 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Domain Causal Empirical Bayes Under Linear Mixing
Mar 19, 2026Causal representation learning (CRL) aims to learn low-dimensional causal latent variables from high-dimensional observations. While identifiability has been extensively studied for CRL, estimation has been less explored. In this paper, we explore the use of empirical Bayes (EB) to estimate causal representations. In particular, we consider the problem of learning from data from multiple domains, where differences between domains are modeled by interventions in a shared underlying causal model. Multi-domain CRL naturally poses a simultaneous inference problem that EB is designed to tackle. Here, we propose an EB $f$-modeling algorithm that improves the quality of learned causal variables by exploiting invariant structure within and across domains. Specifically, we consider a linear measurement model and interventional priors arising from a shared acyclic SCM. When the graph and intervention targets are known, we develop an EM-style algorithm based on causally structured score matching. We further discuss EB $\rmg$-modeling in the context of existing CRL approaches. In experiments on synthetic data, our proposed method achieves more accurate estimation than other methods for CRL.
Transferring Causal Effects using Proxies
Oct 29, 2025We consider the problem of estimating a causal effect in a multi-domain setting. The causal effect of interest is confounded by an unobserved confounder and can change between the different domains. We assume that we have access to a proxy of the hidden confounder and that all variables are discrete or categorical. We propose methodology to estimate the causal effect in the target domain, where we assume to observe only the proxy variable. Under these conditions, we prove identifiability (even when treatment and response variables are continuous). We introduce two estimation techniques, prove consistency, and derive confidence intervals. The theoretical results are supported by simulation studies and a real-world example studying the causal effect of website rankings on consumer choices.
Representation Learning for Distributional Perturbation Extrapolation
Apr 25, 2025We consider the problem of modelling the effects of unseen perturbations such as gene knockdowns or drug combinations on low-level measurements such as RNA sequencing data. Specifically, given data collected under some perturbations, we aim to predict the distribution of measurements for new perturbations. To address this challenging extrapolation task, we posit that perturbations act additively in a suitable, unknown embedding space. More precisely, we formulate the generative process underlying the observed data as a latent variable model, in which perturbations amount to mean shifts in latent space and can be combined additively. Unlike previous work, we prove that, given sufficiently diverse training perturbations, the representation and perturbation effects are identifiable up to affine transformation, and use this to characterize the class of unseen perturbations for which we obtain extrapolation guarantees. To estimate the model from data, we propose a new method, the perturbation distribution autoencoder (PDAE), which is trained by maximising the distributional similarity between true and predicted perturbation distributions. The trained model can then be used to predict previously unseen perturbation distributions. Empirical evidence suggests that PDAE compares favourably to existing methods and baselines at predicting the effects of unseen perturbations.
From Pixels to Components: Eigenvector Masking for Visual Representation Learning
Feb 10, 2025



Predicting masked from visible parts of an image is a powerful self-supervised approach for visual representation learning. However, the common practice of masking random patches of pixels exhibits certain failure modes, which can prevent learning meaningful high-level features, as required for downstream tasks. We propose an alternative masking strategy that operates on a suitable transformation of the data rather than on the raw pixels. Specifically, we perform principal component analysis and then randomly mask a subset of components, which accounts for a fixed ratio of the data variance. The learning task then amounts to reconstructing the masked components from the visible ones. Compared to local patches of pixels, the principal components of images carry more global information. We thus posit that predicting masked from visible components involves more high-level features, allowing our masking strategy to extract more useful representations. This is corroborated by our empirical findings which demonstrate improved image classification performance for component over pixel masking. Our method thus constitutes a simple and robust data-driven alternative to traditional masked image modeling approaches.
Interaction Asymmetry: A General Principle for Learning Composable Abstractions
Nov 12, 2024Learning disentangled representations of concepts and re-composing them in unseen ways is crucial for generalizing to out-of-domain situations. However, the underlying properties of concepts that enable such disentanglement and compositional generalization remain poorly understood. In this work, we propose the principle of interaction asymmetry which states: "Parts of the same concept have more complex interactions than parts of different concepts". We formalize this via block diagonality conditions on the $(n+1)$th order derivatives of the generator mapping concepts to observed data, where different orders of "complexity" correspond to different $n$. Using this formalism, we prove that interaction asymmetry enables both disentanglement and compositional generalization. Our results unify recent theoretical results for learning concepts of objects, which we show are recovered as special cases with $n\!=\!0$ or $1$. We provide results for up to $n\!=\!2$, thus extending these prior works to more flexible generator functions, and conjecture that the same proof strategies generalize to larger $n$. Practically, our theory suggests that, to disentangle concepts, an autoencoder should penalize its latent capacity and the interactions between concepts during decoding. We propose an implementation of these criteria using a flexible Transformer-based VAE, with a novel regularizer on the attention weights of the decoder. On synthetic image datasets consisting of objects, we provide evidence that this model can achieve comparable object disentanglement to existing models that use more explicit object-centric priors.
Identifiable Causal Representation Learning: Unsupervised, Multi-View, and Multi-Environment
Jun 19, 2024Causal models provide rich descriptions of complex systems as sets of mechanisms by which each variable is influenced by its direct causes. They support reasoning about manipulating parts of the system and thus hold promise for addressing some of the open challenges of artificial intelligence (AI), such as planning, transferring knowledge in changing environments, or robustness to distribution shifts. However, a key obstacle to more widespread use of causal models in AI is the requirement that the relevant variables be specified a priori, which is typically not the case for the high-dimensional, unstructured data processed by modern AI systems. At the same time, machine learning (ML) has proven quite successful at automatically extracting useful and compact representations of such complex data. Causal representation learning (CRL) aims to combine the core strengths of ML and causality by learning representations in the form of latent variables endowed with causal model semantics. In this thesis, we study and present new results for different CRL settings. A central theme is the question of identifiability: Given infinite data, when are representations satisfying the same learning objective guaranteed to be equivalent? This is an important prerequisite for CRL, as it formally characterises if and when a learning task is, at least in principle, feasible. Since learning causal models, even without a representation learning component, is notoriously difficult, we require additional assumptions on the model class or rich data beyond the classical i.i.d. setting. By partially characterising identifiability for different settings, this thesis investigates what is possible for CRL without direct supervision, and thus contributes to its theoretical foundations. Ideally, the developed insights can help inform data collection practices or inspire the design of new practical estimation methods.
* PhD Thesis; 190 pages, 33 figures, 6 tables
A Sparsity Principle for Partially Observable Causal Representation Learning
Mar 13, 2024



Causal representation learning aims at identifying high-level causal variables from perceptual data. Most methods assume that all latent causal variables are captured in the high-dimensional observations. We instead consider a partially observed setting, in which each measurement only provides information about a subset of the underlying causal state. Prior work has studied this setting with multiple domains or views, each depending on a fixed subset of latents. Here, we focus on learning from unpaired observations from a dataset with an instance-dependent partial observability pattern. Our main contribution is to establish two identifiability results for this setting: one for linear mixing functions without parametric assumptions on the underlying causal model, and one for piecewise linear mixing functions with Gaussian latent causal variables. Based on these insights, we propose two methods for estimating the underlying causal variables by enforcing sparsity in the inferred representation. Experiments on different simulated datasets and established benchmarks highlight the effectiveness of our approach in recovering the ground-truth latents.
Independent Mechanism Analysis and the Manifold Hypothesis
Dec 20, 2023Independent Mechanism Analysis (IMA) seeks to address non-identifiability in nonlinear Independent Component Analysis (ICA) by assuming that the Jacobian of the mixing function has orthogonal columns. As typical in ICA, previous work focused on the case with an equal number of latent components and observed mixtures. Here, we extend IMA to settings with a larger number of mixtures that reside on a manifold embedded in a higher-dimensional than the latent space -- in line with the manifold hypothesis in representation learning. For this setting, we show that IMA still circumvents several non-identifiability issues, suggesting that it can also be a beneficial principle for higher-dimensional observations when the manifold hypothesis holds. Further, we prove that the IMA principle is approximately satisfied with high probability (increasing with the number of observed mixtures) when the directions along which the latent components influence the observations are chosen independently at random. This provides a new and rigorous statistical interpretation of IMA.
Self-Supervised Disentanglement by Leveraging Structure in Data Augmentations
Nov 15, 2023

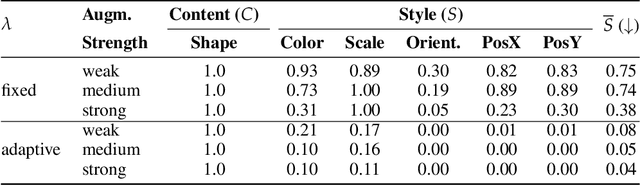

Self-supervised representation learning often uses data augmentations to induce some invariance to "style" attributes of the data. However, with downstream tasks generally unknown at training time, it is difficult to deduce a priori which attributes of the data are indeed "style" and can be safely discarded. To address this, we introduce a more principled approach that seeks to disentangle style features rather than discard them. The key idea is to add multiple style embedding spaces where: (i) each is invariant to all-but-one augmentation; and (ii) joint entropy is maximized. We formalize our structured data-augmentation procedure from a causal latent-variable-model perspective, and prove identifiability of both content and (multiple blocks of) style variables. We empirically demonstrate the benefits of our approach on synthetic datasets and then present promising but limited results on ImageNet.
Multi-View Causal Representation Learning with Partial Observability
Nov 07, 2023



We present a unified framework for studying the identifiability of representations learned from simultaneously observed views, such as different data modalities. We allow a partially observed setting in which each view constitutes a nonlinear mixture of a subset of underlying latent variables, which can be causally related. We prove that the information shared across all subsets of any number of views can be learned up to a smooth bijection using contrastive learning and a single encoder per view. We also provide graphical criteria indicating which latent variables can be identified through a simple set of rules, which we refer to as identifiability algebra. Our general framework and theoretical results unify and extend several previous works on multi-view nonlinear ICA, disentanglement, and causal representation learning. We experimentally validate our claims on numerical, image, and multi-modal data sets. Further, we demonstrate that the performance of prior methods is recovered in different special cases of our setup. Overall, we find that access to multiple partial views enables us to identify a more fine-grained representation, under the generally milder assumption of partial observability.