 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny, always-on and fragile: Bias propagation through design choices in on-device machine learning workflows
Paper and Code
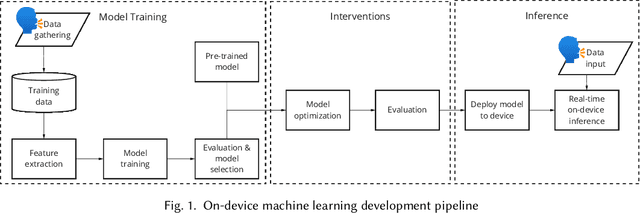
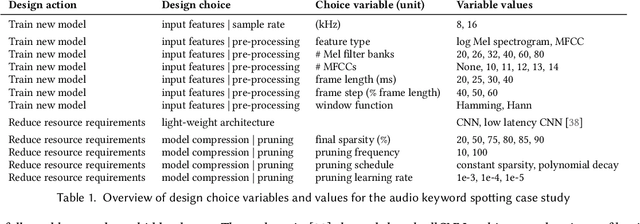
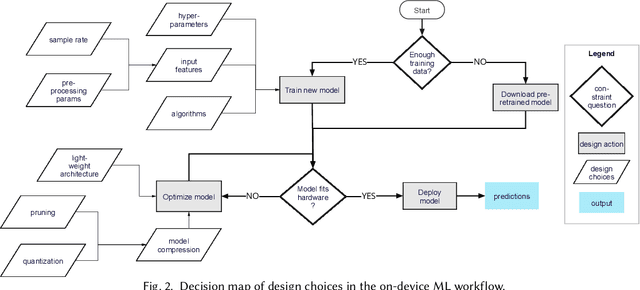
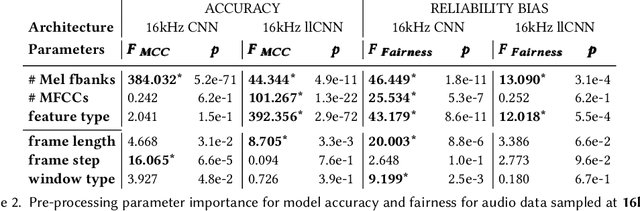
Billions of distributed, heterogeneous and resource constrained smart consumer devices deploy on-device machine learning (ML) to deliver private, fast and offline inference on personal data. On-device ML systems are highly context dependent, and sensitive to user, usage, hardware and environmental attributes. Despite this sensitivity and the propensity towards bias in ML, bias in on-device ML has not been studied. This paper studies the propagation of bias through design choices in on-device ML development workflows. We position reliability bias, which arises from disparate device failures across demographic groups, as a source of unfairness in on-device ML settings and quantify metrics to evaluate it. We then identify complex and interacting technical design choices in the on-device ML workflow that can lead to disparate performance across user groups, and thus reliability bias. Finally, we show with an empirical case study that seemingly innocuous design choices such as the data sample rate, pre-processing parameters used to construct input features and pruning hyperparameters propagate reliability bias through an audio keyword spotting development workflow. We leverage our insights to suggest strategies for developers to develop fairer on-device ML.