 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgescSSL-Bench: Benchmarking Self-Supervised Learning for Single-Cell Data
Jun 10, 2025Self-supervised learning (SSL) has proven to be a powerful approach for extracting biologically meaningful representations from single-cell data. To advance our understanding of SSL methods applied to single-cell data, we present scSSL-Bench, a comprehensive benchmark that evaluates nineteen SSL methods. Our evaluation spans nine datasets and focuses on three common downstream tasks: batch correction, cell type annotation, and missing modality prediction. Furthermore, we systematically assess various data augmentation strategies. Our analysis reveals task-specific trade-offs: the specialized single-cell frameworks, scVI, CLAIRE, and the finetuned scGPT excel at uni-modal batch correction, while generic SSL methods, such as VICReg and SimCLR, demonstrate superior performance in cell typing and multi-modal data integration. Random masking emerges as the most effective augmentation technique across all tasks, surpassing domain-specific augmentations. Notably, our results indicate the need for a specialized single-cell multi-modal data integration framework. scSSL-Bench provides a standardized evaluation platform and concrete recommendations for applying SSL to single-cell analysis, advancing the convergence of deep learning and single-cell genomics.
From Logits to Hierarchies: Hierarchical Clustering made Simple
Oct 10, 2024



The structure of many real-world datasets is intrinsically hierarchical, making the modeling of such hierarchies a critical objective in both unsupervised and supervised machine learning. Recently, novel approaches for hierarchical clustering with deep architectures have been proposed. In this work, we take a critical perspective on this line of research and demonstrate that many approaches exhibit major limitations when applied to realistic datasets, partly due to their high computational complexity. In particular, we show that a lightweight procedure implemented on top of pre-trained non-hierarchical clustering models outperforms models designed specifically for hierarchical clustering. Our proposed approach is computationally efficient and applicable to any pre-trained clustering model that outputs logits, without requiring any fine-tuning. To highlight the generality of our findings, we illustrate how our method can also be applied in a supervised setup, recovering meaningful hierarchies from a pre-trained ImageNet classifier.
Benchmarking the Fairness of Image Upsampling Methods
Jan 24, 2024
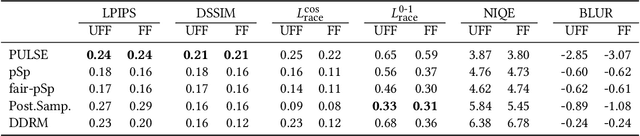
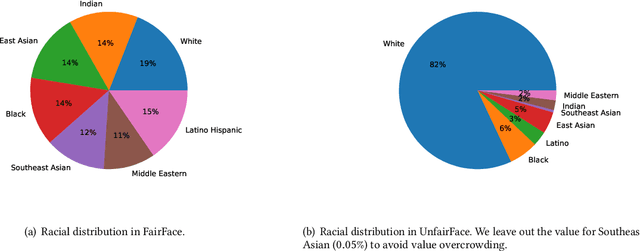
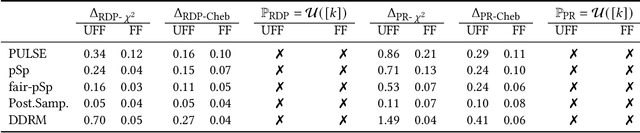
Recent years have witnessed a rapid development of deep generative models for creating synthetic media, such as images and videos. While the practical applications of these models in everyday tasks are enticing, it is crucial to assess the inherent risks regarding their fairness. In this work, we introduce a comprehensive framework for benchmarking the performance and fairness of conditional generative models. We develop a set of metrics$\unicode{x2013}$inspired by their supervised fairness counterparts$\unicode{x2013}$to evaluate the models on their fairness and diversity. Focusing on the specific application of image upsampling, we create a benchmark covering a wide variety of modern upsampling methods. As part of the benchmark, we introduce UnfairFace, a subset of FairFace that replicates the racial distribution of common large-scale face datasets. Our empirical study highlights the importance of using an unbiased training set and reveals variations in how the algorithms respond to dataset imbalances. Alarmingly, we find that none of the considered methods produces statistically fair and diverse results.
Identifiability Results for Multimodal Contrastive Learning
Mar 16, 2023



Contrastive learning is a cornerstone underlying recent progress in multi-view and multimodal learning, e.g., in representation learning with image/caption pairs. While its effectiveness is not yet fully understood, a line of recent work reveals that contrastive learning can invert the data generating process and recover ground truth latent factors shared between views. In this work, we present new identifiability results for multimodal contrastive learning, showing that it is possible to recover shared factors in a more general setup than the multi-view setting studied previously. Specifically, we distinguish between the multi-view setting with one generative mechanism (e.g., multiple cameras of the same type) and the multimodal setting that is characterized by distinct mechanisms (e.g., cameras and microphones). Our work generalizes previous identifiability results by redefining the generative process in terms of distinct mechanisms with modality-specific latent variables. We prove that contrastive learning can block-identify latent factors shared between modalities, even when there are nontrivial dependencies between factors. We empirically verify our identifiability results with numerical simulations and corroborate our findings on a complex multimodal dataset of image/text pairs. Zooming out, our work provides a theoretical basis for multimodal representation learning and explains in which settings multimodal contrastive learning can be effective in practice.
How robust are pre-trained models to distribution shift?
Jun 17, 2022

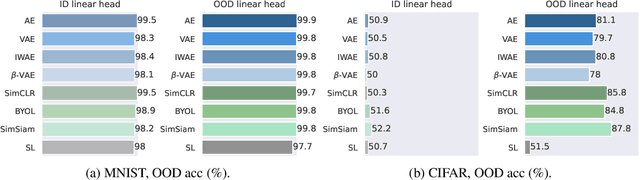

The vulnerability of machine learning models to spurious correlations has mostly been discussed in the context of supervised learning (SL). However, there is a lack of insight on how spurious correlations affect the performance of popular self-supervised learning (SSL) and auto-encoder based models (AE). In this work, we shed light on this by evaluating the performance of these models on both real world and synthetic distribution shift datasets. Following observations that the linear head itself can be susceptible to spurious correlations, we develop a novel evaluation scheme with the linear head trained on out-of-distribution (OOD) data, to isolate the performance of the pre-trained models from a potential bias of the linear head used for evaluation. With this new methodology, we show that SSL models are consistently more robust to distribution shifts and thus better at OOD generalisation than AE and SL models.
On the Limitations of Multimodal VAEs
Oct 08, 2021

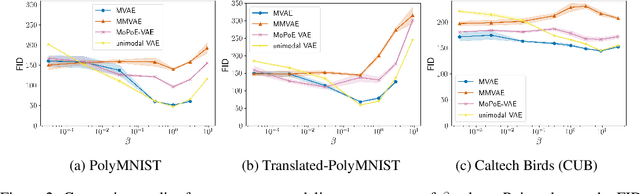
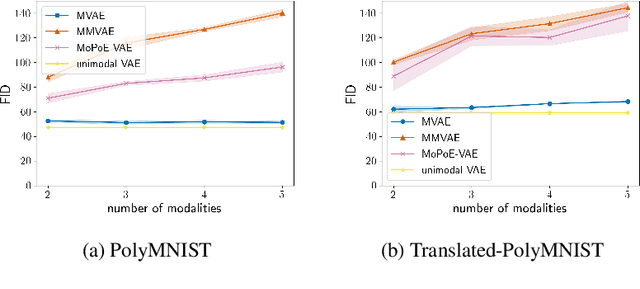
Multimodal variational autoencoders (VAEs) have shown promise as efficient generative models for weakly-supervised data. Yet, despite their advantage of weak supervision, they exhibit a gap in generative quality compared to unimodal VAEs, which are completely unsupervised. In an attempt to explain this gap, we uncover a fundamental limitation that applies to a large family of mixture-based multimodal VAEs. We prove that the sub-sampling of modalities enforces an undesirable upper bound on the multimodal ELBO and thereby limits the generative quality of the respective models. Empirically, we showcase the generative quality gap on both synthetic and real data and present the tradeoffs between different variants of multimodal VAEs. We find that none of the existing approaches fulfills all desired criteria of an effective multimodal generative model when applied on more complex datasets than those used in previous benchmarks. In summary, we identify, formalize, and validate fundamental limitations of VAE-based approaches for modeling weakly-supervised data and discuss implications for real-world applications.
Generalized Multimodal ELBO
May 06, 2021
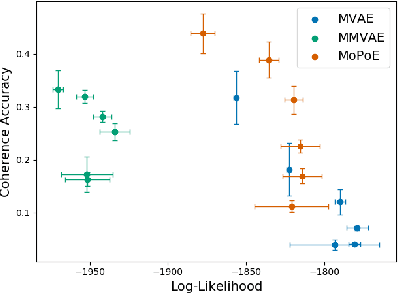

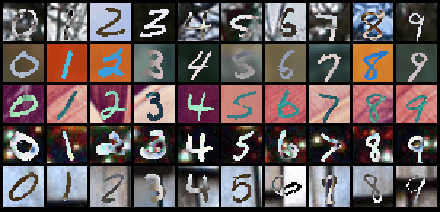
Multiple data types naturally co-occur when describing real-world phenomena and learning from them is a long-standing goal in machine learning research. However, existing self-supervised generative models approximating an ELBO are not able to fulfill all desired requirements of multimodal models: their posterior approximation functions lead to a trade-off between the semantic coherence and the ability to learn the joint data distribution. We propose a new, generalized ELBO formulation for multimodal data that overcomes these limitations. The new objective encompasses two previous methods as special cases and combines their benefits without compromises. In extensive experiments, we demonstrate the advantage of the proposed method compared to state-of-the-art models in self-supervised, generative learning tasks.
Multimodal Generative Learning Utilizing Jensen-Shannon-Divergence
Jun 15, 2020
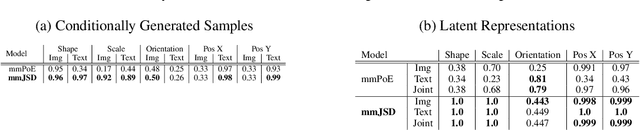

Learning from different data types is a long-standing goal in machine learning research, as multiple information sources co-occur when describing natural phenomena. However, existing generative models that approximate a multimodal ELBO rely on difficult or inefficient training schemes to learn a joint distribution and the dependencies between modalities. In this work, we propose a novel, efficient objective function that utilizes the Jensen-Shannon divergence for multiple distributions. It simultaneously approximates the unimodal and joint multimodal posteriors directly via a dynamic prior. In addition, we theoretically prove that the new multimodal JS-divergence (mmJSD) objective optimizes an ELBO. In extensive experiments, we demonstrate the advantage of the proposed mmJSD model compared to previous work in unsupervised, generative learning tasks.