 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent, not Immanent: A Baradian Reading of Explainable AI
Jan 21, 2026Explainable AI (XAI) is frequently positioned as a technical problem of revealing the inner workings of an AI model. This position is affected by unexamined onto-epistemological assumptions: meaning is treated as immanent to the model, the explainer is positioned outside the system, and a causal structure is presumed recoverable through computational techniques. In this paper, we draw on Barad's agential realism to develop an alternative onto-epistemology of XAI. We propose that interpretations are material-discursive performances that emerge from situated entanglements of the AI model with humans, context, and the interpretative apparatus. To develop this position, we read a comprehensive set of XAI methods through agential realism and reveal the assumptions and limitations that underpin several of these methods. We then articulate the framework's ethical dimension and propose design directions for XAI interfaces that support emergent interpretation, using a speculative text-to-music interface as a case study.
Automatic Music Mixing using a Generative Model of Effect Embeddings
Nov 11, 2025Music mixing involves combining individual tracks into a cohesive mixture, a task characterized by subjectivity where multiple valid solutions exist for the same input. Existing automatic mixing systems treat this task as a deterministic regression problem, thus ignoring this multiplicity of solutions. Here we introduce MEGAMI (Multitrack Embedding Generative Auto MIxing), a generative framework that models the conditional distribution of professional mixes given unprocessed tracks. MEGAMI uses a track-agnostic effects processor conditioned on per-track generated embeddings, handles arbitrary unlabeled tracks through a permutation-equivariant architecture, and enables training on both dry and wet recordings via domain adaptation. Our objective evaluation using distributional metrics shows consistent improvements over existing methods, while listening tests indicate performances approaching human-level quality across diverse musical genres.
Attribution-by-design: Ensuring Inference-Time Provenance in Generative Music Systems
Oct 09, 2025



The rise of AI-generated music is diluting royalty pools and revealing structural flaws in existing remuneration frameworks, challenging the well-established artist compensation systems in the music industry. Existing compensation solutions, such as piecemeal licensing agreements, lack scalability and technical rigour, while current data attribution mechanisms provide only uncertain estimates and are rarely implemented in practice. This paper introduces a framework for a generative music infrastructure centred on direct attribution, transparent royalty distribution, and granular control for artists and rights' holders. We distinguish ontologically between the training set and the inference set, which allows us to propose two complementary forms of attribution: training-time attribution and inference-time attribution. We here favour inference-time attribution, as it enables direct, verifiable compensation whenever an artist's catalogue is used to condition a generated output. Besides, users benefit from the ability to condition generations on specific songs and receive transparent information about attribution and permitted usage. Our approach offers an ethical and practical solution to the pressing need for robust compensation mechanisms in the era of AI-generated music, ensuring that provenance and fairness are embedded at the core of generative systems.
A Comprehensive Real-World Assessment of Audio Watermarking Algorithms: Will They Survive Neural Codecs?
May 26, 2025We present a framework to foster the evaluation of deep learning-based audio watermarking algorithms, establishing a standardized benchmark and allowing systematic comparisons. To simulate real-world usage, we introduce a comprehensive audio attack pipeline, featuring various distortions such as compression, background noise, and reverberation, and propose a diverse test dataset, including speech, environmental sounds, and music recordings. By assessing the performance of four existing watermarking algorithms on our framework, two main insights stand out: (i) neural compression techniques pose the most significant challenge, even when algorithms are trained with such compressions; and (ii) training with audio attacks generally improves robustness, although it is insufficient in some cases. Furthermore, we find that specific distortions, such as polarity inversion, time stretching, or reverb, seriously affect certain algorithms. Our contributions strengthen the robustness and perceptual assessment of audio watermarking algorithms across a wide range of applications, while ensuring a fair and consistent evaluation approach. The evaluation framework, including the attack pipeline, is accessible at github.com/SonyResearch/wm_robustness_eval.
Supervised contrastive learning from weakly-labeled audio segments for musical version matching
Feb 24, 2025



Detecting musical versions (different renditions of the same piece) is a challenging task with important applications. Because of the ground truth nature, existing approaches match musical versions at the track level (e.g., whole song). However, most applications require to match them at the segment level (e.g., 20s chunks). In addition, existing approaches resort to classification and triplet losses, disregarding more recent losses that could bring meaningful improvements. In this paper, we propose a method to learn from weakly annotated segments, together with a contrastive loss variant that outperforms well-studied alternatives. The former is based on pairwise segment distance reductions, while the latter modifies an existing loss following decoupling, hyper-parameter, and geometric considerations. With these two elements, we do not only achieve state-of-the-art results in the standard track-level evaluation, but we also obtain a breakthrough performance in a segment-level evaluation. We believe that, due to the generality of the challenges addressed here, the proposed methods may find utility in domains beyond audio or musical version matching.
Joint Semantic Knowledge Distillation and Masked Acoustic Modeling for Full-band Speech Restoration with Improved Intelligibility
Sep 14, 2024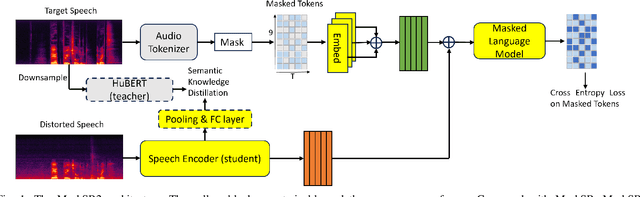
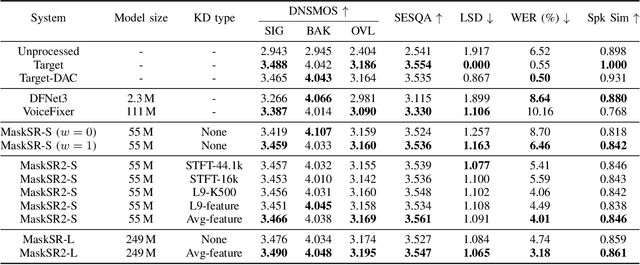

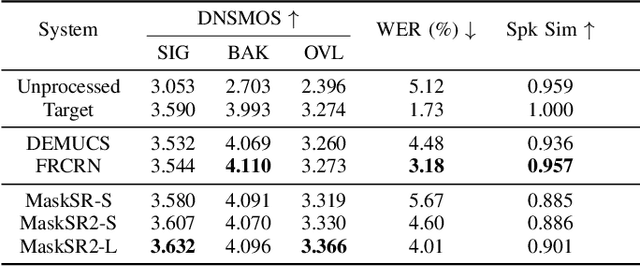
Speech restoration aims at restoring full-band speech with high quality and intelligibility, considering a diverse set of distortions. MaskSR is a recently proposed generative model for this task. As other models of its kind, MaskSR attains high quality but, as we show, intelligibility can be substantially improved. We do so by boosting the speech encoder component of MaskSR with predictions of semantic representations of the target speech, using a pre-trained self-supervised teacher model. Then, a masked language model is conditioned on the learned semantic features to predict acoustic tokens that encode low level spectral details of the target speech. We show that, with the same MaskSR model capacity and inference time, the proposed model, MaskSR2, significantly reduces the word error rate, a typical metric for intelligibility. MaskSR2 also achieves competitive word error rate among other models, while providing superior quality. An ablation study shows the effectiveness of various semantic representations.
Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
Jul 15, 2024Video-to-audio (V2A) generation leverages visual-only video features to render plausible sounds that match the scene. Importantly, the generated sound onsets should match the visual actions that are aligned with them, otherwise unnatural synchronization artifacts arise. Recent works have explored the progression of conditioning sound generators on still images and then video features, focusing on quality and semantic matching while ignoring synchronization, or by sacrificing some amount of quality to focus on improving synchronization only. In this work, we propose a V2A generative model, named MaskVAT, that interconnects a full-band high-quality general audio codec with a sequence-to-sequence masked generative model. This combination allows modeling both high audio quality, semantic matching, and temporal synchronicity at the same time. Our results show that, by combining a high-quality codec with the proper pre-trained audio-visual features and a sequence-to-sequence parallel structure, we are able to yield highly synchronized results on one hand, whilst being competitive with the state of the art of non-codec generative audio models. Sample videos and generated audios are available at https://maskvat.github.io .
Sequential Contrastive Audio-Visual Learning
Jul 08, 2024



Contrastive learning has emerged as a powerful technique in audio-visual representation learning, leveraging the natural co-occurrence of audio and visual modalities in extensive web-scale video datasets to achieve significant advancements. However, conventional contrastive audio-visual learning methodologies often rely on aggregated representations derived through temporal aggregation, which neglects the intrinsic sequential nature of the data. This oversight raises concerns regarding the ability of standard approaches to capture and utilize fine-grained information within sequences, information that is vital for distinguishing between semantically similar yet distinct examples. In response to this limitation, we propose sequential contrastive audio-visual learning (SCAV), which contrasts examples based on their non-aggregated representation space using sequential distances. Retrieval experiments with the VGGSound and Music datasets demonstrate the effectiveness of SCAV, showing 2-3x relative improvements against traditional aggregation-based contrastive learning and other methods from the literature. We also show that models trained with SCAV exhibit a high degree of flexibility regarding the metric employed for retrieval, allowing them to operate on a spectrum of efficiency-accuracy trade-offs, potentially making them applicable in multiple scenarios, from small- to large-scale retrieval.
GASS: Generalizing Audio Source Separation with Large-scale Data
Sep 29, 2023Universal source separation targets at separating the audio sources of an arbitrary mix, removing the constraint to operate on a specific domain like speech or music. Yet, the potential of universal source separation is limited because most existing works focus on mixes with predominantly sound events, and small training datasets also limit its potential for supervised learning. Here, we study a single general audio source separation (GASS) model trained to separate speech, music, and sound events in a supervised fashion with a large-scale dataset. We assess GASS models on a diverse set of tasks. Our strong in-distribution results show the feasibility of GASS models, and the competitive out-of-distribution performance in sound event and speech separation shows its generalization abilities. Yet, it is challenging for GASS models to generalize for separating out-of-distribution cinematic and music content. We also fine-tune GASS models on each dataset and consistently outperform the ones without pre-training. All fine-tuned models (except the music separation one) obtain state-of-the-art results in their respective benchmarks.
Mono-to-stereo through parametric stereo generation
Jun 26, 2023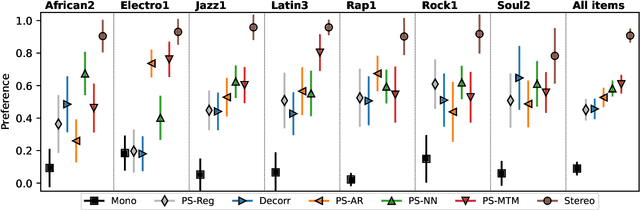
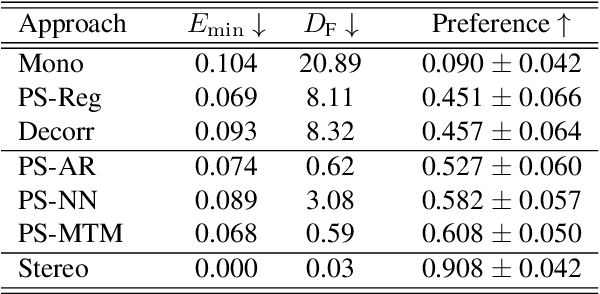
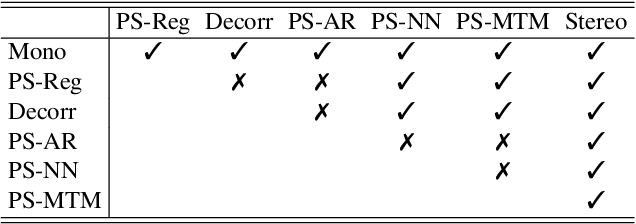
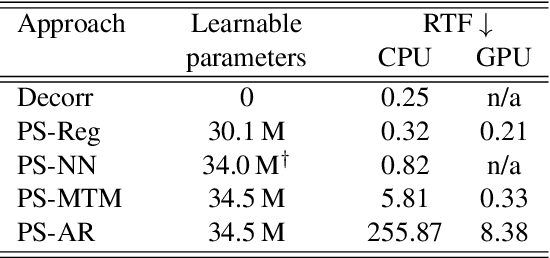
Generating a stereophonic presentation from a monophonic audio signal is a challenging open task, especially if the goal is to obtain a realistic spatial imaging with a specific panning of sound elements. In this work, we propose to convert mono to stereo by means of predicting parametric stereo (PS) parameters using both nearest neighbor and deep network approaches. In combination with PS, we also propose to model the task with generative approaches, allowing to synthesize multiple and equally-plausible stereo renditions from the same mono signal. To achieve this, we consider both autoregressive and masked token modelling approaches. We provide evidence that the proposed PS-based models outperform a competitive classical decorrelation baseline and that, within a PS prediction framework, modern generative models outshine equivalent non-generative counterparts. Overall, our work positions both PS and generative modelling as strong and appealing methodologies for mono-to-stereo upmixing. A discussion of the limitations of these approaches is also provided.