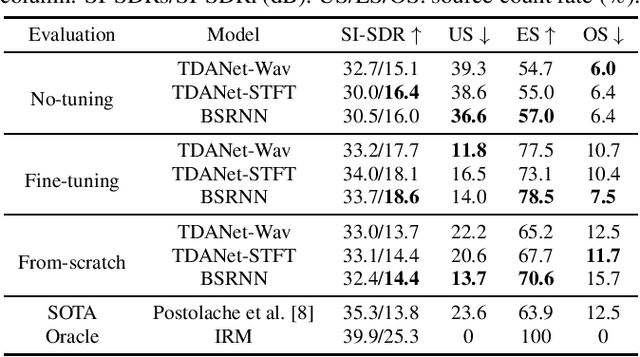
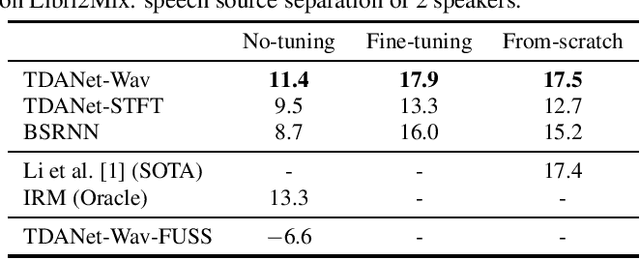
Universal source separation targets at separating the audio sources of an arbitrary mix, removing the constraint to operate on a specific domain like speech or music. Yet, the potential of universal source separation is limited because most existing works focus on mixes with predominantly sound events, and small training datasets also limit its potential for supervised learning. Here, we study a single general audio source separation (GASS) model trained to separate speech, music, and sound events in a supervised fashion with a large-scale dataset. We assess GASS models on a diverse set of tasks. Our strong in-distribution results show the feasibility of GASS models, and the competitive out-of-distribution performance in sound event and speech separation shows its generalization abilities. Yet, it is challenging for GASS models to generalize for separating out-of-distribution cinematic and music content. We also fine-tune GASS models on each dataset and consistently outperform the ones without pre-training. All fine-tuned models (except the music separation one) obtain state-of-the-art results in their respective benchmarks.
Mono-to-stereo through parametric stereo generation
Jun 26, 2023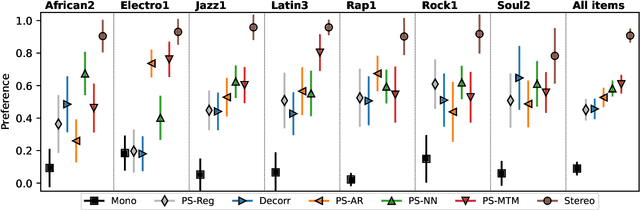
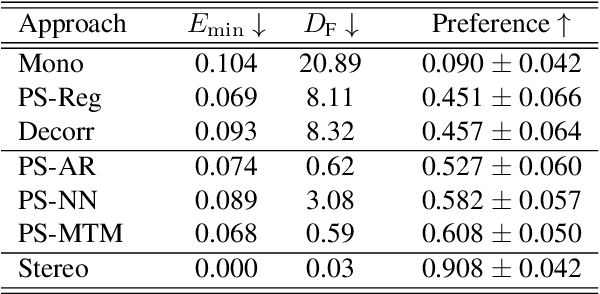
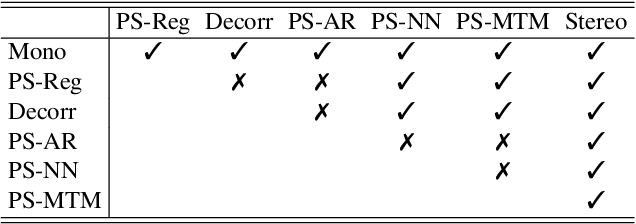
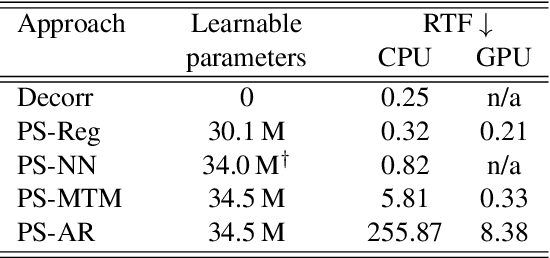
Generating a stereophonic presentation from a monophonic audio signal is a challenging open task, especially if the goal is to obtain a realistic spatial imaging with a specific panning of sound elements. In this work, we propose to convert mono to stereo by means of predicting parametric stereo (PS) parameters using both nearest neighbor and deep network approaches. In combination with PS, we also propose to model the task with generative approaches, allowing to synthesize multiple and equally-plausible stereo renditions from the same mono signal. To achieve this, we consider both autoregressive and masked token modelling approaches. We provide evidence that the proposed PS-based models outperform a competitive classical decorrelation baseline and that, within a PS prediction framework, modern generative models outshine equivalent non-generative counterparts. Overall, our work positions both PS and generative modelling as strong and appealing methodologies for mono-to-stereo upmixing. A discussion of the limitations of these approaches is also provided.
CLIPSonic: Text-to-Audio Synthesis with Unlabeled Videos and Pretrained Language-Vision Models
Jun 16, 2023



Recent work has studied text-to-audio synthesis using large amounts of paired text-audio data. However, audio recordings with high-quality text annotations can be difficult to acquire. In this work, we approach text-to-audio synthesis using unlabeled videos and pretrained language-vision models. We propose to learn the desired text-audio correspondence by leveraging the visual modality as a bridge. We train a conditional diffusion model to generate the audio track of a video, given a video frame encoded by a pretrained contrastive language-image pretraining (CLIP) model. At test time, we first explore performing a zero-shot modality transfer and condition the diffusion model with a CLIP-encoded text query. However, we observe a noticeable performance drop with respect to image queries. To close this gap, we further adopt a pretrained diffusion prior model to generate a CLIP image embedding given a CLIP text embedding. Our results show the effectiveness of the proposed method, and that the pretrained diffusion prior can reduce the modality transfer gap. While we focus on text-to-audio synthesis, the proposed model can also generate audio from image queries, and it shows competitive performance against a state-of-the-art image-to-audio synthesis model in a subjective listening test. This study offers a new direction of approaching text-to-audio synthesis that leverages the naturally-occurring audio-visual correspondence in videos and the power of pretrained language-vision models.
Towards Robust Image-in-Audio Deep Steganography
Mar 14, 2023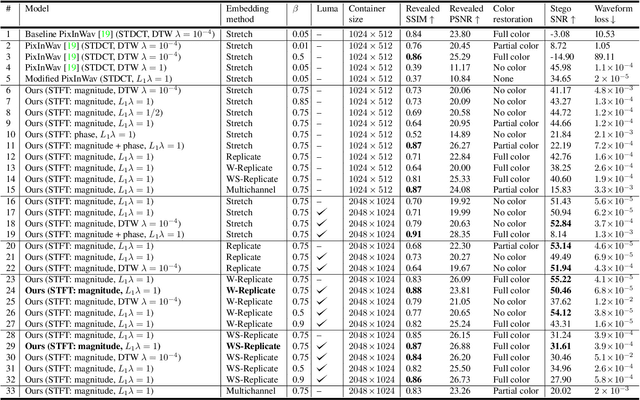
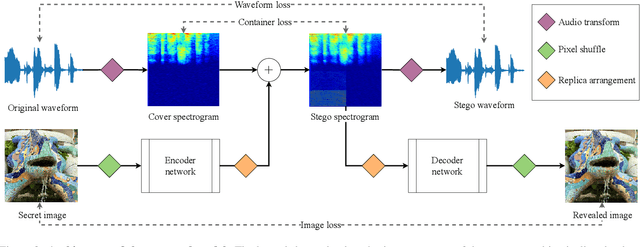
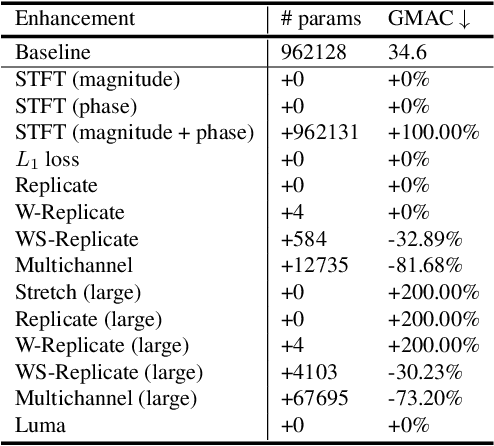

The field of steganography has experienced a surge of interest due to the recent advancements in AI-powered techniques, particularly in the context of multimodal setups that enable the concealment of signals within signals of a different nature. The primary objectives of all steganographic methods are to achieve perceptual transparency, robustness, and large embedding capacity - which often present conflicting goals that classical methods have struggled to reconcile. This paper extends and enhances an existing image-in-audio deep steganography method by focusing on improving its robustness. The proposed enhancements include modifications to the loss function, utilization of the Short-Time Fourier Transform (STFT), introduction of redundancy in the encoding process for error correction, and buffering of additional information in the pixel subconvolution operation. The results demonstrate that our approach outperforms the existing method in terms of robustness and perceptual transparency.