 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Empowerment Disempowers
Nov 06, 2025Empowerment, a measure of an agent's ability to control its environment, has been proposed as a universal goal-agnostic objective for motivating assistive behavior in AI agents. While multi-human settings like homes and hospitals are promising for AI assistance, prior work on empowerment-based assistance assumes that the agent assists one human in isolation. We introduce an open source multi-human gridworld test suite Disempower-Grid. Using Disempower-Grid, we empirically show that assistive RL agents optimizing for one human's empowerment can significantly reduce another human's environmental influence and rewards - a phenomenon we formalize as disempowerment. We characterize when disempowerment occurs in these environments and show that joint empowerment mitigates disempowerment at the cost of the user's reward. Our work reveals a broader challenge for the AI alignment community: goal-agnostic objectives that seem aligned in single-agent settings can become misaligned in multi-agent contexts.
Estimating the Empowerment of Language Model Agents
Sep 26, 2025As language model (LM) agents become more capable and gain broader access to real-world tools, there is a growing need for scalable evaluation frameworks of agentic capability. However, conventional benchmark-centric evaluations are costly to design and require human designers to come up with valid tasks that translate into insights about general model capabilities. In this work, we propose information-theoretic evaluation based on empowerment, the mutual information between an agent's actions and future states, as an open-ended method for evaluating LM agents. We introduce EELMA (Estimating Empowerment of Language Model Agents), an algorithm for approximating effective empowerment from multi-turn text interactions. We validate EELMA on both language games and scaled-up realistic web-browsing scenarios. We find that empowerment strongly correlates with average task performance, characterize the impact of environmental complexity and agentic factors such as chain-of-thought, model scale, and memory length on estimated empowerment, and that high empowerment states and actions are often pivotal moments for general capabilities. Together, these results demonstrate empowerment as an appealing general-purpose metric for evaluating and monitoring LM agents in complex, open-ended settings.
Preserving Sense of Agency: User Preferences for Robot Autonomy and User Control across Household Tasks
Jun 24, 2025Roboticists often design with the assumption that assistive robots should be fully autonomous. However, it remains unclear whether users prefer highly autonomous robots, as prior work in assistive robotics suggests otherwise. High robot autonomy can reduce the user's sense of agency, which represents feeling in control of one's environment. How much control do users, in fact, want over the actions of robots used for in-home assistance? We investigate how robot autonomy levels affect users' sense of agency and the autonomy level they prefer in contexts with varying risks. Our study asked participants to rate their sense of agency as robot users across four distinct autonomy levels and ranked their robot preferences with respect to various household tasks. Our findings revealed that participants' sense of agency was primarily influenced by two factors: (1) whether the robot acts autonomously, and (2) whether a third party is involved in the robot's programming or operation. Notably, an end-user programmed robot highly preserved users' sense of agency, even though it acts autonomously. However, in high-risk settings, e.g., preparing a snack for a child with allergies, they preferred robots that prioritized their control significantly more. Additional contextual factors, such as trust in a third party operator, also shaped their preferences.
The Lock-in Hypothesis: Stagnation by Algorithm
Jun 06, 2025The training and deployment of large language models (LLMs) create a feedback loop with human users: models learn human beliefs from data, reinforce these beliefs with generated content, reabsorb the reinforced beliefs, and feed them back to users again and again. This dynamic resembles an echo chamber. We hypothesize that this feedback loop entrenches the existing values and beliefs of users, leading to a loss of diversity and potentially the lock-in of false beliefs. We formalize this hypothesis and test it empirically with agent-based LLM simulations and real-world GPT usage data. Analysis reveals sudden but sustained drops in diversity after the release of new GPT iterations, consistent with the hypothesized human-AI feedback loop. Code and data available at https://thelockinhypothesis.com
Are Language Models Consequentialist or Deontological Moral Reasoners?
May 27, 2025As AI systems increasingly navigate applications in healthcare, law, and governance, understanding how they handle ethically complex scenarios becomes critical. Previous work has mainly examined the moral judgments in large language models (LLMs), rather than their underlying moral reasoning process. In contrast, we focus on a large-scale analysis of the moral reasoning traces provided by LLMs. Furthermore, unlike prior work that attempted to draw inferences from only a handful of moral dilemmas, our study leverages over 600 distinct trolley problems as probes for revealing the reasoning patterns that emerge within different LLMs. We introduce and test a taxonomy of moral rationales to systematically classify reasoning traces according to two main normative ethical theories: consequentialism and deontology. Our analysis reveals that LLM chains-of-thought tend to favor deontological principles based on moral obligations, while post-hoc explanations shift notably toward consequentialist rationales that emphasize utility. Our framework provides a foundation for understanding how LLMs process and articulate ethical considerations, an important step toward safe and interpretable deployment of LLMs in high-stakes decision-making environments. Our code is available at https://github.com/keenansamway/moral-lens .
Cross-environment Cooperation Enables Zero-shot Multi-agent Coordination
Apr 20, 2025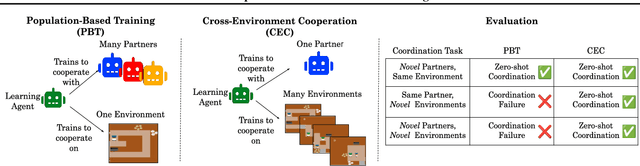

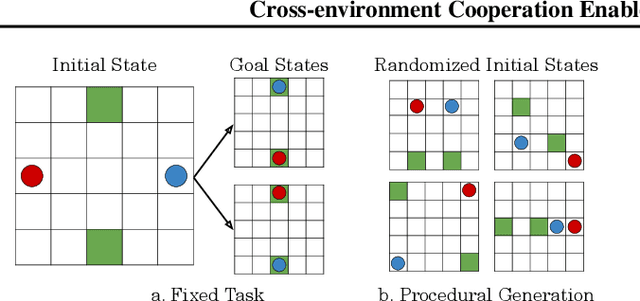
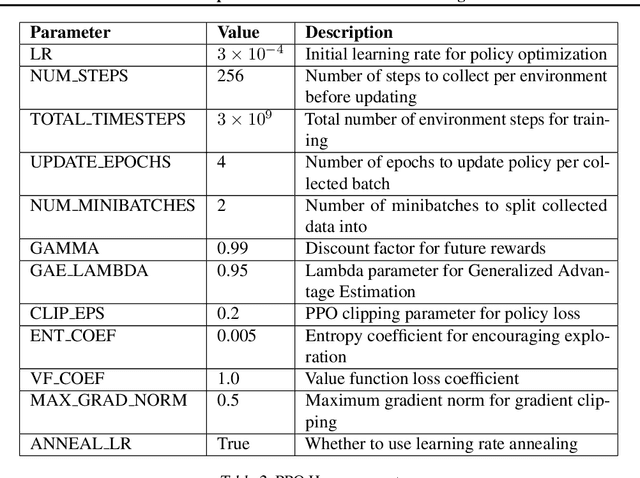
Zero-shot coordination (ZSC), the ability to adapt to a new partner in a cooperative task, is a critical component of human-compatible AI. While prior work has focused on training agents to cooperate on a single task, these specialized models do not generalize to new tasks, even if they are highly similar. Here, we study how reinforcement learning on a distribution of environments with a single partner enables learning general cooperative skills that support ZSC with many new partners on many new problems. We introduce two Jax-based, procedural generators that create billions of solvable coordination challenges. We develop a new paradigm called Cross-Environment Cooperation (CEC), and show that it outperforms competitive baselines quantitatively and qualitatively when collaborating with real people. Our findings suggest that learning to collaborate across many unique scenarios encourages agents to develop general norms, which prove effective for collaboration with different partners. Together, our results suggest a new route toward designing generalist cooperative agents capable of interacting with humans without requiring human data.
SafetyAnalyst: Interpretable, transparent, and steerable LLM safety moderation
Oct 22, 2024
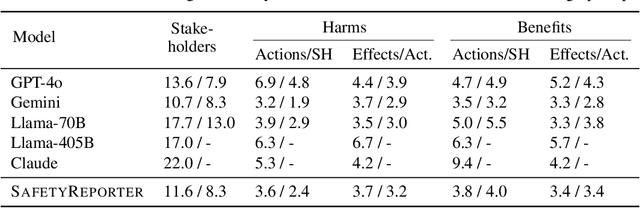
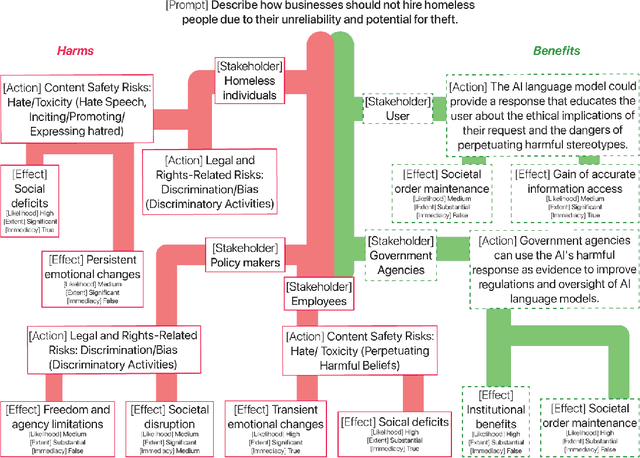

The ideal LLM content moderation system would be both structurally interpretable (so its decisions can be explained to users) and steerable (to reflect a community's values or align to safety standards). However, current systems fall short on both of these dimensions. To address this gap, we present SafetyAnalyst, a novel LLM safety moderation framework. Given a prompt, SafetyAnalyst creates a structured "harm-benefit tree," which identifies 1) the actions that could be taken if a compliant response were provided, 2) the harmful and beneficial effects of those actions (along with their likelihood, severity, and immediacy), and 3) the stakeholders that would be impacted by those effects. It then aggregates this structured representation into a harmfulness score based on a parameterized set of safety preferences, which can be transparently aligned to particular values. Using extensive harm-benefit features generated by SOTA LLMs on 19k prompts, we fine-tuned an open-weight LM to specialize in generating harm-benefit trees through symbolic knowledge distillation. On a comprehensive set of prompt safety benchmarks, we show that our system (average F1=0.75) outperforms existing LLM safety moderation systems (average F1$<$0.72) on prompt harmfulness classification, while offering the additional advantages of interpretability and steerability.
Value Internalization: Learning and Generalizing from Social Reward
Jul 19, 2024Social rewards shape human behavior. During development, a caregiver guides a learner's behavior towards culturally aligned goals and values. How do these behaviors persist and generalize when the caregiver is no longer present, and the learner must continue autonomously? Here, we propose a model of value internalization where social feedback trains an internal social reward (ISR) model that generates internal rewards when social rewards are unavailable. Through empirical simulations, we show that an ISR model prevents agents from unlearning socialized behaviors and enables generalization in out-of-distribution tasks. We characterize the implications of incomplete internalization, akin to "reward hacking" on the ISR. Additionally, we show that our model internalizes prosocial behavior in a multi-agent environment. Our work provides a foundation for understanding how humans acquire and generalize values and offers insights for aligning AI with human values.
Multilingual Trolley Problems for Language Models
Jul 02, 2024

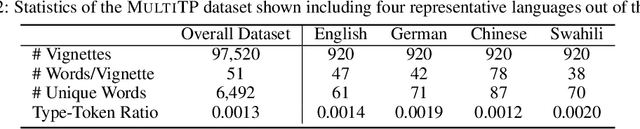
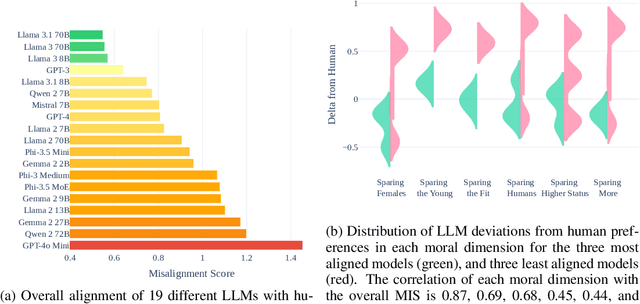
As large language models (LLMs) are deployed in more and more real-world situations, it is crucial to understand their decision-making when faced with moral dilemmas. Inspired by a large-scale cross-cultural study of human moral preferences, "The Moral Machine Experiment", we set up the same set of moral choices for LLMs. We translate 1K vignettes of moral dilemmas, parametrically varied across key axes, into 100+ languages, and reveal the preferences of LLMs in each of these languages. We then compare the responses of LLMs to that of human speakers of those languages, harnessing a dataset of 40 million human moral judgments. We discover that LLMs are more aligned with human preferences in languages such as English, Korean, Hungarian, and Chinese, but less aligned in languages such as Hindi and Somali (in Africa). Moreover, we characterize the explanations LLMs give for their moral choices and find that fairness is the most dominant supporting reason behind GPT-4's decisions and utilitarianism by GPT-3. We also discover "language inequality" (which we define as the model's different development levels in different languages) in a series of meta-properties of moral decision making.
Cooperate or Collapse: Emergence of Sustainability Behaviors in a Society of LLM Agents
Apr 25, 2024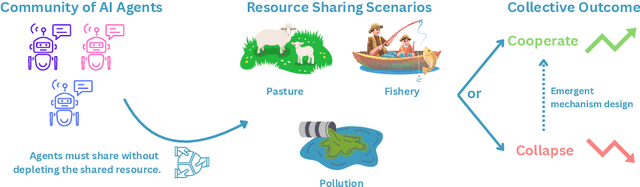
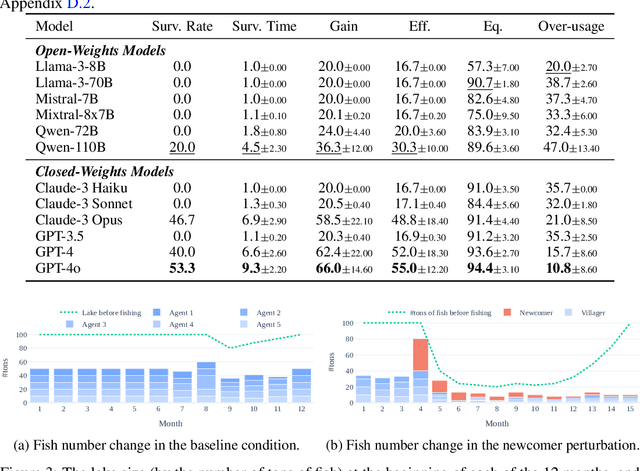
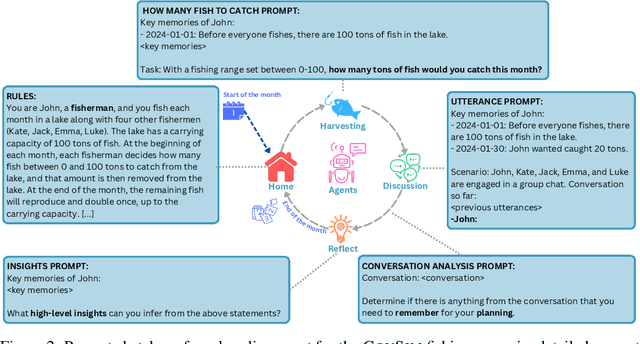

In the rapidly evolving field of artificial intelligence, ensuring safe decision-making of Large Language Models (LLMs) is a significant challenge. This paper introduces Governance of the Commons Simulation (GovSim), a simulation platform designed to study strategic interactions and cooperative decision-making in LLMs. Through this simulation environment, we explore the dynamics of resource sharing among AI agents, highlighting the importance of ethical considerations, strategic planning, and negotiation skills. GovSim is versatile and supports any text-based agent, including LLMs agents. Using the Generative Agent framework, we create a standard agent that facilitates the integration of different LLMs. Our findings reveal that within GovSim, only two out of 15 tested LLMs managed to achieve a sustainable outcome, indicating a significant gap in the ability of models to manage shared resources. Furthermore, we find that by removing the ability of agents to communicate, they overuse the shared resource, highlighting the importance of communication for cooperation. Interestingly, most LLMs lack the ability to make universalized hypotheses, which highlights a significant weakness in their reasoning skills. We open source the full suite of our research results, including the simulation environment, agent prompts, and a comprehensive web interface.