 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Linear Properties in Language Models: An Empirical Investigation
May 21, 2026Linear properties are ubiquitous in the representations of language models; however, testing them experimentally remains a challenging task. This work focuses on relational linearity: the hypothesis that, for a fixed relation (e.g., "plays"), the unembedding of an object (e.g., "trumpet") can be predicted from the embedding of its subject (e.g.,"Miles Davis") by a linear map. We present an experimental method to test the formulation of relational linearity by Marconato et al. (2025). Specifically, we introduce a probing method, based on Kullback-Leibler divergence, to evaluate this property and examine its variation across layers and paraphrased relational queries. It is also more efficient than previous work; for example, it avoids the crude Jacobian approximations used in Linear Relational Embeddings by Hernandez et al. (2024). Our findings across four datasets show that relational linearity varies across models, exhibits layer-wise patterns consistent with prior observations about linguistic information in model representations, and is differently affected by changes in how the relation is phrased.
Logit Distance Bounds Representational Similarity
Feb 17, 2026For a broad family of discriminative models that includes autoregressive language models, identifiability results imply that if two models induce the same conditional distributions, then their internal representations agree up to an invertible linear transformation. We ask whether an analogous conclusion holds approximately when the distributions are close instead of equal. Building on the observation of Nielsen et al. (2025) that closeness in KL divergence need not imply high linear representational similarity, we study a distributional distance based on logit differences and show that closeness in this distance does yield linear similarity guarantees. Specifically, we define a representational dissimilarity measure based on the models' identifiability class and prove that it is bounded by the logit distance. We further show that, when model probabilities are bounded away from zero, KL divergence upper-bounds logit distance; yet the resulting bound fails to provide nontrivial control in practice. As a consequence, KL-based distillation can match a teacher's predictions while failing to preserve linear representational properties, such as linear-probe recoverability of human-interpretable concepts. In distillation experiments on synthetic and image datasets, logit-distance distillation yields students with higher linear representational similarity and better preservation of the teacher's linearly recoverable concepts.
When Does Closeness in Distribution Imply Representational Similarity? An Identifiability Perspective
Jun 04, 2025When and why representations learned by different deep neural networks are similar is an active research topic. We choose to address these questions from the perspective of identifiability theory, which suggests that a measure of representational similarity should be invariant to transformations that leave the model distribution unchanged. Focusing on a model family which includes several popular pre-training approaches, e.g., autoregressive language models, we explore when models which generate distributions that are close have similar representations. We prove that a small Kullback-Leibler divergence between the model distributions does not guarantee that the corresponding representations are similar. This has the important corollary that models arbitrarily close to maximizing the likelihood can still learn dissimilar representations, a phenomenon mirrored in our empirical observations on models trained on CIFAR-10. We then define a distributional distance for which closeness implies representational similarity, and in synthetic experiments, we find that wider networks learn distributions which are closer with respect to our distance and have more similar representations. Our results establish a link between closeness in distribution and representational similarity.
What is causal about causal models and representations?
Jan 31, 2025Causal Bayesian networks are 'causal' models since they make predictions about interventional distributions. To connect such causal model predictions to real-world outcomes, we must determine which actions in the world correspond to which interventions in the model. For example, to interpret an action as an intervention on a treatment variable, the action will presumably have to a) change the distribution of treatment in a way that corresponds to the intervention, and b) not change other aspects, such as how the outcome depends on the treatment; while the marginal distributions of some variables may change as an effect. We introduce a formal framework to make such requirements for different interpretations of actions as interventions precise. We prove that the seemingly natural interpretation of actions as interventions is circular: Under this interpretation, every causal Bayesian network that correctly models the observational distribution is trivially also interventionally valid, and no action yields empirical data that could possibly falsify such a model. We prove an impossibility result: No interpretation exists that is non-circular and simultaneously satisfies a set of natural desiderata. Instead, we examine non-circular interpretations that may violate some desiderata and show how this may in turn enable the falsification of causal models. By rigorously examining how a causal Bayesian network could be a 'causal' model of the world instead of merely a mathematical object, our formal framework contributes to the conceptual foundations of causal representation learning, causal discovery, and causal abstraction, while also highlighting some limitations of existing approaches.
All or None: Identifiable Linear Properties of Next-token Predictors in Language Modeling
Oct 30, 2024


We analyze identifiability as a possible explanation for the ubiquity of linear properties across language models, such as the vector difference between the representations of "easy" and "easiest" being parallel to that between "lucky" and "luckiest". For this, we ask whether finding a linear property in one model implies that any model that induces the same distribution has that property, too. To answer that, we first prove an identifiability result to characterize distribution-equivalent next-token predictors, lifting a diversity requirement of previous results. Second, based on a refinement of relational linearity [Paccanaro and Hinton, 2001; Hernandez et al., 2024], we show how many notions of linearity are amenable to our analysis. Finally, we show that under suitable conditions, these linear properties either hold in all or none distribution-equivalent next-token predictors.
Independent Mechanism Analysis and the Manifold Hypothesis
Dec 20, 2023Independent Mechanism Analysis (IMA) seeks to address non-identifiability in nonlinear Independent Component Analysis (ICA) by assuming that the Jacobian of the mixing function has orthogonal columns. As typical in ICA, previous work focused on the case with an equal number of latent components and observed mixtures. Here, we extend IMA to settings with a larger number of mixtures that reside on a manifold embedded in a higher-dimensional than the latent space -- in line with the manifold hypothesis in representation learning. For this setting, we show that IMA still circumvents several non-identifiability issues, suggesting that it can also be a beneficial principle for higher-dimensional observations when the manifold hypothesis holds. Further, we prove that the IMA principle is approximately satisfied with high probability (increasing with the number of observed mixtures) when the directions along which the latent components influence the observations are chosen independently at random. This provides a new and rigorous statistical interpretation of IMA.
CLadder: A Benchmark to Assess Causal Reasoning Capabilities of Language Models
Dec 07, 2023The ability to perform causal reasoning is widely considered a core feature of intelligence. In this work, we investigate whether large language models (LLMs) can coherently reason about causality. Much of the existing work in natural language processing (NLP) focuses on evaluating commonsense causal reasoning in LLMs, thus failing to assess whether a model can perform causal inference in accordance with a set of well-defined formal rules. To address this, we propose a new NLP task, causal inference in natural language, inspired by the "causal inference engine" postulated by Judea Pearl et al. We compose a large dataset, CLadder, with 10K samples: based on a collection of causal graphs and queries (associational, interventional, and counterfactual), we obtain symbolic questions and ground-truth answers, through an oracle causal inference engine. These are then translated into natural language. We evaluate multiple LLMs on our dataset, and we introduce and evaluate a bespoke chain-of-thought prompting strategy, CausalCoT. We show that our task is highly challenging for LLMs, and we conduct an in-depth analysis to gain deeper insight into the causal reasoning abilities of LLMs. Our data is open-sourced at https://huggingface.co/datasets/causalNLP/cladder, and our code can be found at https://github.com/causalNLP/cladder.
Nonparametric Identifiability of Causal Representations from Unknown Interventions
Jun 01, 2023We study causal representation learning, the task of inferring latent causal variables and their causal relations from high-dimensional functions ("mixtures") of the variables. Prior work relies on weak supervision, in the form of counterfactual pre- and post-intervention views or temporal structure; places restrictive assumptions, such as linearity, on the mixing function or latent causal model; or requires partial knowledge of the generative process, such as the causal graph or the intervention targets. We instead consider the general setting in which both the causal model and the mixing function are nonparametric. The learning signal takes the form of multiple datasets, or environments, arising from unknown interventions in the underlying causal model. Our goal is to identify both the ground truth latents and their causal graph up to a set of ambiguities which we show to be irresolvable from interventional data. We study the fundamental setting of two causal variables and prove that the observational distribution and one perfect intervention per node suffice for identifiability, subject to a genericity condition. This condition rules out spurious solutions that involve fine-tuning of the intervened and observational distributions, mirroring similar conditions for nonlinear cause-effect inference. For an arbitrary number of variables, we show that two distinct paired perfect interventions per node guarantee identifiability. Further, we demonstrate that the strengths of causal influences among the latent variables are preserved by all equivalent solutions, rendering the inferred representation appropriate for drawing causal conclusions from new data. Our study provides the first identifiability results for the general nonparametric setting with unknown interventions, and elucidates what is possible and impossible for causal representation learning without more direct supervision.
Causal Component Analysis
May 26, 2023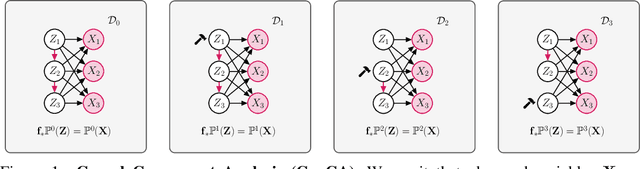

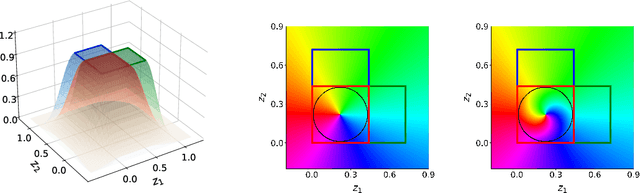

Independent Component Analysis (ICA) aims to recover independent latent variables from observed mixtures thereof. Causal Representation Learning (CRL) aims instead to infer causally related (thus often statistically dependent) latent variables, together with the unknown graph encoding their causal relationships. We introduce an intermediate problem termed Causal Component Analysis (CauCA). CauCA can be viewed as a generalization of ICA, modelling the causal dependence among the latent components, and as a special case of CRL. In contrast to CRL, it presupposes knowledge of the causal graph, focusing solely on learning the unmixing function and the causal mechanisms. Any impossibility results regarding the recovery of the ground truth in CauCA also apply for CRL, while possibility results may serve as a stepping stone for extensions to CRL. We characterize CauCA identifiability from multiple datasets generated through different types of interventions on the latent causal variables. As a corollary, this interventional perspective also leads to new identifiability results for nonlinear ICA -- a special case of CauCA with an empty graph -- requiring strictly fewer datasets than previous results. We introduce a likelihood-based approach using normalizing flows to estimate both the unmixing function and the causal mechanisms, and demonstrate its effectiveness through extensive synthetic experiments in the CauCA and ICA setting.
Evaluating vaccine allocation strategies using simulation-assisted causal modelling
Dec 14, 2022Early on during a pandemic, vaccine availability is limited, requiring prioritisation of different population groups. Evaluating vaccine allocation is therefore a crucial element of pandemics response. In the present work, we develop a model to retrospectively evaluate age-dependent counterfactual vaccine allocation strategies against the COVID-19 pandemic. To estimate the effect of allocation on the expected severe-case incidence, we employ a simulation-assisted causal modelling approach which combines a compartmental infection-dynamics simulation, a coarse-grained, data-driven causal model and literature estimates for immunity waning. We compare Israel's implemented vaccine allocation strategy in 2021 to counterfactual strategies such as no prioritisation, prioritisation of younger age groups or a strict risk-ranked approach; we find that Israel's implemented strategy was indeed highly effective. We also study the marginal impact of increasing vaccine uptake for a given age group and find that increasing vaccinations in the elderly is most effective at preventing severe cases, whereas additional vaccinations for middle-aged groups reduce infections most effectively. Due to its modular structure, our model can easily be adapted to study future pandemics. We demonstrate this flexibility by investigating vaccine allocation strategies for a pandemic with characteristics of the Spanish Flu. Our approach thus helps evaluate vaccination strategies under the complex interplay of core epidemic factors, including age-dependent risk profiles, immunity waning, vaccine availability and spreading rates.