 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Closeness in Distribution Imply Representational Similarity? An Identifiability Perspective
Jun 04, 2025When and why representations learned by different deep neural networks are similar is an active research topic. We choose to address these questions from the perspective of identifiability theory, which suggests that a measure of representational similarity should be invariant to transformations that leave the model distribution unchanged. Focusing on a model family which includes several popular pre-training approaches, e.g., autoregressive language models, we explore when models which generate distributions that are close have similar representations. We prove that a small Kullback-Leibler divergence between the model distributions does not guarantee that the corresponding representations are similar. This has the important corollary that models arbitrarily close to maximizing the likelihood can still learn dissimilar representations, a phenomenon mirrored in our empirical observations on models trained on CIFAR-10. We then define a distributional distance for which closeness implies representational similarity, and in synthetic experiments, we find that wider networks learn distributions which are closer with respect to our distance and have more similar representations. Our results establish a link between closeness in distribution and representational similarity.
Hubness Reduction Improves Sentence-BERT Semantic Spaces
Nov 30, 2023

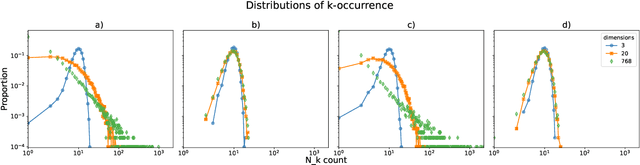

Semantic representations of text, i.e. representations of natural language which capture meaning by geometry, are essential for areas such as information retrieval and document grouping. High-dimensional trained dense vectors have received much attention in recent years as such representations. We investigate the structure of semantic spaces that arise from embeddings made with Sentence-BERT and find that the representations suffer from a well-known problem in high dimensions called hubness. Hubness results in asymmetric neighborhood relations, such that some texts (the hubs) are neighbours of many other texts while most texts (so-called anti-hubs), are neighbours of few or no other texts. We quantify the semantic quality of the embeddings using hubness scores and error rate of a neighbourhood based classifier. We find that when hubness is high, we can reduce error rate and hubness using hubness reduction methods. We identify a combination of two methods as resulting in the best reduction. For example, on one of the tested pretrained models, this combined method can reduce hubness by about 75% and error rate by about 9%. Thus, we argue that mitigating hubness in the embedding space provides better semantic representations of text.
DiffEnc: Variational Diffusion with a Learned Encoder
Oct 30, 2023Diffusion models may be viewed as hierarchical variational autoencoders (VAEs) with two improvements: parameter sharing for the conditional distributions in the generative process and efficient computation of the loss as independent terms over the hierarchy. We consider two changes to the diffusion model that retain these advantages while adding flexibility to the model. Firstly, we introduce a data- and depth-dependent mean function in the diffusion process, which leads to a modified diffusion loss. Our proposed framework, DiffEnc, achieves state-of-the-art likelihood on CIFAR-10. Secondly, we let the ratio of the noise variance of the reverse encoder process and the generative process be a free weight parameter rather than being fixed to 1. This leads to theoretical insights: For a finite depth hierarchy, the evidence lower bound (ELBO) can be used as an objective for a weighted diffusion loss approach and for optimizing the noise schedule specifically for inference. For the infinite-depth hierarchy, on the other hand, the weight parameter has to be 1 to have a well-defined ELBO.