 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny, always-on and fragile: Bias propagation through design choices in on-device machine learning workflows
Jan 26, 2022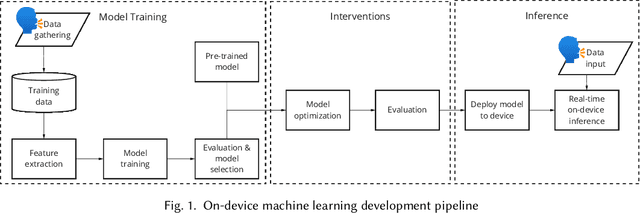
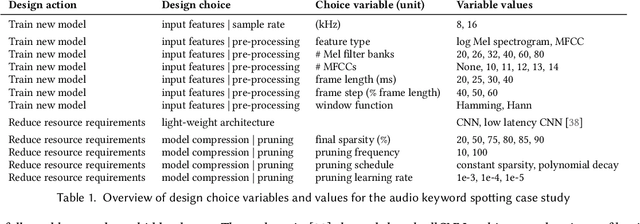
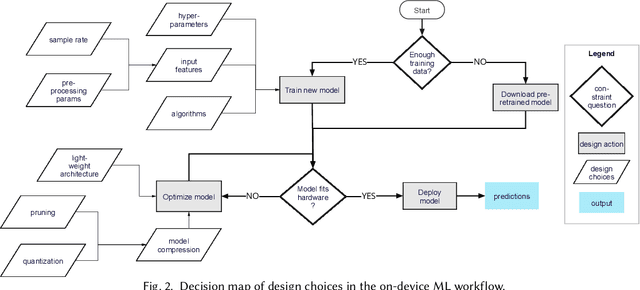
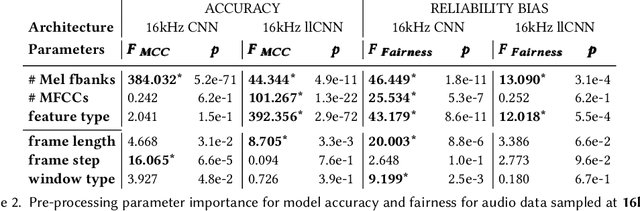
Billions of distributed, heterogeneous and resource constrained smart consumer devices deploy on-device machine learning (ML) to deliver private, fast and offline inference on personal data. On-device ML systems are highly context dependent, and sensitive to user, usage, hardware and environmental attributes. Despite this sensitivity and the propensity towards bias in ML, bias in on-device ML has not been studied. This paper studies the propagation of bias through design choices in on-device ML development workflows. We position reliability bias, which arises from disparate device failures across demographic groups, as a source of unfairness in on-device ML settings and quantify metrics to evaluate it. We then identify complex and interacting technical design choices in the on-device ML workflow that can lead to disparate performance across user groups, and thus reliability bias. Finally, we show with an empirical case study that seemingly innocuous design choices such as the data sample rate, pre-processing parameters used to construct input features and pruning hyperparameters propagate reliability bias through an audio keyword spotting development workflow. We leverage our insights to suggest strategies for developers to develop fairer on-device ML.
Bias in Automated Speaker Recognition
Jan 24, 2022
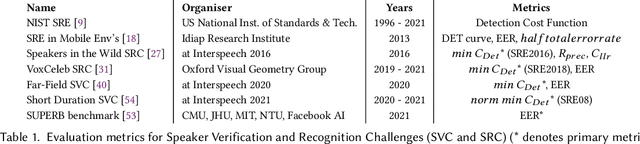

Automated speaker recognition uses data processing to identify speakers by their voice. Today, automated speaker recognition technologies are deployed on billions of smart devices and in services such as call centres. Despite their wide-scale deployment and known sources of bias in face recognition and natural language processing, bias in automated speaker recognition has not been studied systematically. We present an in-depth empirical and analytical study of bias in the machine learning development workflow of speaker verification, a voice biometric and core task in automated speaker recognition. Drawing on an established framework for understanding sources of harm in machine learning, we show that bias exists at every development stage in the well-known VoxCeleb Speaker Recognition Challenge, including model building, implementation, and data generation. Most affected are female speakers and non-US nationalities, who experience significant performance degradation. Leveraging the insights from our findings, we make practical recommendations for mitigating bias in automated speaker recognition, and outline future research directions.
SVEva Fair: A Framework for Evaluating Fairness in Speaker Verification
Jul 26, 2021

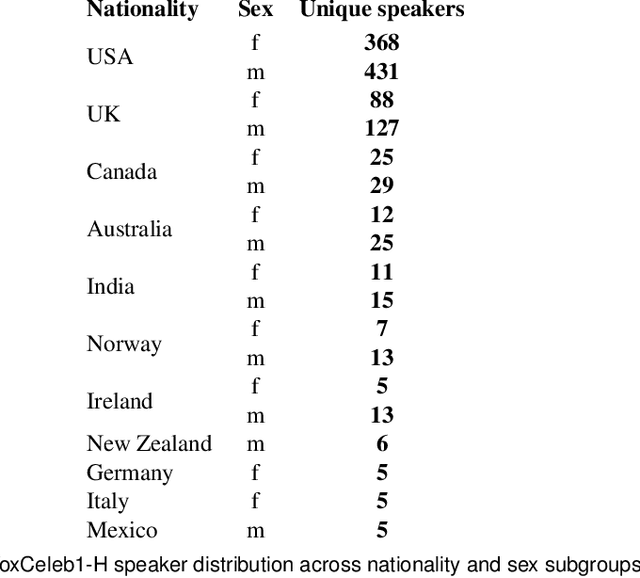
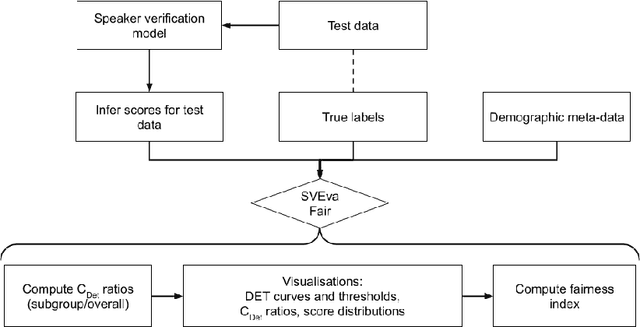
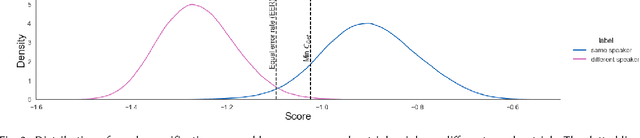
Despite the success of deep neural networks (DNNs) in enabling on-device voice assistants, increasing evidence of bias and discrimination in machine learning is raising the urgency of investigating the fairness of these systems. Speaker verification is a form of biometric identification that gives access to voice assistants. Due to a lack of fairness metrics and evaluation frameworks that are appropriate for testing the fairness of speaker verification components, little is known about how model performance varies across subgroups, and what factors influence performance variation. To tackle this emerging challenge, we design and develop SVEva Fair, an accessible, actionable and model-agnostic framework for evaluating the fairness of speaker verification components. The framework provides evaluation measures and visualisations to interrogate model performance across speaker subgroups and compare fairness between models. We demonstrate SVEva Fair in a case study with end-to-end DNNs trained on the VoxCeleb datasets to reveal potential bias in existing embedded speech recognition systems based on the demographic attributes of speakers. Our evaluation shows that publicly accessible benchmark models are not fair and consistently produce worse predictions for some nationalities, and for female speakers of most nationalities. To pave the way for fair and reliable embedded speaker verification, SVEva Fair has been implemented as an open-source python library and can be integrated into the embedded ML development pipeline to facilitate developers and researchers in troubleshooting unreliable speaker verification performance, and selecting high impact approaches for mitigating fairness challenges
Machine Learning Systems in the IoT: Trustworthiness Trade-offs for Edge Intelligence
Dec 01, 2020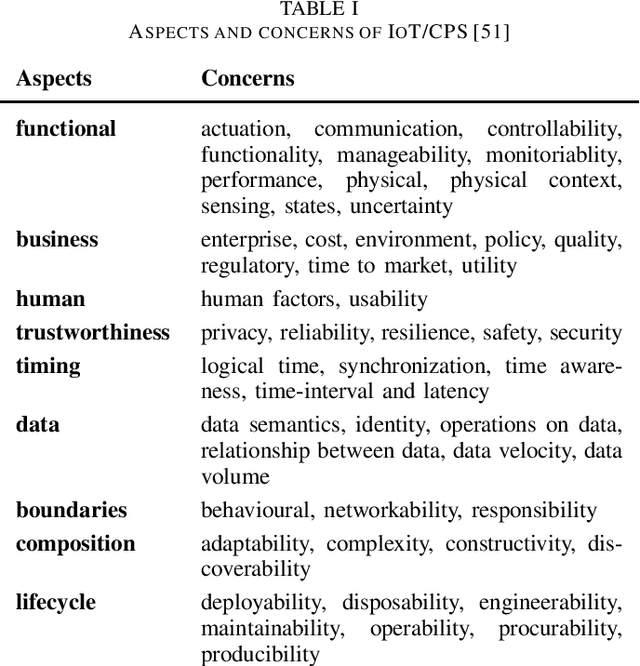
Machine learning systems (MLSys) are emerging in the Internet of Things (IoT) to provision edge intelligence, which is paving our way towards the vision of ubiquitous intelligence. However, despite the maturity of machine learning systems and the IoT, we are facing severe challenges when integrating MLSys and IoT in practical context. For instance, many machine learning systems have been developed for large-scale production (e.g., cloud environments), but IoT introduces additional demands due to heterogeneous and resource-constrained devices and decentralized operation environment. To shed light on this convergence of MLSys and IoT, this paper analyzes the trade-offs by covering the latest developments (up to 2020) on scaling and distributing ML across cloud, edge, and IoT devices. We position machine learning systems as a component of the IoT, and edge intelligence as a socio-technical system. On the challenges of designing trustworthy edge intelligence, we advocate a holistic design approach that takes multi-stakeholder concerns, design requirements and trade-offs into consideration, and highlight the future research opportunities in edge intelligence.
Automating Cluster Analysis to Generate Customer Archetypes for Residential Energy Consumers in South Africa
Jun 23, 2020
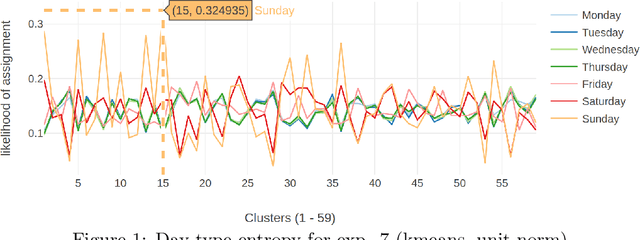
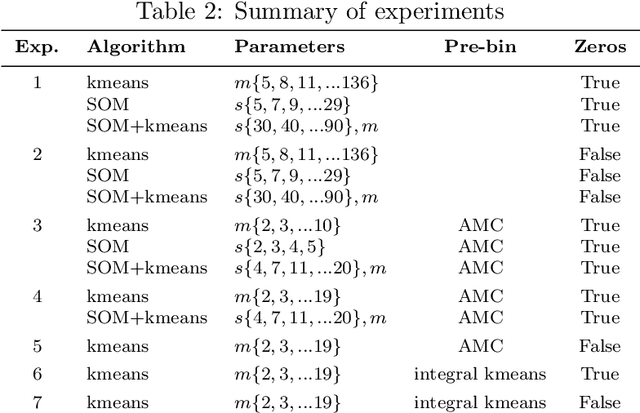
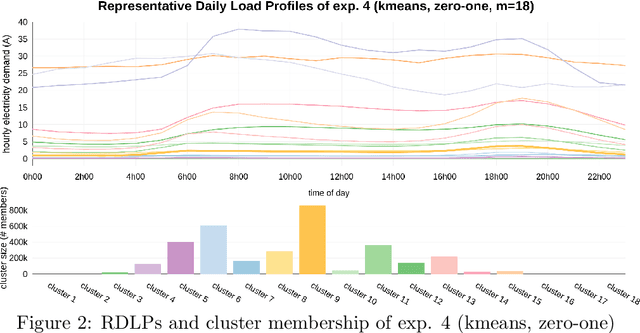
Time series clustering is frequently used in the energy domain to generate representative energy consumption patterns of households, which can be used to construct customer archetypes for long term energy planning. Selecting the optimal set of clusters however requires extensive experimentation and domain knowledge, and typically relies on a combination of metrics together with additional expert guidance through visual inspection of the clustering results. This can be time consuming, subjective and difficult to reproduce. In this work we present an approach that uses competency questions to elicit expert knowledge and to specify the requirements for creating residential energy customer archetypes from energy meter data. The approach enabled a structured and formal cluster analysis process, while easing cluster evaluation and reducing the time to select an optimal cluster set that satisfies the application requirements. The usefulness of the selected cluster set is demonstrated in a use case application that reconstructs a customer archetype developed manually by experts.
Design Considerations for High Impact, Automated Echocardiogram Analysis
Jun 19, 2020Deep learning has the potential to automate echocardiogram analysis for early detection of heart disease. Based on a qualitative analysis of design concerns, this study suggests that predicting normal heart function instead of disease accounts for data quality bias and significantly increases efficiency in cardiologists' workflows.
Machine Learning Systems for Intelligent Services in the IoT: A Survey
Jun 11, 2020
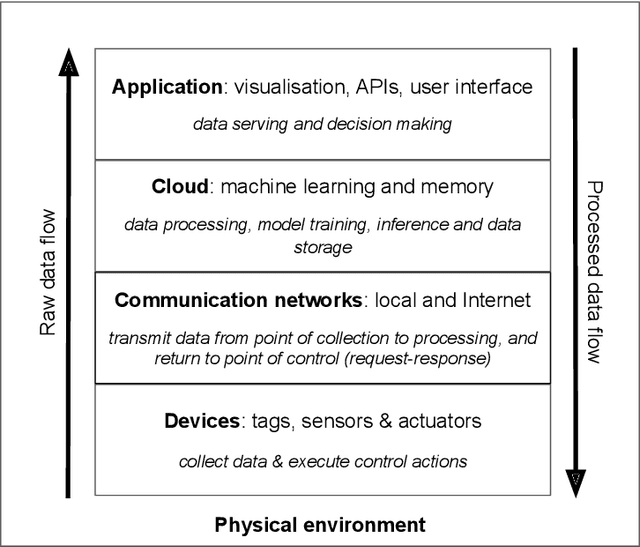
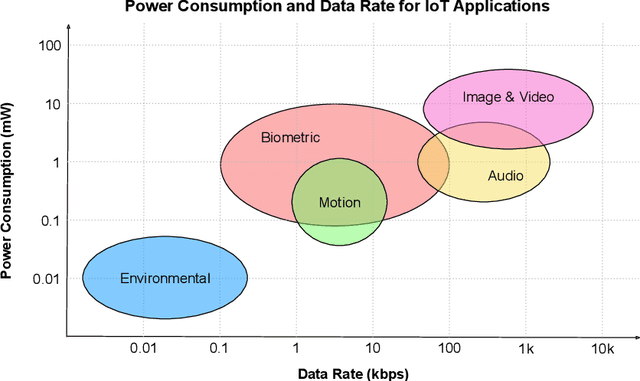

Machine learning (ML) technologies are emerging in the Internet of Things (IoT) to provision intelligent services. This survey moves beyond existing ML algorithms and cloud-driven design to investigate the less-explored systems, scaling and socio-technical aspects for consolidating ML and IoT. It covers the latest developments (up to 2020) on scaling and distributing ML across cloud, edge, and IoT devices. With a multi-layered framework to classify and illuminate system design choices, this survey exposes fundamental concerns of developing and deploying ML systems in the rising cloud-edge-device continuum in terms of functionality, stakeholder alignment and trustworthiness.
Using competency questions to select optimal clustering structures for residential energy consumption patterns
Jun 01, 2020

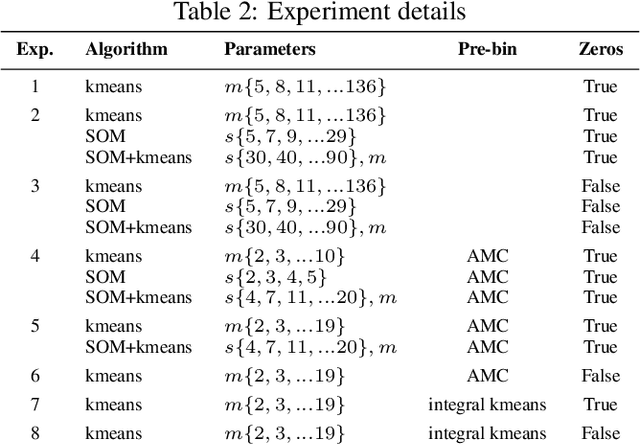

During cluster analysis domain experts and visual analysis are frequently relied on to identify the optimal clustering structure. This process tends to be adhoc, subjective and difficult to reproduce. This work shows how competency questions can be used to formalise expert knowledge and application requirements for context specific evaluation of a clustering application in the residential energy consumption sector.