 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Verifiable Federated Unlearning: Framework, Challenges, and The Road Ahead
Oct 01, 2025Federated unlearning (FUL) enables removing the data influence from the model trained across distributed clients, upholding the right to be forgotten as mandated by privacy regulations. FUL facilitates a value exchange where clients gain privacy-preserving control over their data contributions, while service providers leverage decentralized computing and data freshness. However, this entire proposition is undermined because clients have no reliable way to verify that their data influence has been provably removed, as current metrics and simple notifications offer insufficient assurance. We envision unlearning verification becoming a pivotal and trust-by-design part of the FUL life-cycle development, essential for highly regulated and data-sensitive services and applications like healthcare. This article introduces veriFUL, a reference framework for verifiable FUL that formalizes verification entities, goals, approaches, and metrics. Specifically, we consolidate existing efforts and contribute new insights, concepts, and metrics to this domain. Finally, we highlight research challenges and identify potential applications and developments for verifiable FUL and veriFUL.
Accountability Framework for Healthcare AI Systems: Towards Joint Accountability in Decision Making
Sep 03, 2025AI is transforming the healthcare domain and is increasingly helping practitioners to make health-related decisions. Therefore, accountability becomes a crucial concern for critical AI-driven decisions. Although regulatory bodies, such as the EU commission, provide guidelines, they are highlevel and focus on the ''what'' that should be done and less on the ''how'', creating a knowledge gap for actors. Through an extensive analysis, we found that the term accountability is perceived and dealt with in many different ways, depending on the actor's expertise and domain of work. With increasing concerns about AI accountability issues and the ambiguity around this term, this paper bridges the gap between the ''what'' and ''how'' of AI accountability, specifically for AI systems in healthcare. We do this by analysing the concept of accountability, formulating an accountability framework, and providing a three-tier structure for handling various accountability mechanisms. Our accountability framework positions the regulations of healthcare AI systems and the mechanisms adopted by the actors under a consistent accountability regime. Moreover, the three-tier structure guides the actors of the healthcare AI system to categorise the mechanisms based on their conduct. Through our framework, we advocate that decision-making in healthcare AI holds shared dependencies, where accountability should be dealt with jointly and should foster collaborations. We highlight the role of explainability in instigating communication and information sharing between the actors to further facilitate the collaborative process.
As Biased as You Measure: Methodological Pitfalls of Bias Evaluations in Speaker Verification Research
Aug 24, 2024
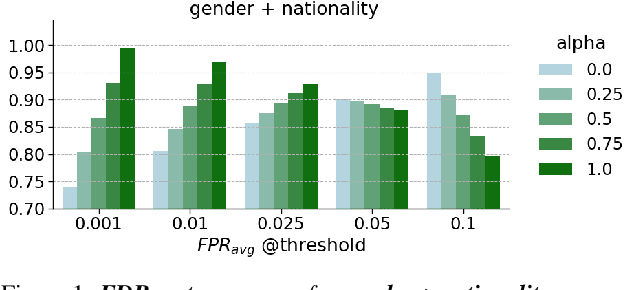
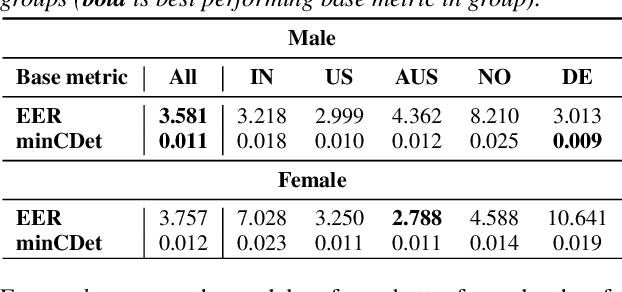
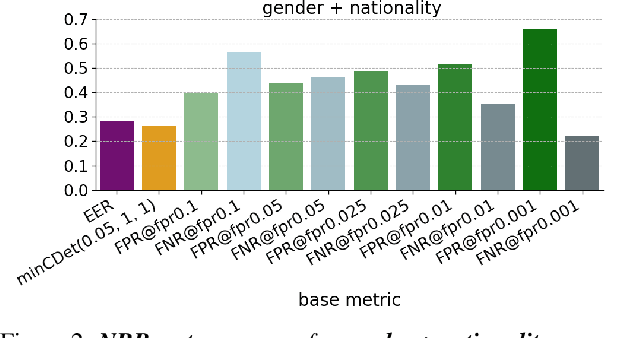
Detecting and mitigating bias in speaker verification systems is important, as datasets, processing choices and algorithms can lead to performance differences that systematically favour some groups of people while disadvantaging others. Prior studies have thus measured performance differences across groups to evaluate bias. However, when comparing results across studies, it becomes apparent that they draw contradictory conclusions, hindering progress in this area. In this paper we investigate how measurement impacts the outcomes of bias evaluations. We show empirically that bias evaluations are strongly influenced by base metrics that measure performance, by the choice of ratio or difference-based bias measure, and by the aggregation of bias measures into meta-measures. Based on our findings, we recommend the use of ratio-based bias measures, in particular when the values of base metrics are small, or when base metrics with different orders of magnitude need to be compared.
Analyzing and Mitigating Bias for Vulnerable Classes: Towards Balanced Representation in Dataset
Jan 18, 2024The accuracy and fairness of perception systems in autonomous driving are crucial, particularly for vulnerable road users. Mainstream research has looked into improving the performance metrics for classification accuracy. However, the hidden traits of bias inheritance in the AI models, class imbalances and disparities in the datasets are often overlooked. In this context, our study examines the class imbalances for vulnerable road users by focusing on class distribution analysis, performance evaluation, and bias impact assessment. We identify the concern of imbalances in class representation, leading to potential biases in detection accuracy. Utilizing popular CNN models and Vision Transformers (ViTs) with the nuScenes dataset, our performance evaluation reveals detection disparities for underrepresented classes. We propose a methodology for model optimization and bias mitigation, which includes data augmentation, resampling, and metric-specific learning. Using the proposed mitigation approaches, we see improvement in IoU(%) and NDS(%) metrics from 71.3 to 75.6 and 80.6 to 83.7 respectively, for the CNN model. Similarly, for ViT, we observe improvement in IoU and NDS metrics from 74.9 to 79.2 and 83.8 to 87.1 respectively. This research contributes to developing more reliable models and datasets, enhancing inclusiveness for minority classes.
A Survey on Approximate Edge AI for Energy Efficient Autonomous Driving Services
Apr 13, 2023Autonomous driving services rely heavily on sensors such as cameras, LiDAR, radar, and communication modules. A common practice of processing the sensed data is using a high-performance computing unit placed inside the vehicle, which deploys AI models and algorithms to act as the brain or administrator of the vehicle. The vehicular data generated from average hours of driving can be up to 20 Terabytes depending on the data rate and specification of the sensors. Given the scale and fast growth of services for autonomous driving, it is essential to improve the overall energy and environmental efficiency, especially in the trend towards vehicular electrification (e.g., battery-powered). Although the areas have seen significant advancements in sensor technologies, wireless communications, computing and AI/ML algorithms, the challenge still exists in how to apply and integrate those technology innovations to achieve energy efficiency. This survey reviews and compares the connected vehicular applications, vehicular communications, approximation and Edge AI techniques. The focus is on energy efficiency by covering newly proposed approximation and enabling frameworks. To the best of our knowledge, this survey is the first to review the latest approximate Edge AI frameworks and publicly available datasets in energy-efficient autonomous driving. The insights and vision from this survey can be beneficial for the collaborative driving service development on low-power and memory-constrained systems and also for the energy optimization of autonomous vehicles.
Design Guidelines for Inclusive Speaker Verification Evaluation Datasets
Apr 05, 2022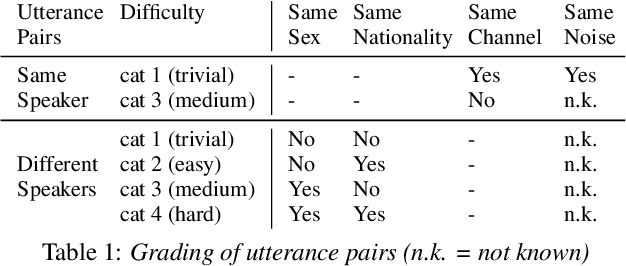
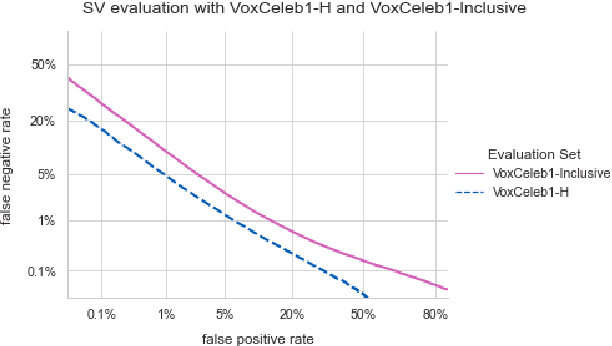
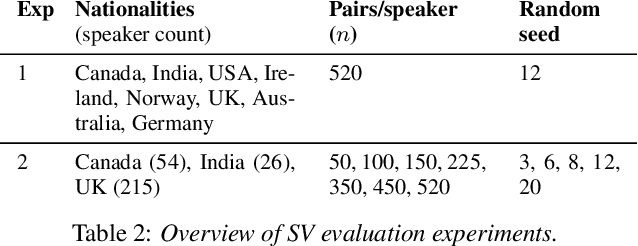
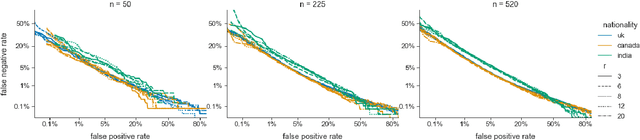
Speaker verification (SV) provides billions of voice-enabled devices with access control, and ensures the security of voice-driven technologies. As a type of biometrics, it is necessary that SV is unbiased, with consistent and reliable performance across speakers irrespective of their demographic, social and economic attributes. Current SV evaluation practices are insufficient for evaluating bias: they are over-simplified and aggregate users, not representative of real-life usage scenarios, and consequences of errors are not accounted for. This paper proposes design guidelines for constructing SV evaluation datasets that address these short-comings. We propose a schema for grading the difficulty of utterance pairs, and present an algorithm for generating inclusive SV datasets. We empirically validate our proposed method in a set of experiments on the VoxCeleb1 dataset. Our results confirm that the count of utterance pairs/speaker, and the difficulty grading of utterance pairs have a significant effect on evaluation performance and variability. Our work contributes to the development of SV evaluation practices that are inclusive and fair.
Tiny, always-on and fragile: Bias propagation through design choices in on-device machine learning workflows
Jan 26, 2022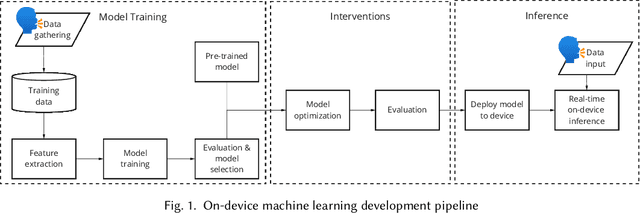
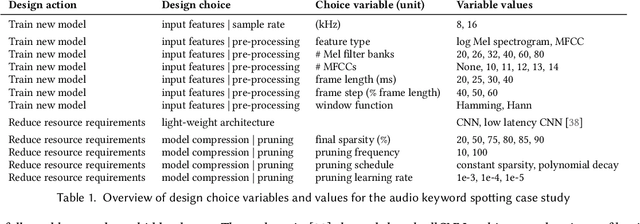
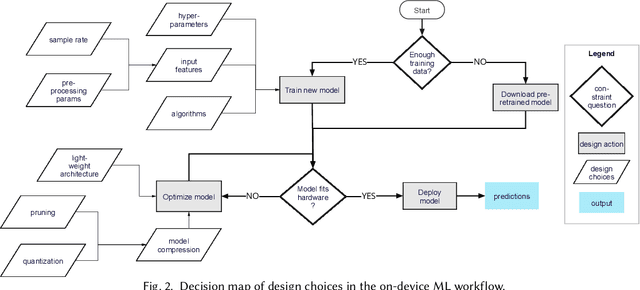
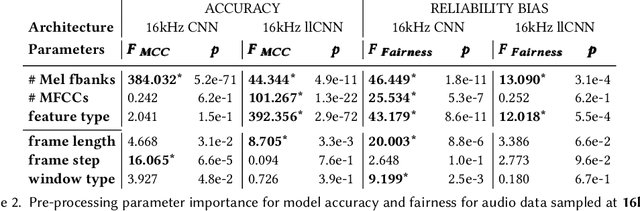
Billions of distributed, heterogeneous and resource constrained smart consumer devices deploy on-device machine learning (ML) to deliver private, fast and offline inference on personal data. On-device ML systems are highly context dependent, and sensitive to user, usage, hardware and environmental attributes. Despite this sensitivity and the propensity towards bias in ML, bias in on-device ML has not been studied. This paper studies the propagation of bias through design choices in on-device ML development workflows. We position reliability bias, which arises from disparate device failures across demographic groups, as a source of unfairness in on-device ML settings and quantify metrics to evaluate it. We then identify complex and interacting technical design choices in the on-device ML workflow that can lead to disparate performance across user groups, and thus reliability bias. Finally, we show with an empirical case study that seemingly innocuous design choices such as the data sample rate, pre-processing parameters used to construct input features and pruning hyperparameters propagate reliability bias through an audio keyword spotting development workflow. We leverage our insights to suggest strategies for developers to develop fairer on-device ML.
Roadmap for Edge AI: A Dagstuhl Perspective
Nov 27, 2021
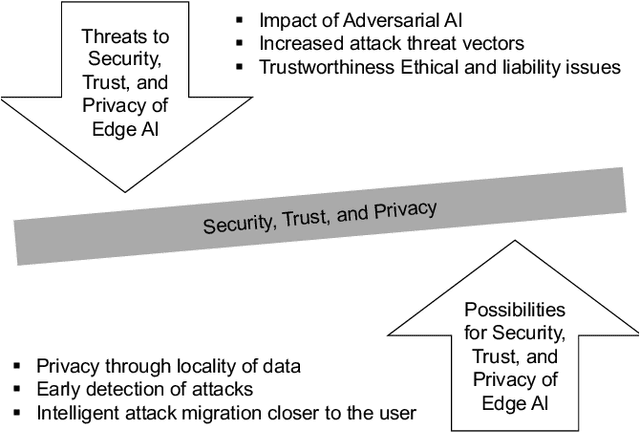
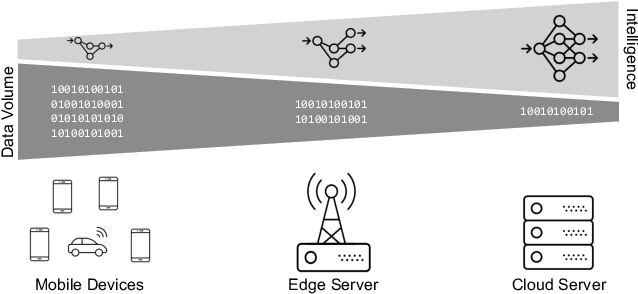

Based on the collective input of Dagstuhl Seminar (21342), this paper presents a comprehensive discussion on AI methods and capabilities in the context of edge computing, referred as Edge AI. In a nutshell, we envision Edge AI to provide adaptation for data-driven applications, enhance network and radio access, and allow the creation, optimization, and deployment of distributed AI/ML pipelines with given quality of experience, trust, security and privacy targets. The Edge AI community investigates novel ML methods for the edge computing environment, spanning multiple sub-fields of computer science, engineering and ICT. The goal is to share an envisioned roadmap that can bring together key actors and enablers to further advance the domain of Edge AI.
SVEva Fair: A Framework for Evaluating Fairness in Speaker Verification
Jul 26, 2021

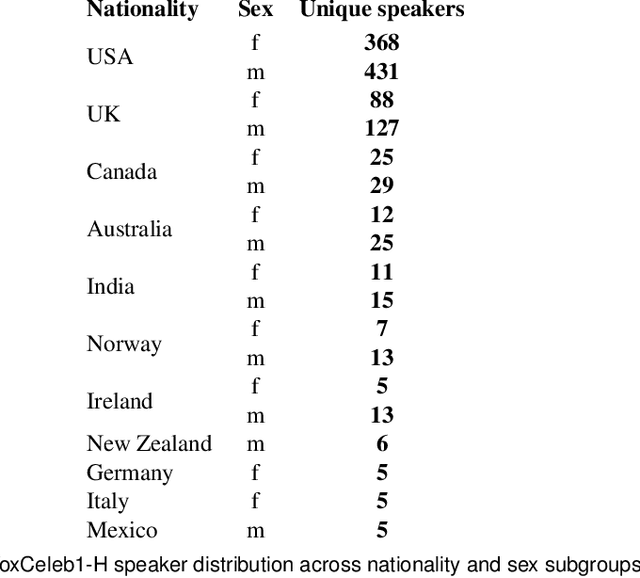
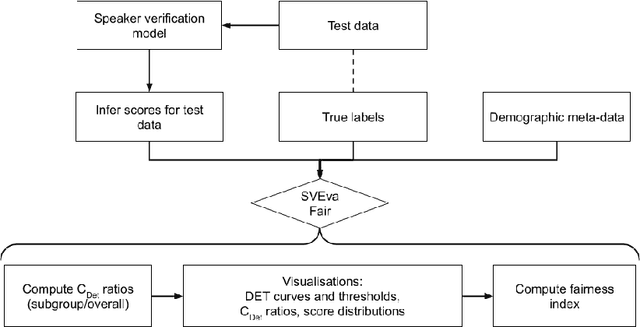
Despite the success of deep neural networks (DNNs) in enabling on-device voice assistants, increasing evidence of bias and discrimination in machine learning is raising the urgency of investigating the fairness of these systems. Speaker verification is a form of biometric identification that gives access to voice assistants. Due to a lack of fairness metrics and evaluation frameworks that are appropriate for testing the fairness of speaker verification components, little is known about how model performance varies across subgroups, and what factors influence performance variation. To tackle this emerging challenge, we design and develop SVEva Fair, an accessible, actionable and model-agnostic framework for evaluating the fairness of speaker verification components. The framework provides evaluation measures and visualisations to interrogate model performance across speaker subgroups and compare fairness between models. We demonstrate SVEva Fair in a case study with end-to-end DNNs trained on the VoxCeleb datasets to reveal potential bias in existing embedded speech recognition systems based on the demographic attributes of speakers. Our evaluation shows that publicly accessible benchmark models are not fair and consistently produce worse predictions for some nationalities, and for female speakers of most nationalities. To pave the way for fair and reliable embedded speaker verification, SVEva Fair has been implemented as an open-source python library and can be integrated into the embedded ML development pipeline to facilitate developers and researchers in troubleshooting unreliable speaker verification performance, and selecting high impact approaches for mitigating fairness challenges
Machine Learning Systems in the IoT: Trustworthiness Trade-offs for Edge Intelligence
Dec 01, 2020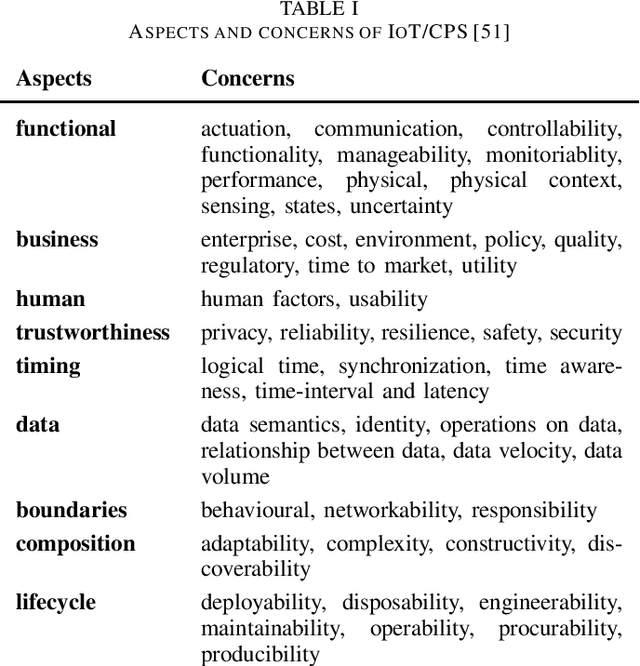
Machine learning systems (MLSys) are emerging in the Internet of Things (IoT) to provision edge intelligence, which is paving our way towards the vision of ubiquitous intelligence. However, despite the maturity of machine learning systems and the IoT, we are facing severe challenges when integrating MLSys and IoT in practical context. For instance, many machine learning systems have been developed for large-scale production (e.g., cloud environments), but IoT introduces additional demands due to heterogeneous and resource-constrained devices and decentralized operation environment. To shed light on this convergence of MLSys and IoT, this paper analyzes the trade-offs by covering the latest developments (up to 2020) on scaling and distributing ML across cloud, edge, and IoT devices. We position machine learning systems as a component of the IoT, and edge intelligence as a socio-technical system. On the challenges of designing trustworthy edge intelligence, we advocate a holistic design approach that takes multi-stakeholder concerns, design requirements and trade-offs into consideration, and highlight the future research opportunities in edge intelligence.