 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross Modal Retrieval with Querybank Normalisation
Dec 23, 2021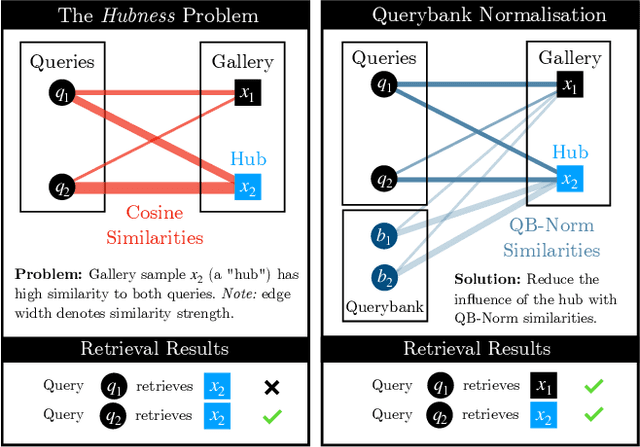



Profiting from large-scale training datasets, advances in neural architecture design and efficient inference, joint embeddings have become the dominant approach for tackling cross-modal retrieval. In this work we first show that, despite their effectiveness, state-of-the-art joint embeddings suffer significantly from the longstanding hubness problem in which a small number of gallery embeddings form the nearest neighbours of many queries. Drawing inspiration from the NLP literature, we formulate a simple but effective framework called Querybank Normalisation (QB-Norm) that re-normalises query similarities to account for hubs in the embedding space. QB-Norm improves retrieval performance without requiring retraining. Differently from prior work, we show that QB-Norm works effectively without concurrent access to any test set queries. Within the QB-Norm framework, we also propose a novel similarity normalisation method, the Dynamic Inverted Softmax, that is significantly more robust than existing approaches. We showcase QB-Norm across a range of cross modal retrieval models and benchmarks where it consistently enhances strong baselines beyond the state of the art. Code is available at https://vladbogo.github.io/QB-Norm/.
TEACHTEXT: CrossModal Generalized Distillation for Text-Video Retrieval
Apr 16, 2021

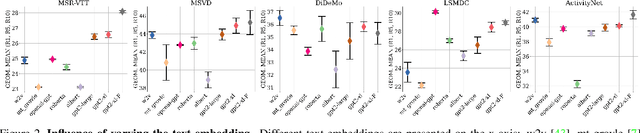

In recent years, considerable progress on the task of text-video retrieval has been achieved by leveraging large-scale pretraining on visual and audio datasets to construct powerful video encoders. By contrast, despite the natural symmetry, the design of effective algorithms for exploiting large-scale language pretraining remains under-explored. In this work, we are the first to investigate the design of such algorithms and propose a novel generalized distillation method, TeachText, which leverages complementary cues from multiple text encoders to provide an enhanced supervisory signal to the retrieval model. Moreover, we extend our method to video side modalities and show that we can effectively reduce the number of used modalities at test time without compromising performance. Our approach advances the state of the art on several video retrieval benchmarks by a significant margin and adds no computational overhead at test time. Last but not least, we show an effective application of our method for eliminating noise from retrieval datasets. Code and data can be found at https://www.robots.ox.ac.uk/~vgg/research/teachtext/.
Mining for meaning: from vision to language through multiple networks consensus
Sep 18, 2018



Describing visual data into natural language is a very challenging task, at the intersection of computer vision, natural language processing and machine learning. Language goes well beyond the description of physical objects and their interactions and can convey the same abstract idea in many ways. It is both about content at the highest semantic level as well as about fluent form. Here we propose an approach to describe videos in natural language by reaching a consensus among multiple encoder-decoder networks. Finding such a consensual linguistic description, which shares common properties with a larger group, has a better chance to convey the correct meaning. We propose and train several network architectures and use different types of image, audio and video features. Each model produces its own description of the input video and the best one is chosen through an efficient, two-phase consensus process. We demonstrate the strength of our approach by obtaining state of the art results on the challenging MSR-VTT dataset.
Unsupervised learning of foreground object detection
Aug 14, 2018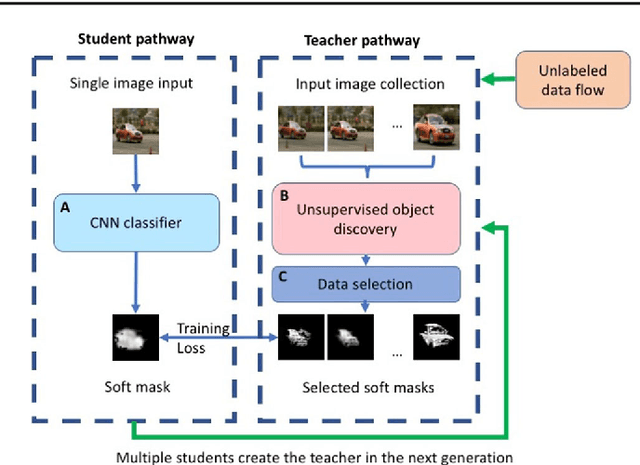



Unsupervised learning poses one of the most difficult challenges in computer vision today. The task has an immense practical value with many applications in artificial intelligence and emerging technologies, as large quantities of unlabeled videos can be collected at relatively low cost. In this paper, we address the unsupervised learning problem in the context of detecting the main foreground objects in single images. We train a student deep network to predict the output of a teacher pathway that performs unsupervised object discovery in videos or large image collections. Our approach is different from published methods on unsupervised object discovery. We move the unsupervised learning phase during training time, then at test time we apply the standard feed-forward processing along the student pathway. This strategy has the benefit of allowing increased generalization possibilities during training, while remaining fast at testing. Our unsupervised learning algorithm can run over several generations of student-teacher training. Thus, a group of student networks trained in the first generation collectively create the teacher at the next generation. In experiments our method achieves top results on three current datasets for object discovery in video, unsupervised image segmentation and saliency detection. At test time the proposed system is fast, being one to two orders of magnitude faster than published unsupervised methods.
Unsupervised learning from video to detect foreground objects in single images
Mar 31, 2017


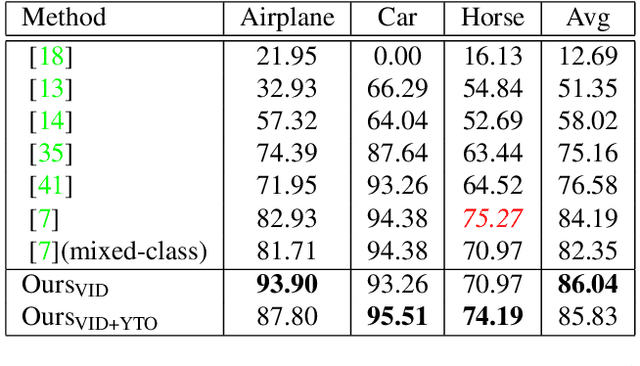
Unsupervised learning from visual data is one of the most difficult challenges in computer vision, being a fundamental task for understanding how visual recognition works. From a practical point of view, learning from unsupervised visual input has an immense practical value, as very large quantities of unlabeled videos can be collected at low cost. In this paper, we address the task of unsupervised learning to detect and segment foreground objects in single images. We achieve our goal by training a student pathway, consisting of a deep neural network. It learns to predict from a single input image (a video frame) the output for that particular frame, of a teacher pathway that performs unsupervised object discovery in video. Our approach is different from the published literature that performs unsupervised discovery in videos or in collections of images at test time. We move the unsupervised discovery phase during the training stage, while at test time we apply the standard feed-forward processing along the student pathway. This has a dual benefit: firstly, it allows in principle unlimited possibilities of learning and generalization during training, while remaining very fast at testing. Secondly, the student not only becomes able to detect in single images significantly better than its unsupervised video discovery teacher, but it also achieves state of the art results on two important current benchmarks, YouTube Objects and Object Discovery datasets. Moreover, at test time, our system is at least two orders of magnitude faster than other previous methods.