 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptDrift: Uncovering Biases through the Lens of Foundational Models
Paper and Code
Oct 24, 2024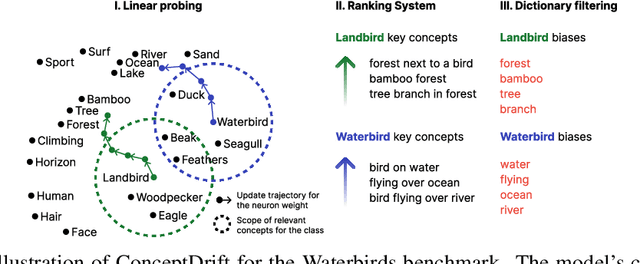


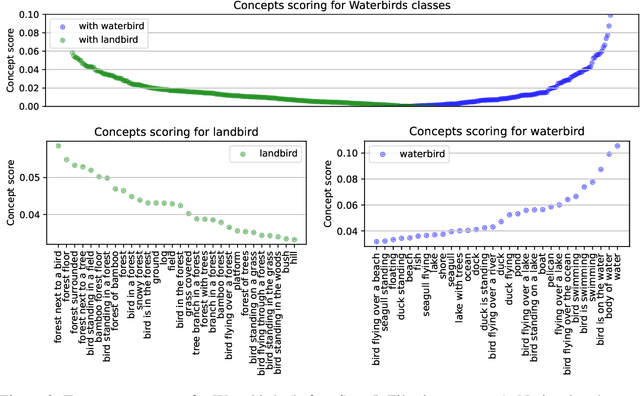
Datasets and pre-trained models come with intrinsic biases. Most methods rely on spotting them by analysing misclassified samples, in a semi-automated human-computer validation. In contrast, we propose ConceptDrift, a method which analyzes the weights of a linear probe, learned on top a foundational model. We capitalize on the weight update trajectory, which starts from the embedding of the textual representation of the class, and proceeds to drift towards embeddings that disclose hidden biases. Different from prior work, with this approach we can pin-point unwanted correlations from a dataset, providing more than just possible explanations for the wrong predictions. We empirically prove the efficacy of our method, by significantly improving zero-shot performance with biased-augmented prompting. Our method is not bounded to a single modality, and we experiment in this work with both image (Waterbirds, CelebA, Nico++) and text datasets (CivilComments).