 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning based spatial aliasing reduction in beamforming for audio capture
May 26, 2025Spatial aliasing affects spaced microphone arrays, causing directional ambiguity above certain frequencies, degrading spatial and spectral accuracy of beamformers. Given the limitations of conventional signal processing and the scarcity of deep learning approaches to spatial aliasing mitigation, we propose a novel approach using a U-Net architecture to predict a signal-dependent de-aliasing filter, which reduces aliasing in conventional beamforming for spatial capture. Two types of multichannel filters are considered, one which treats the channels independently and a second one that models cross-channel dependencies. The proposed approach is evaluated in two common spatial capture scenarios: stereo and first-order Ambisonics. The results indicate a very significant improvement, both objective and perceptual, with respect to conventional beamforming. This work shows the potential of deep learning to reduce aliasing in beamforming, leading to improvements in multi-microphone setups.
Improved Panning on Non-Equidistant Loudspeakers with Direct Sound Level Compensation
Oct 27, 2023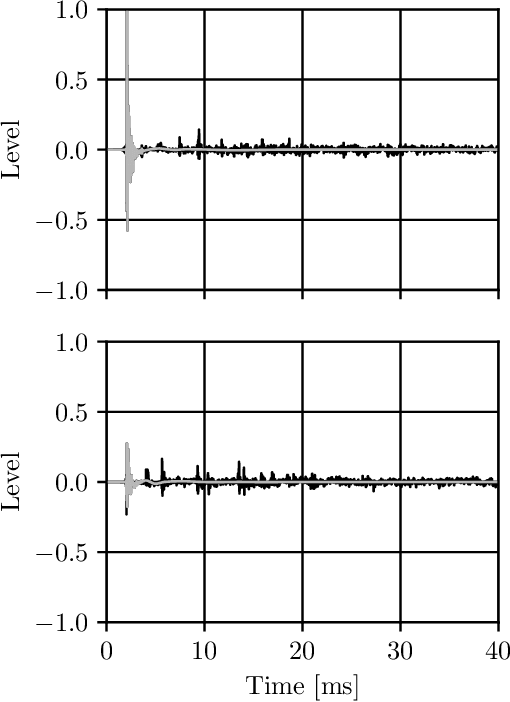
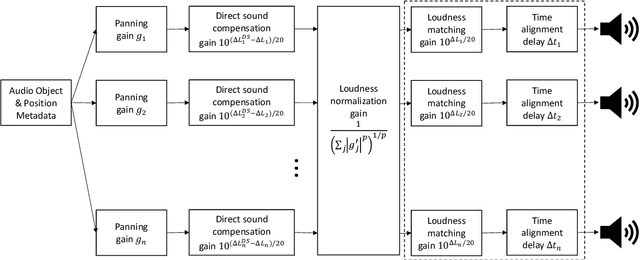
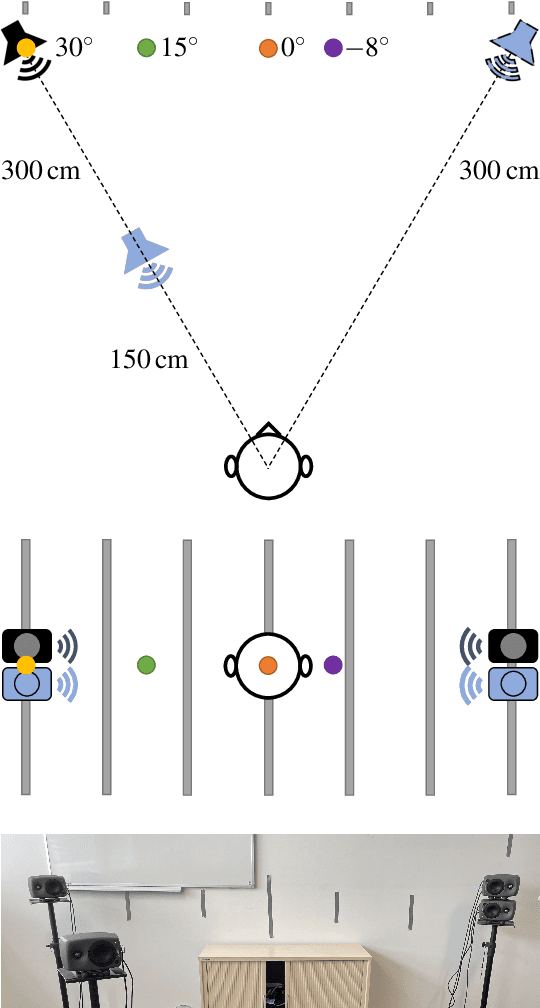
Loudspeaker rendering techniques that create phantom sound sources often assume an equidistant loudspeaker layout. Typical home setups might not fulfill this condition as loudspeakers deviate from canonical positions, thus requiring a corresponding calibration. The standard approach is to compensate for delays and to match the loudness of each loudspeaker at the listener's location. It was found that a shift of the phantom image occurs when this calibration procedure is applied and one of a pair of loudspeakers is significantly closer to the listener than the other. In this paper, a novel approach to panning on non-equidistant loudspeaker layouts is presented whereby the panning position is governed by the direct sound and the perceived loudness is governed by the full impulse response. Subjective listening tests are presented that validate the approach and quantify the perceived effect of the compensation. In a setup where the standard calibration leads to an average error of 10 degrees, the proposed direct sound compensation largely returns the phantom source to its intended position.
* 10 pages. Accepted for presentation in AES Convention 155 (2023)
Mono-to-stereo through parametric stereo generation
Jun 26, 2023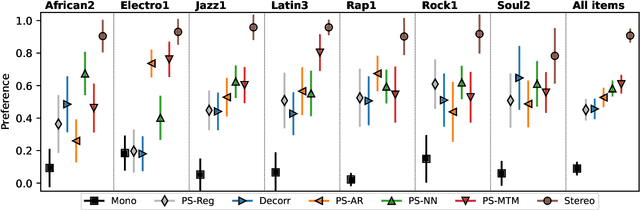
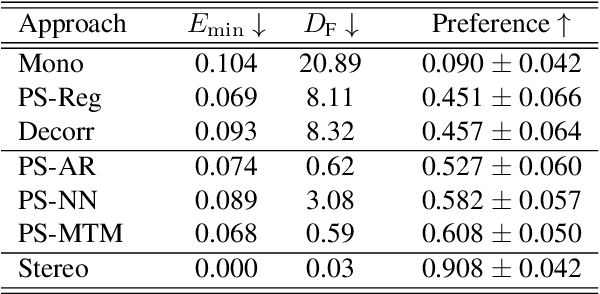
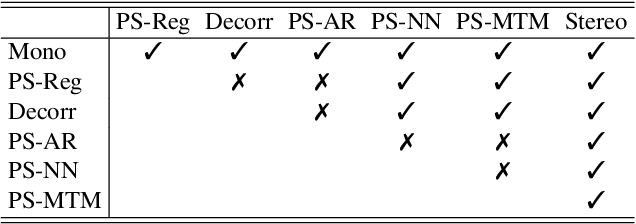
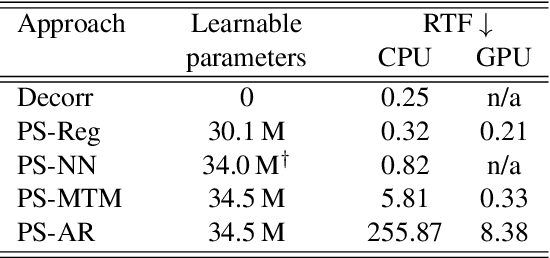
Generating a stereophonic presentation from a monophonic audio signal is a challenging open task, especially if the goal is to obtain a realistic spatial imaging with a specific panning of sound elements. In this work, we propose to convert mono to stereo by means of predicting parametric stereo (PS) parameters using both nearest neighbor and deep network approaches. In combination with PS, we also propose to model the task with generative approaches, allowing to synthesize multiple and equally-plausible stereo renditions from the same mono signal. To achieve this, we consider both autoregressive and masked token modelling approaches. We provide evidence that the proposed PS-based models outperform a competitive classical decorrelation baseline and that, within a PS prediction framework, modern generative models outshine equivalent non-generative counterparts. Overall, our work positions both PS and generative modelling as strong and appealing methodologies for mono-to-stereo upmixing. A discussion of the limitations of these approaches is also provided.
Upsampling layers for music source separation
Nov 23, 2021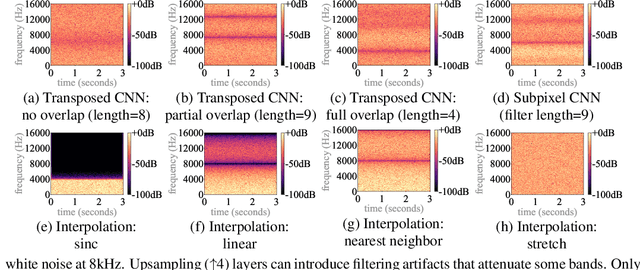
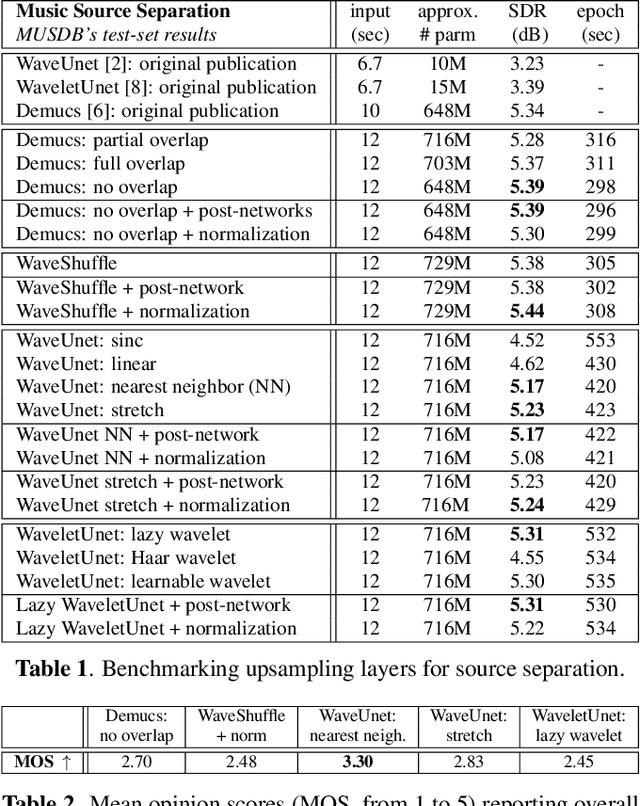

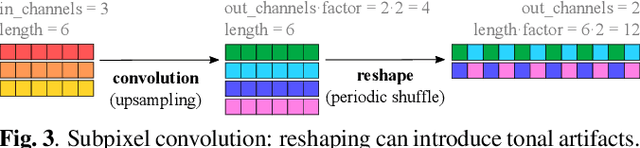
Upsampling artifacts are caused by problematic upsampling layers and due to spectral replicas that emerge while upsampling. Also, depending on the used upsampling layer, such artifacts can either be tonal artifacts (additive high-frequency noise) or filtering artifacts (substractive, attenuating some bands). In this work we investigate the practical implications of having upsampling artifacts in the resulting audio, by studying how different artifacts interact and assessing their impact on the models' performance. To that end, we benchmark a large set of upsampling layers for music source separation: different transposed and subpixel convolution setups, different interpolation upsamplers (including two novel layers based on stretch and sinc interpolation), and different wavelet-based upsamplers (including a novel learnable wavelet layer). Our results show that filtering artifacts, associated with interpolation upsamplers, are perceptually preferrable, even if they tend to achieve worse objective scores.
Upsampling artifacts in neural audio synthesis
Oct 27, 2020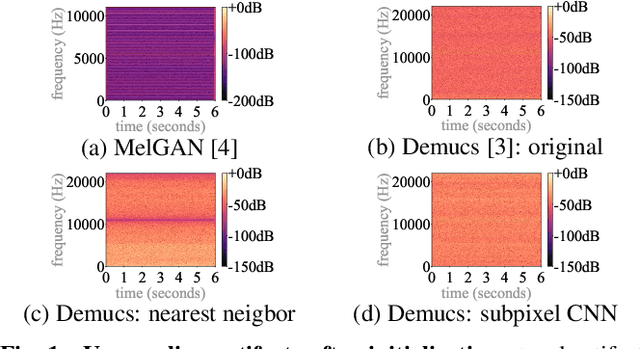
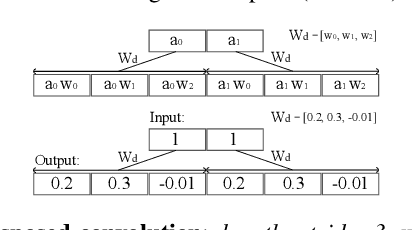
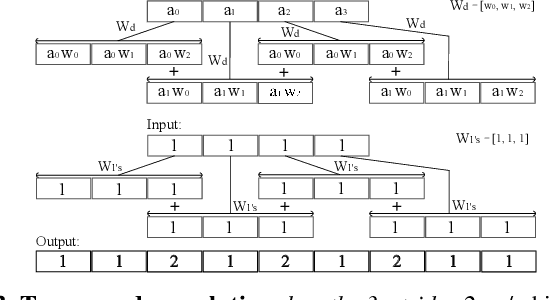
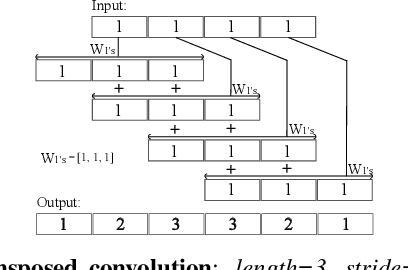
A number of recent advances in audio synthesis rely on neural upsamplers, which can introduce undesired artifacts. In computer vision, upsampling artifacts have been studied and are known as checkerboard artifacts (due to their characteristic visual pattern). However, their effect has been overlooked so far in audio processing. Here, we address this gap by studying this problem from the audio signal processing perspective. We first show that the main sources of upsampling artifacts are: (i) the tonal and filtering artifacts introduced by problematic upsampling operators, and (ii) the spectral replicas that emerge while upsampling. We then compare different neural upsamplers, showing that nearest neighbor interpolation upsamplers can be an alternative to the problematic (but state-of-the-art) transposed and subpixel convolutions which are prone to introduce tonal artifacts.