 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribution-by-design: Ensuring Inference-Time Provenance in Generative Music Systems
Oct 09, 2025



The rise of AI-generated music is diluting royalty pools and revealing structural flaws in existing remuneration frameworks, challenging the well-established artist compensation systems in the music industry. Existing compensation solutions, such as piecemeal licensing agreements, lack scalability and technical rigour, while current data attribution mechanisms provide only uncertain estimates and are rarely implemented in practice. This paper introduces a framework for a generative music infrastructure centred on direct attribution, transparent royalty distribution, and granular control for artists and rights' holders. We distinguish ontologically between the training set and the inference set, which allows us to propose two complementary forms of attribution: training-time attribution and inference-time attribution. We here favour inference-time attribution, as it enables direct, verifiable compensation whenever an artist's catalogue is used to condition a generated output. Besides, users benefit from the ability to condition generations on specific songs and receive transparent information about attribution and permitted usage. Our approach offers an ethical and practical solution to the pressing need for robust compensation mechanisms in the era of AI-generated music, ensuring that provenance and fairness are embedded at the core of generative systems.
TEDI: Trustworthy and Ethical Dataset Indicators to Analyze and Compare Dataset Documentation
May 23, 2025



Dataset transparency is a key enabler of responsible AI, but insights into multimodal dataset attributes that impact trustworthy and ethical aspects of AI applications remain scarce and are difficult to compare across datasets. To address this challenge, we introduce Trustworthy and Ethical Dataset Indicators (TEDI) that facilitate the systematic, empirical analysis of dataset documentation. TEDI encompasses 143 fine-grained indicators that characterize trustworthy and ethical attributes of multimodal datasets and their collection processes. The indicators are framed to extract verifiable information from dataset documentation. Using TEDI, we manually annotated and analyzed over 100 multimodal datasets that include human voices. We further annotated data sourcing, size, and modality details to gain insights into the factors that shape trustworthy and ethical dimensions across datasets. We find that only a select few datasets have documented attributes and practices pertaining to consent, privacy, and harmful content indicators. The extent to which these and other ethical indicators are addressed varies based on the data collection method, with documentation of datasets collected via crowdsourced and direct collection approaches being more likely to mention them. Scraping dominates scale at the cost of ethical indicators, but is not the only viable collection method. Our approach and empirical insights contribute to increasing dataset transparency along trustworthy and ethical dimensions and pave the way for automating the tedious task of extracting information from dataset documentation in future.
As Biased as You Measure: Methodological Pitfalls of Bias Evaluations in Speaker Verification Research
Aug 24, 2024
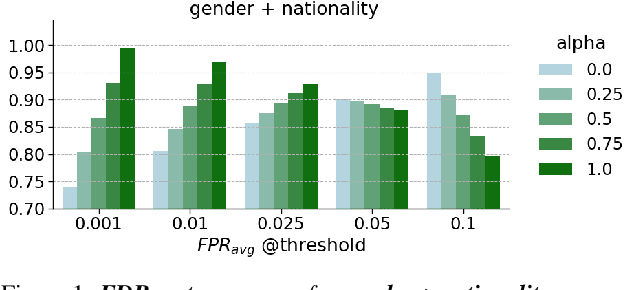
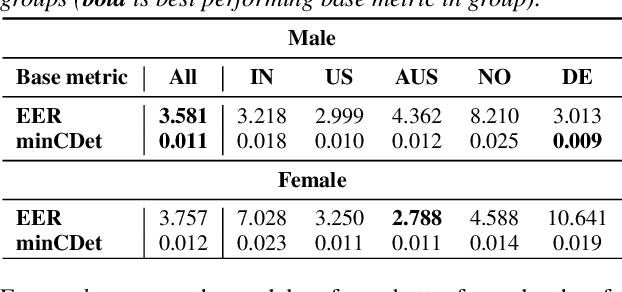
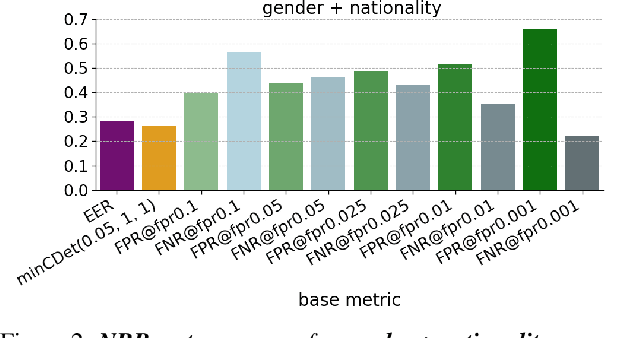
Detecting and mitigating bias in speaker verification systems is important, as datasets, processing choices and algorithms can lead to performance differences that systematically favour some groups of people while disadvantaging others. Prior studies have thus measured performance differences across groups to evaluate bias. However, when comparing results across studies, it becomes apparent that they draw contradictory conclusions, hindering progress in this area. In this paper we investigate how measurement impacts the outcomes of bias evaluations. We show empirically that bias evaluations are strongly influenced by base metrics that measure performance, by the choice of ratio or difference-based bias measure, and by the aggregation of bias measures into meta-measures. Based on our findings, we recommend the use of ratio-based bias measures, in particular when the values of base metrics are small, or when base metrics with different orders of magnitude need to be compared.
Introducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Not My Voice! A Taxonomy of Ethical and Safety Harms of Speech Generators
Jan 25, 2024



The rapid and wide-scale adoption of AI to generate human speech poses a range of significant ethical and safety risks to society that need to be addressed. For example, a growing number of speech generation incidents are associated with swatting attacks in the United States, where anonymous perpetrators create synthetic voices that call police officers to close down schools and hospitals, or to violently gain access to innocent citizens' homes. Incidents like this demonstrate that multimodal generative AI risks and harms do not exist in isolation, but arise from the interactions of multiple stakeholders and technical AI systems. In this paper we analyse speech generation incidents to study how patterns of specific harms arise. We find that specific harms can be categorised according to the exposure of affected individuals, that is to say whether they are a subject of, interact with, suffer due to, or are excluded from speech generation systems. Similarly, specific harms are also a consequence of the motives of the creators and deployers of the systems. Based on these insights we propose a conceptual framework for modelling pathways to ethical and safety harms of AI, which we use to develop a taxonomy of harms of speech generators. Our relational approach captures the complexity of risks and harms in sociotechnical AI systems, and yields an extensible taxonomy that can support appropriate policy interventions and decision making for responsible multimodal model development and release of speech generators.