 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Components: Eigenvector Masking for Visual Representation Learning
Feb 10, 2025



Predicting masked from visible parts of an image is a powerful self-supervised approach for visual representation learning. However, the common practice of masking random patches of pixels exhibits certain failure modes, which can prevent learning meaningful high-level features, as required for downstream tasks. We propose an alternative masking strategy that operates on a suitable transformation of the data rather than on the raw pixels. Specifically, we perform principal component analysis and then randomly mask a subset of components, which accounts for a fixed ratio of the data variance. The learning task then amounts to reconstructing the masked components from the visible ones. Compared to local patches of pixels, the principal components of images carry more global information. We thus posit that predicting masked from visible components involves more high-level features, allowing our masking strategy to extract more useful representations. This is corroborated by our empirical findings which demonstrate improved image classification performance for component over pixel masking. Our method thus constitutes a simple and robust data-driven alternative to traditional masked image modeling approaches.
Generation of Differentially Private Heterogeneous Electronic Health Records
Jun 05, 2020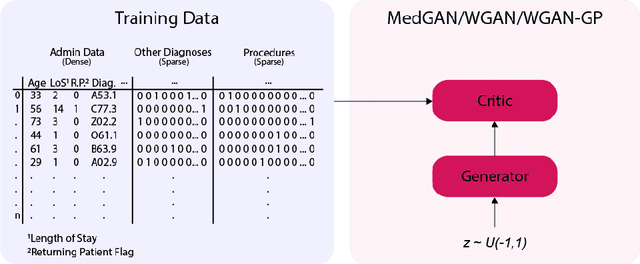
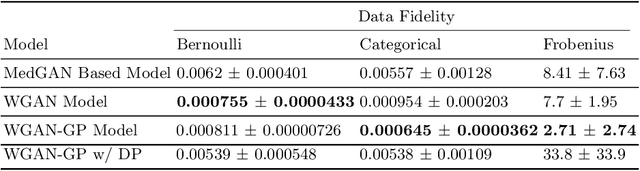
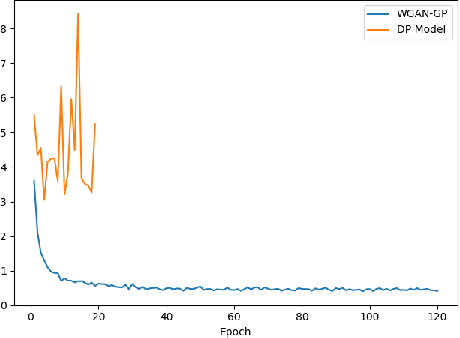
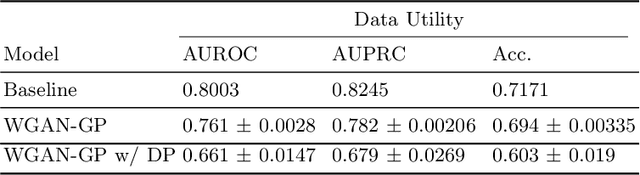
Electronic Health Records (EHRs) are commonly used by the machine learning community for research on problems specifically related to health care and medicine. EHRs have the advantages that they can be easily distributed and contain many features useful for e.g. classification problems. What makes EHR data sets different from typical machine learning data sets is that they are often very sparse, due to their high dimensionality, and often contain heterogeneous (mixed) data types. Furthermore, the data sets deal with sensitive information, which limits the distribution of any models learned using them, due to privacy concerns. For these reasons, using EHR data in practice presents a real challenge. In this work, we explore using Generative Adversarial Networks to generate synthetic, heterogeneous EHRs with the goal of using these synthetic records in place of existing data sets for downstream classification tasks. We will further explore applying differential privacy (DP) preserving optimization in order to produce DP synthetic EHR data sets, which provide rigorous privacy guarantees, and are therefore shareable and usable in the real world. The performance (measured by AUROC, AUPRC and accuracy) of our model's synthetic, heterogeneous data is very close to the original data set (within 3 - 5% of the baseline) for the non-DP model when tested in a binary classification task. Using strong $(1, 10^{-5})$ DP, our model still produces data useful for machine learning tasks, albeit incurring a roughly 17% performance penalty in our tested classification task. We additionally perform a sub-population analysis and find that our model does not introduce any bias into the synthetic EHR data compared to the baseline in either male/female populations, or the 0-18, 19-50 and 51+ age groups in terms of classification performance for either the non-DP or DP variant.