 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Systems in Radiology: Design, Applications, Evaluation, and Challenges
Oct 10, 2025Building agents, systems that perceive and act upon their environment with a degree of autonomy, has long been a focus of AI research. This pursuit has recently become vastly more practical with the emergence of large language models (LLMs) capable of using natural language to integrate information, follow instructions, and perform forms of "reasoning" and planning across a wide range of tasks. With its multimodal data streams and orchestrated workflows spanning multiple systems, radiology is uniquely suited to benefit from agents that can adapt to context and automate repetitive yet complex tasks. In radiology, LLMs and their multimodal variants have already demonstrated promising performance for individual tasks such as information extraction and report summarization. However, using LLMs in isolation underutilizes their potential to support complex, multi-step workflows where decisions depend on evolving context from multiple information sources. Equipping LLMs with external tools and feedback mechanisms enables them to drive systems that exhibit a spectrum of autonomy, ranging from semi-automated workflows to more adaptive agents capable of managing complex processes. This review examines the design of such LLM-driven agentic systems, highlights key applications, discusses evaluation methods for planning and tool use, and outlines challenges such as error cascades, tool-use efficiency, and health IT integration.
Best Practices for Large Language Models in Radiology
Dec 02, 2024



At the heart of radiological practice is the challenge of integrating complex imaging data with clinical information to produce actionable insights. Nuanced application of language is key for various activities, including managing requests, describing and interpreting imaging findings in the context of clinical data, and concisely documenting and communicating the outcomes. The emergence of large language models (LLMs) offers an opportunity to improve the management and interpretation of the vast data in radiology. Despite being primarily general-purpose, these advanced computational models demonstrate impressive capabilities in specialized language-related tasks, even without specific training. Unlocking the potential of LLMs for radiology requires basic understanding of their foundations and a strategic approach to navigate their idiosyncrasies. This review, drawing from practical radiology and machine learning expertise and recent literature, provides readers insight into the potential of LLMs in radiology. It examines best practices that have so far stood the test of time in the rapidly evolving landscape of LLMs. This includes practical advice for optimizing LLM characteristics for radiology practices along with limitations, effective prompting, and fine-tuning strategies.
Detecting Underdiagnosed Medical Conditions with Deep Learning-Based Opportunistic CT Imaging
Sep 18, 2024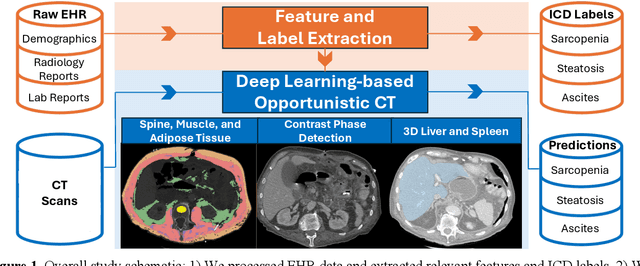
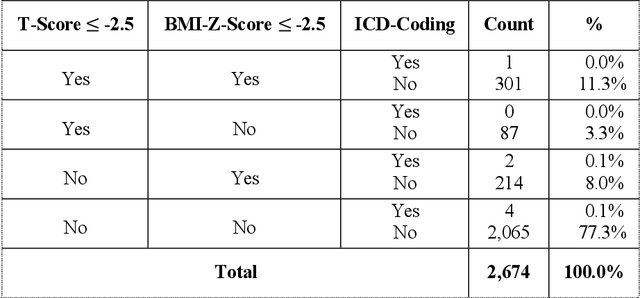
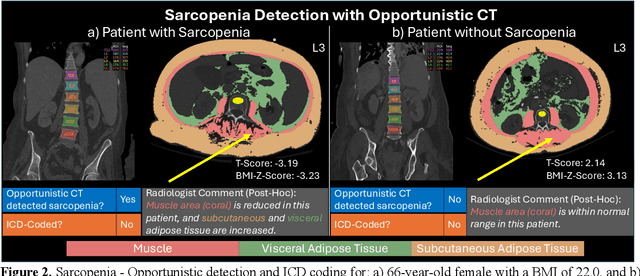
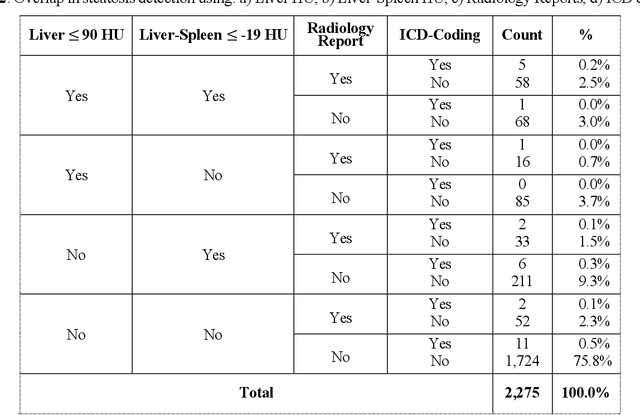
Abdominal computed tomography (CT) scans are frequently performed in clinical settings. Opportunistic CT involves repurposing routine CT images to extract diagnostic information and is an emerging tool for detecting underdiagnosed conditions such as sarcopenia, hepatic steatosis, and ascites. This study utilizes deep learning methods to promote accurate diagnosis and clinical documentation. We analyze 2,674 inpatient CT scans to identify discrepancies between imaging phenotypes (characteristics derived from opportunistic CT scans) and their corresponding documentation in radiology reports and ICD coding. Through our analysis, we find that only 0.5%, 3.2%, and 30.7% of scans diagnosed with sarcopenia, hepatic steatosis, and ascites (respectively) through either opportunistic imaging or radiology reports were ICD-coded. Our findings demonstrate opportunistic CT's potential to enhance diagnostic precision and accuracy of risk adjustment models, offering advancements in precision medicine.
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
A Benchmark of Domain-Adapted Large Language Models for Generating Brief Hospital Course Summaries
Mar 08, 2024



Brief hospital course (BHC) summaries are common clinical documents generated by summarizing clinical notes. While large language models (LLMs) depict remarkable capabilities in automating real-world tasks, their capabilities for healthcare applications such as BHC synthesis have not been shown. To enable the adaptation of LLMs for BHC synthesis, we introduce a novel benchmark consisting of a pre-processed dataset extracted from MIMIC-IV notes, encapsulating clinical note, and brief hospital course (BHC) pairs. We assess the performance of two general-purpose LLMs and three healthcare-adapted LLMs to improve BHC synthesis from clinical notes. Using clinical notes as input for generating BHCs, we apply prompting-based (using in-context learning) and fine-tuning-based adaptation strategies to three open-source LLMs (Clinical-T5-Large, Llama2-13B, FLAN-UL2) and two proprietary LLMs (GPT-3.5, GPT-4). We quantitatively evaluate the performance of these LLMs across varying context-length inputs using conventional natural language similarity metrics. We further perform a qualitative study where five diverse clinicians blindly compare clinician-written BHCs and two LLM-generated BHCs for 30 samples across metrics of comprehensiveness, conciseness, factual correctness, and fluency. Overall, we present a new benchmark and pre-processed dataset for using LLMs in BHC synthesis from clinical notes. We observe high-quality summarization performance for both in-context proprietary and fine-tuned open-source LLMs using both quantitative metrics and a qualitative clinical reader study. We propose our work as a benchmark to motivate future works to adapt and assess the performance of LLMs in BHC synthesis.
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
Jan 22, 2024



Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing \emph{CheXinstruct} - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present \emph{CheXagent} - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce \emph{CheXbench} - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. Our project is at \url{https://stanford-aimi.github.io/chexagent.html}.
Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
Sep 14, 2023Sifting through vast textual data and summarizing key information imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown immense promise in natural language processing (NLP) tasks, their efficacy across diverse clinical summarization tasks has not yet been rigorously examined. In this work, we employ domain adaptation methods on eight LLMs, spanning six datasets and four distinct summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Our thorough quantitative assessment reveals trade-offs between models and adaptation methods in addition to instances where recent advances in LLMs may not lead to improved results. Further, in a clinical reader study with six physicians, we depict that summaries from the best adapted LLM are preferable to human summaries in terms of completeness and correctness. Our ensuing qualitative analysis delineates mutual challenges faced by both LLMs and human experts. Lastly, we correlate traditional quantitative NLP metrics with reader study scores to enhance our understanding of how these metrics align with physician preferences. Our research marks the first evidence of LLMs outperforming human experts in clinical text summarization across multiple tasks. This implies that integrating LLMs into clinical workflows could alleviate documentation burden, empowering clinicians to focus more on personalized patient care and other irreplaceable human aspects of medicine.
RadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models
May 02, 2023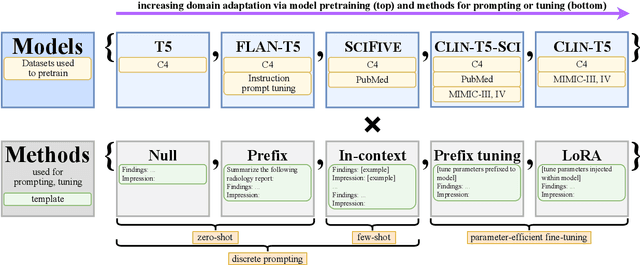
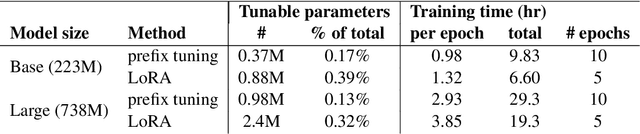
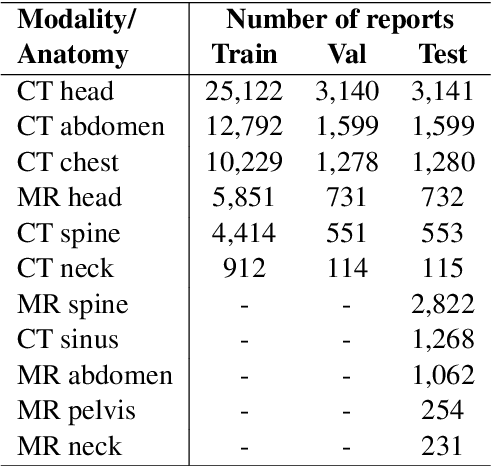

We systematically investigate lightweight strategies to adapt large language models (LLMs) for the task of radiology report summarization (RRS). Specifically, we focus on domain adaptation via pretraining (on natural language, biomedical text, and clinical text) and via prompting (zero-shot, in-context learning) or parameter-efficient fine-tuning (prefix tuning, LoRA). Our results on the MIMIC-III dataset consistently demonstrate best performance by maximally adapting to the task via pretraining on clinical text and parameter-efficient fine-tuning on RRS examples. Importantly, this method fine-tunes a mere 0.32% of parameters throughout the model, in contrast to end-to-end fine-tuning (100% of parameters). Additionally, we study the effect of in-context examples and out-of-distribution (OOD) training before concluding with a radiologist reader study and qualitative analysis. Our findings highlight the importance of domain adaptation in RRS and provide valuable insights toward developing effective natural language processing solutions for clinical tasks.
Scale-Agnostic Super-Resolution in MRI using Feature-Based Coordinate Networks
Oct 18, 2022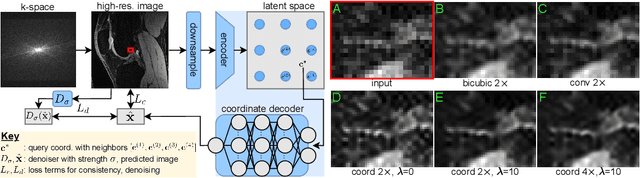
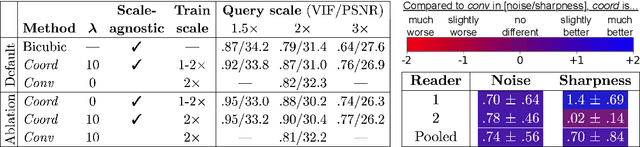
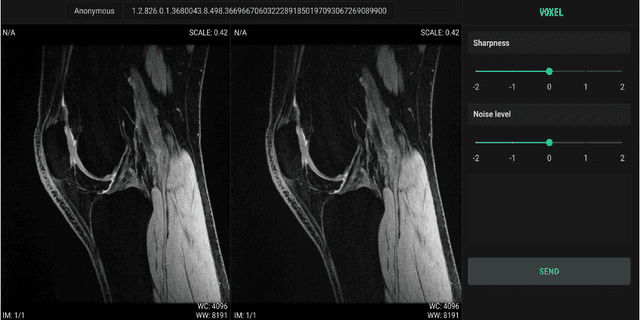
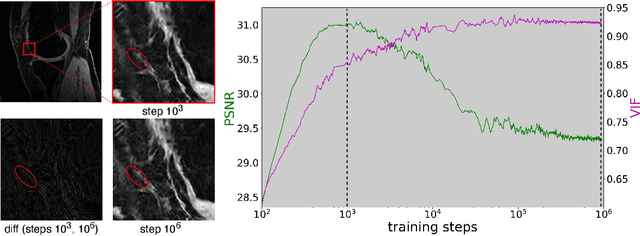
We propose using a coordinate network decoder for the task of super-resolution in MRI. The continuous signal representation of coordinate networks enables this approach to be scale-agnostic, i.e. one can train over a continuous range of scales and subsequently query at arbitrary resolutions. Due to the difficulty of performing super-resolution on inherently noisy data, we analyze network behavior under multiple denoising strategies. Lastly we compare this method to a standard convolutional decoder using both quantitative metrics and a radiologist study implemented in Voxel, our newly developed tool for web-based evaluation of medical images.
BACON: Band-limited Coordinate Networks for Multiscale Scene Representation
Dec 09, 2021

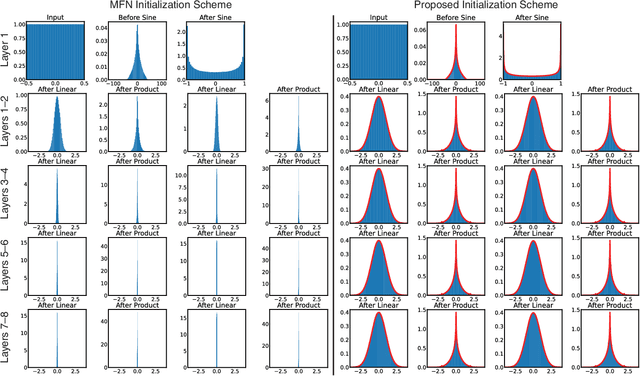
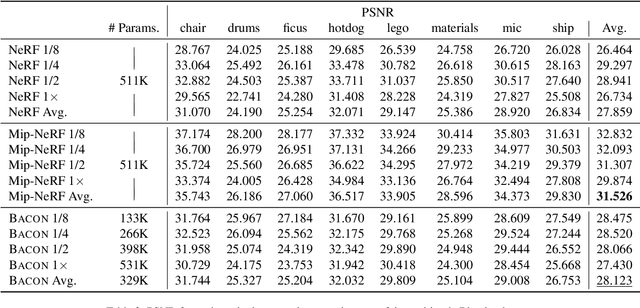
Coordinate-based networks have emerged as a powerful tool for 3D representation and scene reconstruction. These networks are trained to map continuous input coordinates to the value of a signal at each point. Still, current architectures are black boxes: their spectral characteristics cannot be easily analyzed, and their behavior at unsupervised points is difficult to predict. Moreover, these networks are typically trained to represent a signal at a single scale, and so naive downsampling or upsampling results in artifacts. We introduce band-limited coordinate networks (BACON), a network architecture with an analytical Fourier spectrum. BACON has predictable behavior at unsupervised points, can be designed based on the spectral characteristics of the represented signal, and can represent signals at multiple scales without explicit supervision. We demonstrate BACON for multiscale neural representation of images, radiance fields, and 3D scenes using signed distance functions and show that it outperforms conventional single-scale coordinate networks in terms of interpretability and quality.