 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Systems in Radiology: Design, Applications, Evaluation, and Challenges
Oct 10, 2025Building agents, systems that perceive and act upon their environment with a degree of autonomy, has long been a focus of AI research. This pursuit has recently become vastly more practical with the emergence of large language models (LLMs) capable of using natural language to integrate information, follow instructions, and perform forms of "reasoning" and planning across a wide range of tasks. With its multimodal data streams and orchestrated workflows spanning multiple systems, radiology is uniquely suited to benefit from agents that can adapt to context and automate repetitive yet complex tasks. In radiology, LLMs and their multimodal variants have already demonstrated promising performance for individual tasks such as information extraction and report summarization. However, using LLMs in isolation underutilizes their potential to support complex, multi-step workflows where decisions depend on evolving context from multiple information sources. Equipping LLMs with external tools and feedback mechanisms enables them to drive systems that exhibit a spectrum of autonomy, ranging from semi-automated workflows to more adaptive agents capable of managing complex processes. This review examines the design of such LLM-driven agentic systems, highlights key applications, discusses evaluation methods for planning and tool use, and outlines challenges such as error cascades, tool-use efficiency, and health IT integration.
RadVLM: A Multitask Conversational Vision-Language Model for Radiology
Feb 05, 2025



The widespread use of chest X-rays (CXRs), coupled with a shortage of radiologists, has driven growing interest in automated CXR analysis and AI-assisted reporting. While existing vision-language models (VLMs) show promise in specific tasks such as report generation or abnormality detection, they often lack support for interactive diagnostic capabilities. In this work we present RadVLM, a compact, multitask conversational foundation model designed for CXR interpretation. To this end, we curate a large-scale instruction dataset comprising over 1 million image-instruction pairs containing both single-turn tasks -- such as report generation, abnormality classification, and visual grounding -- and multi-turn, multi-task conversational interactions. After fine-tuning RadVLM on this instruction dataset, we evaluate it across different tasks along with re-implemented baseline VLMs. Our results show that RadVLM achieves state-of-the-art performance in conversational capabilities and visual grounding while remaining competitive in other radiology tasks. Ablation studies further highlight the benefit of joint training across multiple tasks, particularly for scenarios with limited annotated data. Together, these findings highlight the potential of RadVLM as a clinically relevant AI assistant, providing structured CXR interpretation and conversational capabilities to support more effective and accessible diagnostic workflows.
Best Practices for Large Language Models in Radiology
Dec 02, 2024



At the heart of radiological practice is the challenge of integrating complex imaging data with clinical information to produce actionable insights. Nuanced application of language is key for various activities, including managing requests, describing and interpreting imaging findings in the context of clinical data, and concisely documenting and communicating the outcomes. The emergence of large language models (LLMs) offers an opportunity to improve the management and interpretation of the vast data in radiology. Despite being primarily general-purpose, these advanced computational models demonstrate impressive capabilities in specialized language-related tasks, even without specific training. Unlocking the potential of LLMs for radiology requires basic understanding of their foundations and a strategic approach to navigate their idiosyncrasies. This review, drawing from practical radiology and machine learning expertise and recent literature, provides readers insight into the potential of LLMs in radiology. It examines best practices that have so far stood the test of time in the rapidly evolving landscape of LLMs. This includes practical advice for optimizing LLM characteristics for radiology practices along with limitations, effective prompting, and fine-tuning strategies.
An Empirical Analysis for Zero-Shot Multi-Label Classification on COVID-19 CT Scans and Uncurated Reports
Sep 06, 2023The pandemic resulted in vast repositories of unstructured data, including radiology reports, due to increased medical examinations. Previous research on automated diagnosis of COVID-19 primarily focuses on X-ray images, despite their lower precision compared to computed tomography (CT) scans. In this work, we leverage unstructured data from a hospital and harness the fine-grained details offered by CT scans to perform zero-shot multi-label classification based on contrastive visual language learning. In collaboration with human experts, we investigate the effectiveness of multiple zero-shot models that aid radiologists in detecting pulmonary embolisms and identifying intricate lung details like ground glass opacities and consolidations. Our empirical analysis provides an overview of the possible solutions to target such fine-grained tasks, so far overlooked in the medical multimodal pretraining literature. Our investigation promises future advancements in the medical image analysis community by addressing some challenges associated with unstructured data and fine-grained multi-label classification.
Progressive Transformer-Based Generation of Radiology Reports
Feb 19, 2021
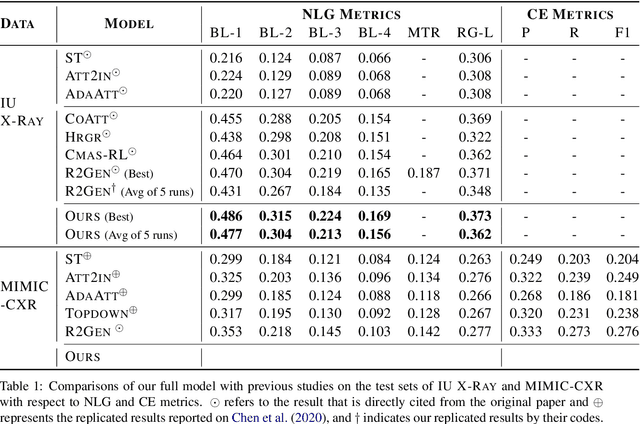
Inspired by Curriculum Learning, we propose a consecutive (i.e. image-to-text-to-text) generation framework where we divide the problem of radiology report generation into two steps. Contrary to generating the full radiology report from the image at once, the model generates global concepts from the image in the first step and then reforms them into finer and coherent texts using transformer-based architecture. We follow the transformer-based sequence-to-sequence paradigm at each step. We improve upon the state-of-the-art on two benchmark datasets.