 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality can systematically address the monsters under the bench(marks)
Feb 07, 2025Effective and reliable evaluation is essential for advancing empirical machine learning. However, the increasing accessibility of generalist models and the progress towards ever more complex, high-level tasks make systematic evaluation more challenging. Benchmarks are plagued by various biases, artifacts, or leakage, while models may behave unreliably due to poorly explored failure modes. Haphazard treatments and inconsistent formulations of such "monsters" can contribute to a duplication of efforts, a lack of trust in results, and unsupported inferences. In this position paper, we argue causality offers an ideal framework to systematically address these challenges. By making causal assumptions in an approach explicit, we can faithfully model phenomena, formulate testable hypotheses with explanatory power, and leverage principled tools for analysis. To make causal model design more accessible, we identify several useful Common Abstract Topologies (CATs) in causal graphs which help gain insight into the reasoning abilities in large language models. Through a series of case studies, we demonstrate how the precise yet pragmatic language of causality clarifies the strengths and limitations of a method and inspires new approaches for systematic progress.
A diverse Multilingual News Headlines Dataset from around the World
Mar 28, 2024



Babel Briefings is a novel dataset featuring 4.7 million news headlines from August 2020 to November 2021, across 30 languages and 54 locations worldwide with English translations of all articles included. Designed for natural language processing and media studies, it serves as a high-quality dataset for training or evaluating language models as well as offering a simple, accessible collection of articles, for example, to analyze global news coverage and cultural narratives. As a simple demonstration of the analyses facilitated by this dataset, we use a basic procedure using a TF-IDF weighted similarity metric to group articles into clusters about the same event. We then visualize the \emph{event signatures} of the event showing articles of which languages appear over time, revealing intuitive features based on the proximity of the event and unexpectedness of the event. The dataset is available on \href{https://www.kaggle.com/datasets/felixludos/babel-briefings}{Kaggle} and \href{https://huggingface.co/datasets/felixludos/babel-briefings}{HuggingFace} with accompanying \href{https://github.com/felixludos/babel-briefings}{GitHub} code.
CLadder: A Benchmark to Assess Causal Reasoning Capabilities of Language Models
Dec 07, 2023The ability to perform causal reasoning is widely considered a core feature of intelligence. In this work, we investigate whether large language models (LLMs) can coherently reason about causality. Much of the existing work in natural language processing (NLP) focuses on evaluating commonsense causal reasoning in LLMs, thus failing to assess whether a model can perform causal inference in accordance with a set of well-defined formal rules. To address this, we propose a new NLP task, causal inference in natural language, inspired by the "causal inference engine" postulated by Judea Pearl et al. We compose a large dataset, CLadder, with 10K samples: based on a collection of causal graphs and queries (associational, interventional, and counterfactual), we obtain symbolic questions and ground-truth answers, through an oracle causal inference engine. These are then translated into natural language. We evaluate multiple LLMs on our dataset, and we introduce and evaluate a bespoke chain-of-thought prompting strategy, CausalCoT. We show that our task is highly challenging for LLMs, and we conduct an in-depth analysis to gain deeper insight into the causal reasoning abilities of LLMs. Our data is open-sourced at https://huggingface.co/datasets/causalNLP/cladder, and our code can be found at https://github.com/causalNLP/cladder.
Interventional Assays for the Latent Space of Autoencoders
Jun 30, 2021

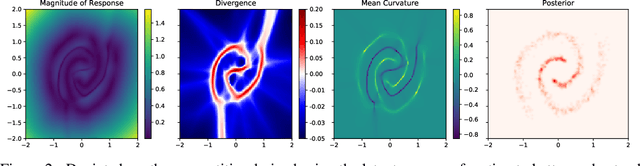

The encoders and decoders of autoencoders effectively project the input onto learned manifolds in the latent space and data space respectively. We propose a framework, called latent responses, for probing the learned data manifold using interventions in the latent space. Using this framework, we investigate "holes" in the representation to quantitatively ascertain to what extent the latent space of a trained VAE is consistent with the chosen prior. Furthermore, we use the identified structure to improve interpolation between latent vectors. We evaluate how our analyses improve the quality of the generated samples using the VAE on a variety of benchmark datasets.
Structural Autoencoders Improve Representations for Generation and Transfer
Jun 14, 2020

We study the problem of structuring a learned representation to significantly improve performance without supervision. Unlike most methods which focus on using side information like weak supervision or defining new regularization objectives, we focus on improving the learned representation by structuring the architecture of the model. We propose a self-attention based architecture to make the encoder explicitly associate parts of the representation with parts of the input observation. Meanwhile, our structural decoder architecture encourages a hierarchical structure in the latent space, akin to structural causal models, and learns a natural ordering of the latent mechanisms. We demonstrate how these models learn a representation which improves results in a variety of downstream tasks including generation, disentanglement, and transfer using several challenging and natural image datasets.
Motion-Nets: 6D Tracking of Unknown Objects in Unseen Environments using RGB
Oct 30, 2019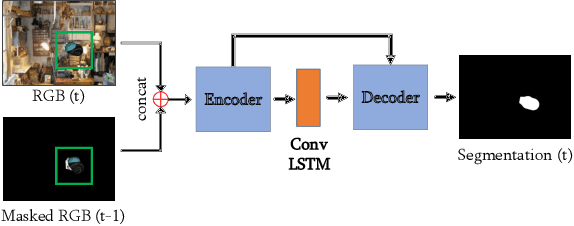
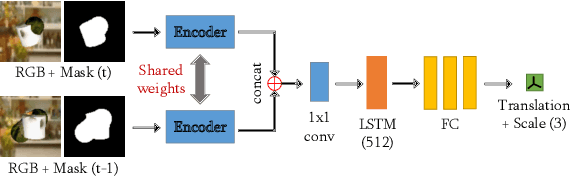
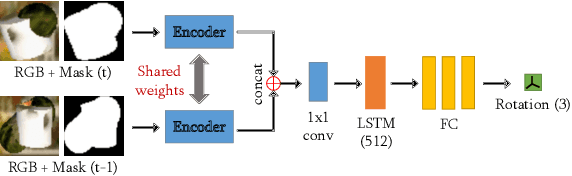

In this work, we bridge the gap between recent pose estimation and tracking work to develop a powerful method for robots to track objects in their surroundings. Motion-Nets use a segmentation model to segment the scene, and separate translation and rotation models to identify the relative 6D motion of an object between two consecutive frames. We train our method with generated data of floating objects, and then test on several prediction tasks, including one with a real PR2 robot, and a toy control task with a simulated PR2 robot never seen during training. Motion-Nets are able to track the pose of objects with some quantitative accuracy for about 30-60 frames including occlusions and distractors. Additionally, the single step prediction errors remain low even after 100 frames. We also investigate an iterative correction procedure to improve performance for control tasks.
SE3-Pose-Nets: Structured Deep Dynamics Models for Visuomotor Planning and Control
Oct 02, 2017



In this work, we present an approach to deep visuomotor control using structured deep dynamics models. Our deep dynamics model, a variant of SE3-Nets, learns a low-dimensional pose embedding for visuomotor control via an encoder-decoder structure. Unlike prior work, our dynamics model is structured: given an input scene, our network explicitly learns to segment salient parts and predict their pose-embedding along with their motion modeled as a change in the pose space due to the applied actions. We train our model using a pair of point clouds separated by an action and show that given supervision only in the form of point-wise data associations between the frames our network is able to learn a meaningful segmentation of the scene along with consistent poses. We further show that our model can be used for closed-loop control directly in the learned low-dimensional pose space, where the actions are computed by minimizing error in the pose space using gradient-based methods, similar to traditional model-based control. We present results on controlling a Baxter robot from raw depth data in simulation and in the real world and compare against two baseline deep networks. Our method runs in real-time, achieves good prediction of scene dynamics and outperforms the baseline methods on multiple control runs. Video results can be found at: https://rse-lab.cs.washington.edu/se3-structured-deep-ctrl/