 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Interpretable Representation Alignment with Ordinal Similarity
Jun 16, 2026Evaluating representation similarity is fundamental to representation learning. However, existing metrics suffer from significant limitations: they lack interpretability due to shifting baselines, lack robustness to outliers, and are computationally intractable for large datasets, forcing reliance on heuristic approximations. To address this, we develop an ordinal-similarity framework, instantiated by the Triplet (TSI) and Quadruplet (QSI) Similarity Indices, which measure alignment by quantifying the consistency of ordinal relationships. We theoretically demonstrate this formulation is inherently interpretable, robust to outliers, and computationally efficient. Finally, we establish a formal equivalence between TSI and local neighborhood alignment, measured by Mutual Nearest Neighbors. Empirically, we validate these properties and show that ordinal similarity offers a scalable approach to measuring alignment, enabling practitioners to better understand and design representations.
Flow-Based Density Ratio Estimation for Intractable Distributions with Applications in Genomics
Feb 27, 2026Estimating density ratios between pairs of intractable data distributions is a core problem in probabilistic modeling, enabling principled comparisons of sample likelihoods under different data-generating processes across conditions and covariates. While exact-likelihood models such as normalizing flows offer a promising approach to density ratio estimation, naive flow-based evaluations are computationally expensive, as they require simulating costly likelihood integrals for each distribution separately. In this work, we leverage condition-aware flow matching to derive a single dynamical formulation for tracking density ratios along generative trajectories. We demonstrate competitive performance on simulated benchmarks for closed-form ratio estimation, and show that our method supports versatile tasks in single-cell genomics data analysis, where likelihood-based comparisons of cellular states across experimental conditions enable treatment effect estimation and batch correction evaluation.
Compositional Generalization Requires Linear, Orthogonal Representations in Vision Embedding Models
Feb 27, 2026Compositional generalization, the ability to recognize familiar parts in novel contexts, is a defining property of intelligent systems. Although modern models are trained on massive datasets, they still cover only a tiny fraction of the combinatorial space of possible inputs, raising the question of what structure representations must have to support generalization to unseen combinations. We formalize three desiderata for compositional generalization under standard training (divisibility, transferability, stability) and show they impose necessary geometric constraints: representations must decompose linearly into per-concept components, and these components must be orthogonal across concepts. This provides theoretical grounding for the Linear Representation Hypothesis: the linear structure widely observed in neural representations is a necessary consequence of compositional generalization. We further derive dimension bounds linking the number of composable concepts to the embedding geometry. Empirically, we evaluate these predictions across modern vision models (CLIP, SigLIP, DINO) and find that representations exhibit partial linear factorization with low-rank, near-orthogonal per-concept factors, and that the degree of this structure correlates with compositional generalization on unseen combinations. As models continue to scale, these conditions predict the representational geometry they may converge to. Code is available at https://github.com/oshapio/necessary-compositionality.
From Words to Amino Acids: Does the Curse of Depth Persist?
Feb 25, 2026Protein language models (PLMs) have become widely adopted as general-purpose models, demonstrating strong performance in protein engineering and de novo design. Like large language models (LLMs), they are typically trained as deep transformers with next-token or masked-token prediction objectives on massive sequence corpora and are scaled by increasing model depth. Recent work on autoregressive LLMs has identified the Curse of Depth: later layers contribute little to the final output predictions. These findings naturally raise the question of whether a similar depth inefficiency also appears in PLMs, where many widely used models are not autoregressive, and some are multimodal, accepting both protein sequence and structure as input. In this work, we present a depth analysis of six popular PLMs across model families and scales, spanning three training objectives, namely autoregressive, masked, and diffusion, and quantify how layer contributions evolve with depth using a unified set of probing- and perturbation-based measurements. Across all models, we observe consistent depth-dependent patterns that extend prior findings on LLMs: later layers depend less on earlier computations and mainly refine the final output distribution, and these effects are increasingly pronounced in deeper models. Taken together, our results suggest that PLMs exhibit a form of depth inefficiency, motivating future work on more depth-efficient architectures and training methods.
Are Object-Centric Representations Better At Compositional Generalization?
Feb 18, 2026Compositional generalization, the ability to reason about novel combinations of familiar concepts, is fundamental to human cognition and a critical challenge for machine learning. Object-centric (OC) representations, which encode a scene as a set of objects, are often argued to support such generalization, but systematic evidence in visually rich settings is limited. We introduce a Visual Question Answering benchmark across three controlled visual worlds (CLEVRTex, Super-CLEVR, and MOVi-C) to measure how well vision encoders, with and without object-centric biases, generalize to unseen combinations of object properties. To ensure a fair and comprehensive comparison, we carefully account for training data diversity, sample size, representation size, downstream model capacity, and compute. We use DINOv2 and SigLIP2, two widely used vision encoders, as the foundation models and their OC counterparts. Our key findings reveal that (1) OC approaches are superior in harder compositional generalization settings; (2) original dense representations surpass OC only on easier settings and typically require substantially more downstream compute; and (3) OC models are more sample efficient, achieving stronger generalization with fewer images, whereas dense encoders catch up or surpass them only with sufficient data and diversity. Overall, object-centric representations offer stronger compositional generalization when any one of dataset size, training data diversity, or downstream compute is constrained.
Logit Distance Bounds Representational Similarity
Feb 17, 2026For a broad family of discriminative models that includes autoregressive language models, identifiability results imply that if two models induce the same conditional distributions, then their internal representations agree up to an invertible linear transformation. We ask whether an analogous conclusion holds approximately when the distributions are close instead of equal. Building on the observation of Nielsen et al. (2025) that closeness in KL divergence need not imply high linear representational similarity, we study a distributional distance based on logit differences and show that closeness in this distance does yield linear similarity guarantees. Specifically, we define a representational dissimilarity measure based on the models' identifiability class and prove that it is bounded by the logit distance. We further show that, when model probabilities are bounded away from zero, KL divergence upper-bounds logit distance; yet the resulting bound fails to provide nontrivial control in practice. As a consequence, KL-based distillation can match a teacher's predictions while failing to preserve linear representational properties, such as linear-probe recoverability of human-interpretable concepts. In distillation experiments on synthetic and image datasets, logit-distance distillation yields students with higher linear representational similarity and better preservation of the teacher's linearly recoverable concepts.
Does Data Scaling Lead to Visual Compositional Generalization?
Jul 09, 2025Compositional understanding is crucial for human intelligence, yet it remains unclear whether contemporary vision models exhibit it. The dominant machine learning paradigm is built on the premise that scaling data and model sizes will improve out-of-distribution performance, including compositional generalization. We test this premise through controlled experiments that systematically vary data scale, concept diversity, and combination coverage. We find that compositional generalization is driven by data diversity, not mere data scale. Increased combinatorial coverage forces models to discover a linearly factored representational structure, where concepts decompose into additive components. We prove this structure is key to efficiency, enabling perfect generalization from few observed combinations. Evaluating pretrained models (DINO, CLIP), we find above-random yet imperfect performance, suggesting partial presence of this structure. Our work motivates stronger emphasis on constructing diverse datasets for compositional generalization, and considering the importance of representational structure that enables efficient compositional learning. Code available at https://github.com/oshapio/visual-compositional-generalization.
When Does Closeness in Distribution Imply Representational Similarity? An Identifiability Perspective
Jun 04, 2025When and why representations learned by different deep neural networks are similar is an active research topic. We choose to address these questions from the perspective of identifiability theory, which suggests that a measure of representational similarity should be invariant to transformations that leave the model distribution unchanged. Focusing on a model family which includes several popular pre-training approaches, e.g., autoregressive language models, we explore when models which generate distributions that are close have similar representations. We prove that a small Kullback-Leibler divergence between the model distributions does not guarantee that the corresponding representations are similar. This has the important corollary that models arbitrarily close to maximizing the likelihood can still learn dissimilar representations, a phenomenon mirrored in our empirical observations on models trained on CIFAR-10. We then define a distributional distance for which closeness implies representational similarity, and in synthetic experiments, we find that wider networks learn distributions which are closer with respect to our distance and have more similar representations. Our results establish a link between closeness in distribution and representational similarity.
Minimum-Excess-Work Guidance
May 19, 2025We propose a regularization framework inspired by thermodynamic work for guiding pre-trained probability flow generative models (e.g., continuous normalizing flows or diffusion models) by minimizing excess work, a concept rooted in statistical mechanics and with strong conceptual connections to optimal transport. Our approach enables efficient guidance in sparse-data regimes common to scientific applications, where only limited target samples or partial density constraints are available. We introduce two strategies: Path Guidance for sampling rare transition states by concentrating probability mass on user-defined subsets, and Observable Guidance for aligning generated distributions with experimental observables while preserving entropy. We demonstrate the framework's versatility on a coarse-grained protein model, guiding it to sample transition configurations between folded/unfolded states and correct systematic biases using experimental data. The method bridges thermodynamic principles with modern generative architectures, offering a principled, efficient, and physics-inspired alternative to standard fine-tuning in data-scarce domains. Empirical results highlight improved sample efficiency and bias reduction, underscoring its applicability to molecular simulations and beyond.
Exploring the Effectiveness of Object-Centric Representations in Visual Question Answering: Comparative Insights with Foundation Models
Jul 22, 2024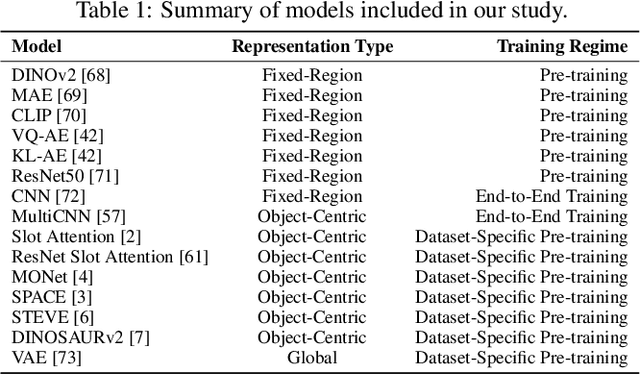
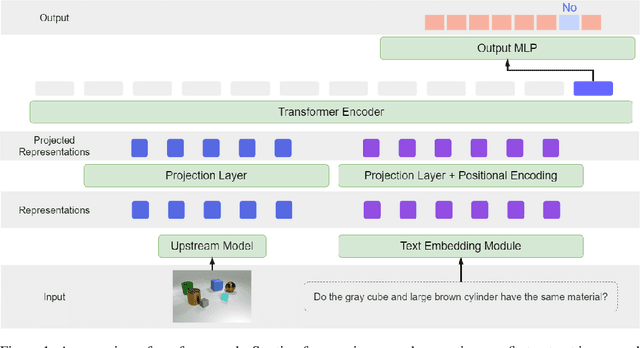
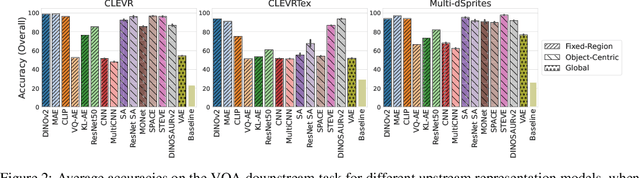
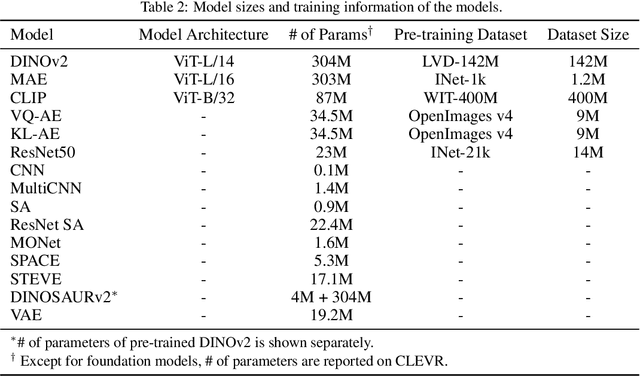
Object-centric (OC) representations, which represent the state of a visual scene by modeling it as a composition of objects, have the potential to be used in various downstream tasks to achieve systematic compositional generalization and facilitate reasoning. However, these claims have not been thoroughly analyzed yet. Recently, foundation models have demonstrated unparalleled capabilities across diverse domains from language to computer vision, marking them as a potential cornerstone of future research for a multitude of computational tasks. In this paper, we conduct an extensive empirical study on representation learning for downstream Visual Question Answering (VQA), which requires an accurate compositional understanding of the scene. We thoroughly investigate the benefits and trade-offs of OC models and alternative approaches including large pre-trained foundation models on both synthetic and real-world data, and demonstrate a viable way to achieve the best of both worlds. The extensiveness of our study, encompassing over 800 downstream VQA models and 15 different types of upstream representations, also provides several additional insights that we believe will be of interest to the community at large.