 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptDrift: Uncovering Biases through the Lens of Foundational Models
Oct 24, 2024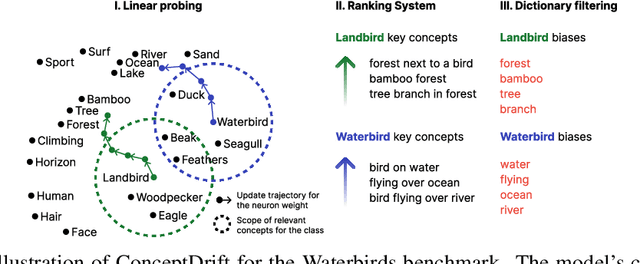


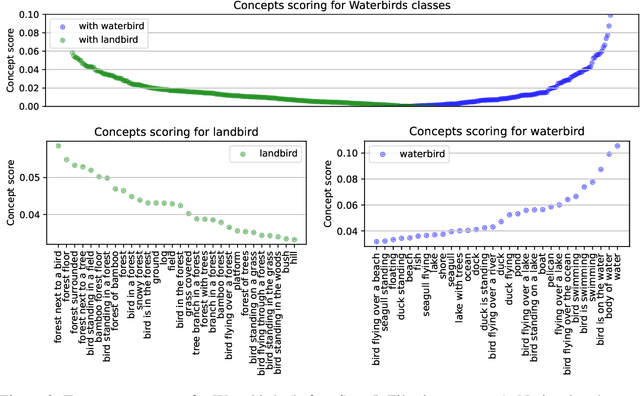
Datasets and pre-trained models come with intrinsic biases. Most methods rely on spotting them by analysing misclassified samples, in a semi-automated human-computer validation. In contrast, we propose ConceptDrift, a method which analyzes the weights of a linear probe, learned on top a foundational model. We capitalize on the weight update trajectory, which starts from the embedding of the textual representation of the class, and proceeds to drift towards embeddings that disclose hidden biases. Different from prior work, with this approach we can pin-point unwanted correlations from a dataset, providing more than just possible explanations for the wrong predictions. We empirically prove the efficacy of our method, by significantly improving zero-shot performance with biased-augmented prompting. Our method is not bounded to a single modality, and we experiment in this work with both image (Waterbirds, CelebA, Nico++) and text datasets (CivilComments).
Stylist: Style-Driven Feature Ranking for Robust Novelty Detection
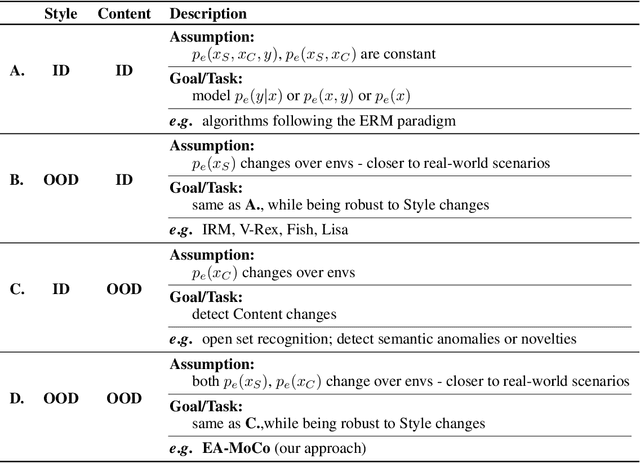
Oct 05, 2023Novelty detection aims at finding samples that differ in some form from the distribution of seen samples. But not all changes are created equal. Data can suffer a multitude of distribution shifts, and we might want to detect only some types of relevant changes. Similar to works in out-of-distribution generalization, we propose to use the formalization of separating into semantic or content changes, that are relevant to our task, and style changes, that are irrelevant. Within this formalization, we define the robust novelty detection as the task of finding semantic changes while being robust to style distributional shifts. Leveraging pretrained, large-scale model representations, we introduce Stylist, a novel method that focuses on dropping environment-biased features. First, we compute a per-feature score based on the feature distribution distances between environments. Next, we show that our selection manages to remove features responsible for spurious correlations and improve novelty detection performance. For evaluation, we adapt domain generalization datasets to our task and analyze the methods behaviors. We additionally built a large synthetic dataset where we have control over the spurious correlations degree. We prove that our selection mechanism improves novelty detection algorithms across multiple datasets, containing both stylistic and content shifts.
Environment-biased Feature Ranking for Novelty Detection Robustness
Sep 21, 2023



We tackle the problem of robust novelty detection, where we aim to detect novelties in terms of semantic content while being invariant to changes in other, irrelevant factors. Specifically, we operate in a setup with multiple environments, where we determine the set of features that are associated more with the environments, rather than to the content relevant for the task. Thus, we propose a method that starts with a pretrained embedding and a multi-env setup and manages to rank the features based on their environment-focus. First, we compute a per-feature score based on the feature distribution variance between envs. Next, we show that by dropping the highly scored ones, we manage to remove spurious correlations and improve the overall performance by up to 6%, both in covariance and sub-population shift cases, both for a real and a synthetic benchmark, that we introduce for this task.
Learning Diverse Features in Vision Transformers for Improved Generalization
Aug 30, 2023Deep learning models often rely only on a small set of features even when there is a rich set of predictive signals in the training data. This makes models brittle and sensitive to distribution shifts. In this work, we first examine vision transformers (ViTs) and find that they tend to extract robust and spurious features with distinct attention heads. As a result of this modularity, their performance under distribution shifts can be significantly improved at test time by pruning heads corresponding to spurious features, which we demonstrate using an "oracle selection" on validation data. Second, we propose a method to further enhance the diversity and complementarity of the learned features by encouraging orthogonality of the attention heads' input gradients. We observe improved out-of-distribution performance on diagnostic benchmarks (MNIST-CIFAR, Waterbirds) as a consequence of the enhanced diversity of features and the pruning of undesirable heads.
Spuriosity Didn't Kill the Classifier: Using Invariant Predictions to Harness Spurious Features
Jul 19, 2023To avoid failures on out-of-distribution data, recent works have sought to extract features that have a stable or invariant relationship with the label across domains, discarding the "spurious" or unstable features whose relationship with the label changes across domains. However, unstable features often carry complementary information about the label that could boost performance if used correctly in the test domain. Our main contribution is to show that it is possible to learn how to use these unstable features in the test domain without labels. In particular, we prove that pseudo-labels based on stable features provide sufficient guidance for doing so, provided that stable and unstable features are conditionally independent given the label. Based on this theoretical insight, we propose Stable Feature Boosting (SFB), an algorithm for: (i) learning a predictor that separates stable and conditionally-independent unstable features; and (ii) using the stable-feature predictions to adapt the unstable-feature predictions in the test domain. Theoretically, we prove that SFB can learn an asymptotically-optimal predictor without test-domain labels. Empirically, we demonstrate the effectiveness of SFB on real and synthetic data.
Env-Aware Anomaly Detection: Ignore Style Changes, Stay True to Content!
Oct 06, 2022
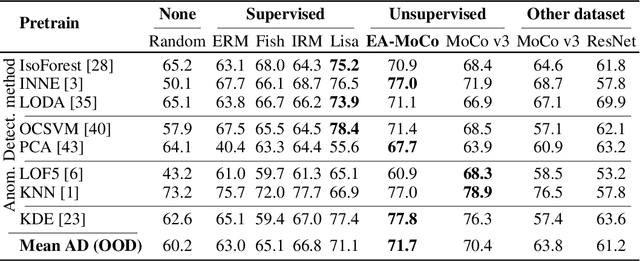
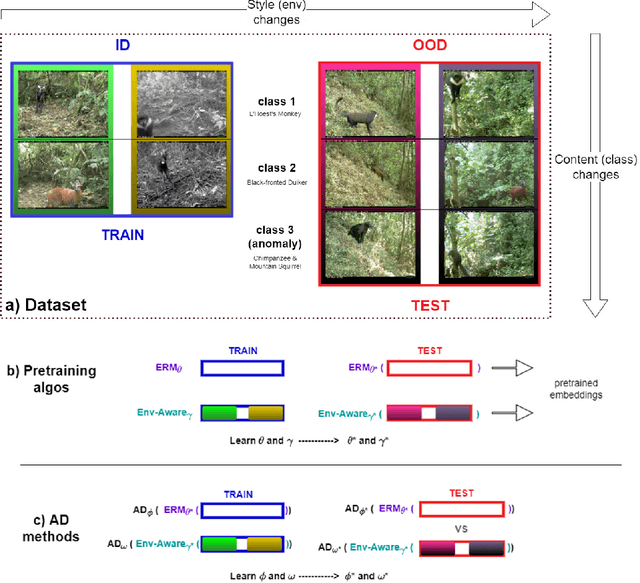
We introduce a formalization and benchmark for the unsupervised anomaly detection task in the distribution-shift scenario. Our work builds upon the iWildCam dataset, and, to the best of our knowledge, we are the first to propose such an approach for visual data. We empirically validate that environment-aware methods perform better in such cases when compared with the basic Empirical Risk Minimization (ERM). We next propose an extension for generating positive samples for contrastive methods that considers the environment labels when training, improving the ERM baseline score by 8.7%.
DCI-ES: An Extended Disentanglement Framework with Connections to Identifiability
Oct 01, 2022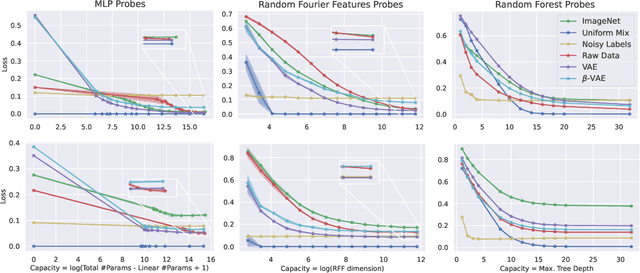
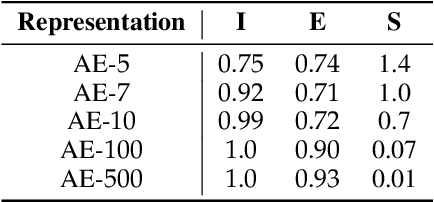
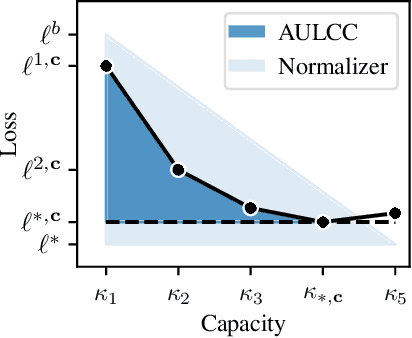
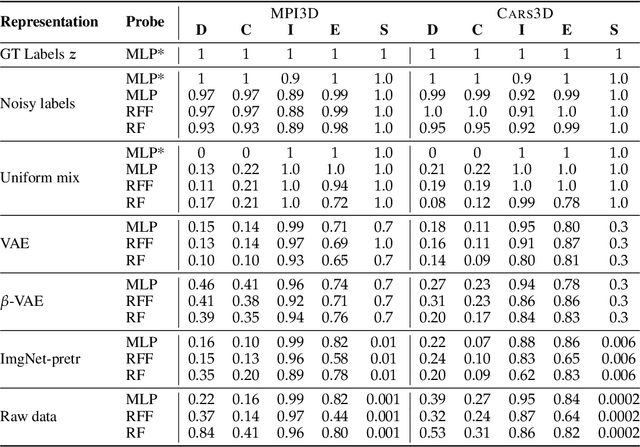
In representation learning, a common approach is to seek representations which disentangle the underlying factors of variation. Eastwood & Williams (2018) proposed three metrics for quantifying the quality of such disentangled representations: disentanglement (D), completeness (C) and informativeness (I). In this work, we first connect this DCI framework to two common notions of linear and nonlinear identifiability, thus establishing a formal link between disentanglement and the closely-related field of independent component analysis. We then propose an extended DCI-ES framework with two new measures of representation quality - explicitness (E) and size (S) - and point out how D and C can be computed for black-box predictors. Our main idea is that the functional capacity required to use a representation is an important but thus-far neglected aspect of representation quality, which we quantify using explicitness or ease-of-use (E). We illustrate the relevance of our extensions on the MPI3D and Cars3D datasets.
Mining for meaning: from vision to language through multiple networks consensus
Sep 18, 2018



Describing visual data into natural language is a very challenging task, at the intersection of computer vision, natural language processing and machine learning. Language goes well beyond the description of physical objects and their interactions and can convey the same abstract idea in many ways. It is both about content at the highest semantic level as well as about fluent form. Here we propose an approach to describe videos in natural language by reaching a consensus among multiple encoder-decoder networks. Finding such a consensual linguistic description, which shares common properties with a larger group, has a better chance to convey the correct meaning. We propose and train several network architectures and use different types of image, audio and video features. Each model produces its own description of the input video and the best one is chosen through an efficient, two-phase consensus process. We demonstrate the strength of our approach by obtaining state of the art results on the challenging MSR-VTT dataset.