 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Machine Unlearning: Models Designed to Forget via Key Deletion
Mar 16, 2026Machine unlearning is rapidly becoming a practical requirement, driven by privacy regulations, data errors, and the need to remove harmful or corrupted training samples. Despite this, most existing methods tackle the problem purely from a post-hoc perspective. They attempt to erase the influence of targeted training samples through parameter updates that typically require access to the full training data. This creates a mismatch with real deployment scenarios where unlearning requests can be anticipated, revealing a fundamental limitation of post-hoc approaches. We propose \textit{unlearning by design}, a novel paradigm in which models are directly trained to support forgetting as an inherent capability. We instantiate this idea with Machine UNlearning via KEY deletion (MUNKEY), a memory augmented transformer that decouples instance-specific memorization from model weights. Here, unlearning corresponds to removing the instance-identifying key, enabling direct zero-shot forgetting without weight updates or access to the original samples or labels. Across natural image benchmarks, fine-grained recognition, and medical datasets, MUNKEY outperforms all post-hoc baselines. Our results establish that unlearning by design enables fast, deployment-oriented unlearning while preserving predictive performance.
From Pixels to Components: Eigenvector Masking for Visual Representation Learning
Feb 10, 2025



Predicting masked from visible parts of an image is a powerful self-supervised approach for visual representation learning. However, the common practice of masking random patches of pixels exhibits certain failure modes, which can prevent learning meaningful high-level features, as required for downstream tasks. We propose an alternative masking strategy that operates on a suitable transformation of the data rather than on the raw pixels. Specifically, we perform principal component analysis and then randomly mask a subset of components, which accounts for a fixed ratio of the data variance. The learning task then amounts to reconstructing the masked components from the visible ones. Compared to local patches of pixels, the principal components of images carry more global information. We thus posit that predicting masked from visible components involves more high-level features, allowing our masking strategy to extract more useful representations. This is corroborated by our empirical findings which demonstrate improved image classification performance for component over pixel masking. Our method thus constitutes a simple and robust data-driven alternative to traditional masked image modeling approaches.
RadVLM: A Multitask Conversational Vision-Language Model for Radiology
Feb 05, 2025



The widespread use of chest X-rays (CXRs), coupled with a shortage of radiologists, has driven growing interest in automated CXR analysis and AI-assisted reporting. While existing vision-language models (VLMs) show promise in specific tasks such as report generation or abnormality detection, they often lack support for interactive diagnostic capabilities. In this work we present RadVLM, a compact, multitask conversational foundation model designed for CXR interpretation. To this end, we curate a large-scale instruction dataset comprising over 1 million image-instruction pairs containing both single-turn tasks -- such as report generation, abnormality classification, and visual grounding -- and multi-turn, multi-task conversational interactions. After fine-tuning RadVLM on this instruction dataset, we evaluate it across different tasks along with re-implemented baseline VLMs. Our results show that RadVLM achieves state-of-the-art performance in conversational capabilities and visual grounding while remaining competitive in other radiology tasks. Ablation studies further highlight the benefit of joint training across multiple tasks, particularly for scenarios with limited annotated data. Together, these findings highlight the potential of RadVLM as a clinically relevant AI assistant, providing structured CXR interpretation and conversational capabilities to support more effective and accessible diagnostic workflows.
From Logits to Hierarchies: Hierarchical Clustering made Simple
Oct 10, 2024



The structure of many real-world datasets is intrinsically hierarchical, making the modeling of such hierarchies a critical objective in both unsupervised and supervised machine learning. Recently, novel approaches for hierarchical clustering with deep architectures have been proposed. In this work, we take a critical perspective on this line of research and demonstrate that many approaches exhibit major limitations when applied to realistic datasets, partly due to their high computational complexity. In particular, we show that a lightweight procedure implemented on top of pre-trained non-hierarchical clustering models outperforms models designed specifically for hierarchical clustering. Our proposed approach is computationally efficient and applicable to any pre-trained clustering model that outputs logits, without requiring any fine-tuning. To highlight the generality of our findings, we illustrate how our method can also be applied in a supervised setup, recovering meaningful hierarchies from a pre-trained ImageNet classifier.
Anomaly Detection by Context Contrasting
May 29, 2024


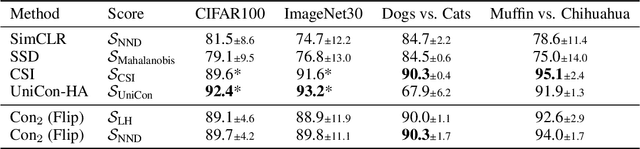
Anomaly Detection focuses on identifying samples that deviate from the norm. When working with high-dimensional data such as images, a crucial requirement for detecting anomalous patterns is learning lower-dimensional representations that capture normal concepts seen during training. Recent advances in self-supervised learning have shown great promise in this regard. However, many of the most successful self-supervised anomaly detection methods assume prior knowledge about the structure of anomalies and leverage synthetic anomalies during training. Yet, in many real-world applications, we do not know what to expect from unseen data, and we can solely leverage knowledge about normal data. In this work, we propose Con2, which addresses this problem by setting normal training data into distinct contexts while preserving its normal properties, letting us observe the data from different perspectives. Unseen normal data consequently adheres to learned context representations while anomalies fail to do so, letting us detect them without any knowledge about anomalies during training. Our experiments demonstrate that our approach achieves state-of-the-art performance on various benchmarks while exhibiting superior performance in a more realistic healthcare setting, where knowledge about potential anomalies is often scarce.
Tree Variational Autoencoders
Jul 01, 2023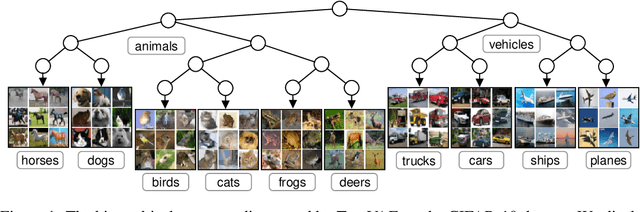
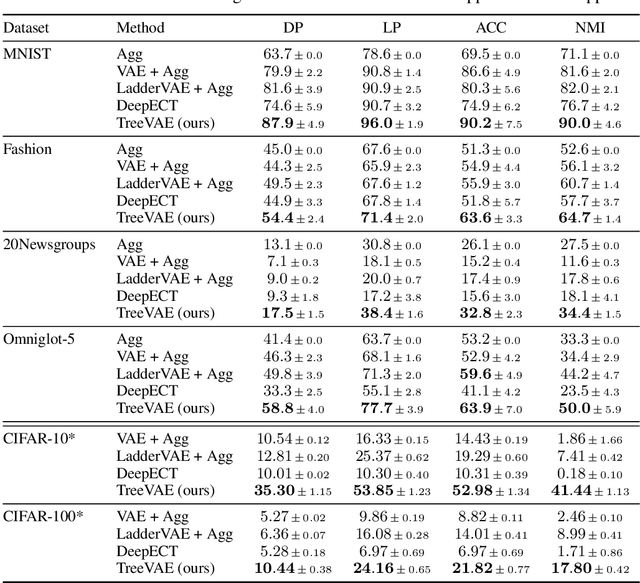
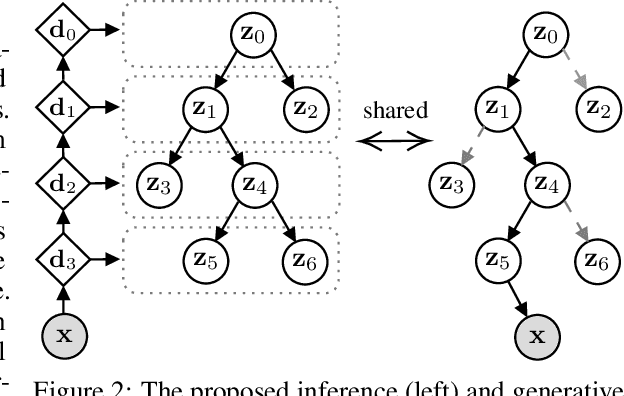
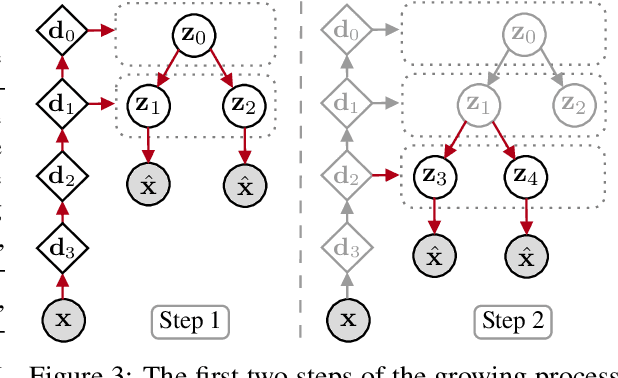
We propose a new generative hierarchical clustering model that learns a flexible tree-based posterior distribution over latent variables. The proposed Tree Variational Autoencoder (TreeVAE) hierarchically divides samples according to their intrinsic characteristics, shedding light on hidden structure in the data. It adapts its architecture to discover the optimal tree for encoding dependencies between latent variables. The proposed tree-based generative architecture permits lightweight conditional inference and improves generative performance by utilizing specialized leaf decoders. We show that TreeVAE uncovers underlying clusters in the data and finds meaningful hierarchical relations between the different groups on a variety of datasets, including real-world imaging data. We present empirically that TreeVAE provides a more competitive log-likelihood lower bound than the sequential counterparts. Finally, due to its generative nature, TreeVAE is able to generate new samples from the discovered clusters via conditional sampling.
Differentiable Random Partition Models
May 26, 2023



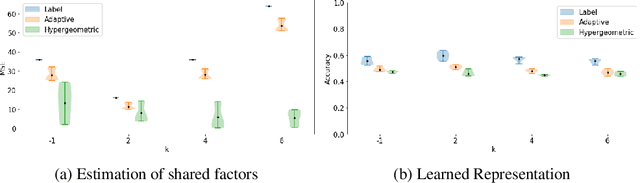
Partitioning a set of elements into an unknown number of mutually exclusive subsets is essential in many machine learning problems. However, assigning elements, such as samples in a dataset or neurons in a network layer, to an unknown and discrete number of subsets is inherently non-differentiable, prohibiting end-to-end gradient-based optimization of parameters. We overcome this limitation by proposing a novel two-step method for inferring partitions, which allows its usage in variational inference tasks. This new approach enables reparameterized gradients with respect to the parameters of the new random partition model. Our method works by inferring the number of elements per subset and, second, by filling these subsets in a learned order. We highlight the versatility of our general-purpose approach on three different challenging experiments: variational clustering, inference of shared and independent generative factors under weak supervision, and multitask learning.
Interpretable Anomaly Detection in Echocardiograms with Dynamic Variational Trajectory Models
Jun 30, 2022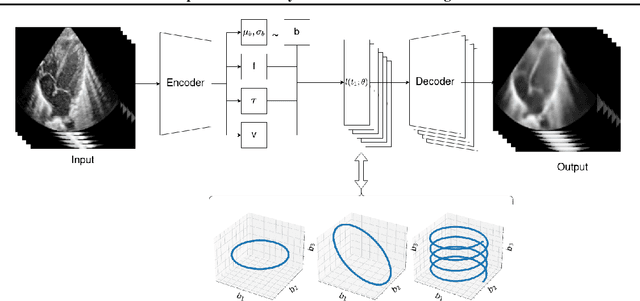
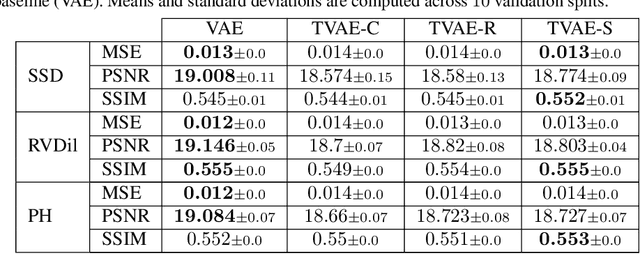

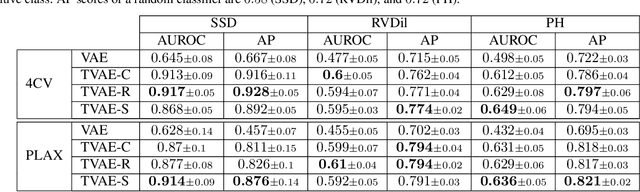
We propose a novel anomaly detection method for echocardiogram videos. The introduced method takes advantage of the periodic nature of the heart cycle to learn different variants of a variational latent trajectory model (TVAE). The models are trained on the healthy samples of an in-house dataset of infant echocardiogram videos consisting of multiple chamber views to learn a normative prior of the healthy population. During inference, maximum a posteriori (MAP) based anomaly detection is performed to detect out-of-distribution samples in our dataset. The proposed method reliably identifies severe congenital heart defects, such as Ebstein's Anomaly or Shonecomplex. Moreover, it achieves superior performance over MAP-based anomaly detection with standard variational autoencoders on the task of detecting pulmonary hypertension and right ventricular dilation. Finally, we demonstrate that the proposed method provides interpretable explanations of its output through heatmaps which highlight the regions corresponding to anomalous heart structures.
Continuous Relaxation For The Multivariate Non-Central Hypergeometric Distribution
Mar 03, 2022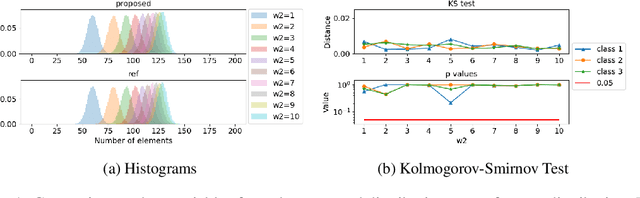
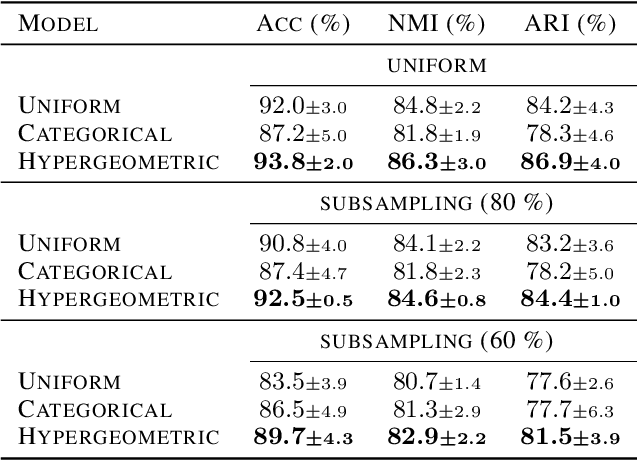
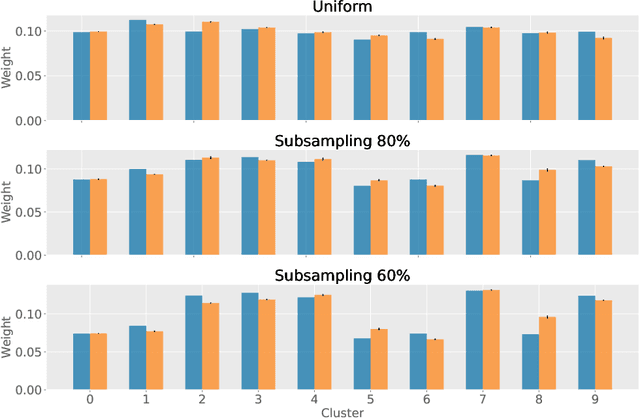
Partitioning a set of elements into a given number of groups of a priori unknown sizes is an important task in many applications. Due to hard constraints, it is a non-differentiable problem which prohibits its direct use in modern machine learning frameworks. Hence, previous works mostly fall back on suboptimal heuristics or simplified assumptions. The multivariate hypergeometric distribution offers a probabilistic formulation of how to distribute a given number of samples across multiple groups. Unfortunately, as a discrete probability distribution, it neither is differentiable. In this work, we propose a continuous relaxation for the multivariate non-central hypergeometric distribution. We introduce an efficient and numerically stable sampling procedure. This enables reparameterized gradients for the hypergeometric distribution and its integration into automatic differentiation frameworks. We highlight the applicability and usability of the proposed formulation on two different common machine learning tasks.