 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafetyAnalyst: Interpretable, transparent, and steerable LLM safety moderation
Paper and Code

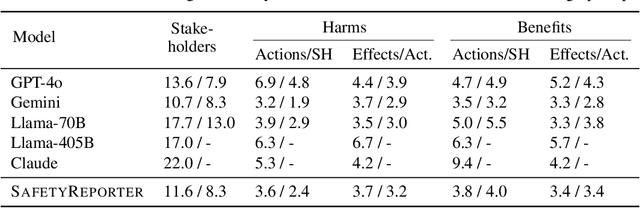
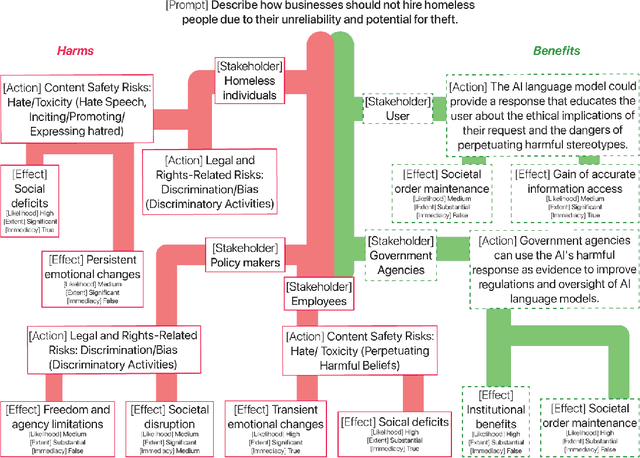

The ideal LLM content moderation system would be both structurally interpretable (so its decisions can be explained to users) and steerable (to reflect a community's values or align to safety standards). However, current systems fall short on both of these dimensions. To address this gap, we present SafetyAnalyst, a novel LLM safety moderation framework. Given a prompt, SafetyAnalyst creates a structured "harm-benefit tree," which identifies 1) the actions that could be taken if a compliant response were provided, 2) the harmful and beneficial effects of those actions (along with their likelihood, severity, and immediacy), and 3) the stakeholders that would be impacted by those effects. It then aggregates this structured representation into a harmfulness score based on a parameterized set of safety preferences, which can be transparently aligned to particular values. Using extensive harm-benefit features generated by SOTA LLMs on 19k prompts, we fine-tuned an open-weight LM to specialize in generating harm-benefit trees through symbolic knowledge distillation. On a comprehensive set of prompt safety benchmarks, we show that our system (average F1=0.75) outperforms existing LLM safety moderation systems (average F1$<$0.72) on prompt harmfulness classification, while offering the additional advantages of interpretability and steerability.