 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Fairness of Image Upsampling Methods
Paper and Code

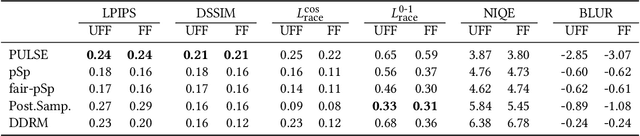
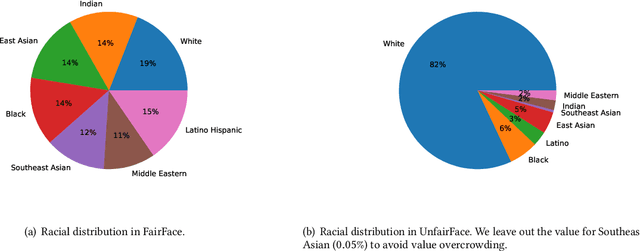
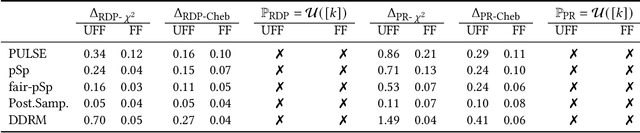
Recent years have witnessed a rapid development of deep generative models for creating synthetic media, such as images and videos. While the practical applications of these models in everyday tasks are enticing, it is crucial to assess the inherent risks regarding their fairness. In this work, we introduce a comprehensive framework for benchmarking the performance and fairness of conditional generative models. We develop a set of metrics$\unicode{x2013}$inspired by their supervised fairness counterparts$\unicode{x2013}$to evaluate the models on their fairness and diversity. Focusing on the specific application of image upsampling, we create a benchmark covering a wide variety of modern upsampling methods. As part of the benchmark, we introduce UnfairFace, a subset of FairFace that replicates the racial distribution of common large-scale face datasets. Our empirical study highlights the importance of using an unbiased training set and reveals variations in how the algorithms respond to dataset imbalances. Alarmingly, we find that none of the considered methods produces statistically fair and diverse results.