 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePluralistic Behavior Suite: Stress-Testing Multi-Turn Adherence to Custom Behavioral Policies
Nov 07, 2025Large language models (LLMs) are typically aligned to a universal set of safety and usage principles intended for broad public acceptability. Yet, real-world applications of LLMs often take place within organizational ecosystems shaped by distinctive corporate policies, regulatory requirements, use cases, brand guidelines, and ethical commitments. This reality highlights the need for rigorous and comprehensive evaluation of LLMs with pluralistic alignment goals, an alignment paradigm that emphasizes adaptability to diverse user values and needs. In this work, we present PLURALISTIC BEHAVIOR SUITE (PBSUITE), a dynamic evaluation suite designed to systematically assess LLMs' capacity to adhere to pluralistic alignment specifications in multi-turn, interactive conversations. PBSUITE consists of (1) a diverse dataset of 300 realistic LLM behavioral policies, grounded in 30 industries; and (2) a dynamic evaluation framework for stress-testing model compliance with custom behavioral specifications under adversarial conditions. Using PBSUITE, We find that leading open- and closed-source LLMs maintain robust adherence to behavioral policies in single-turn settings (less than 4% failure rates), but their compliance weakens substantially in multi-turn adversarial interactions (up to 84% failure rates). These findings highlight that existing model alignment and safety moderation methods fall short in coherently enforcing pluralistic behavioral policies in real-world LLM interactions. Our work contributes both the dataset and analytical framework to support future research toward robust and context-aware pluralistic alignment techniques.
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025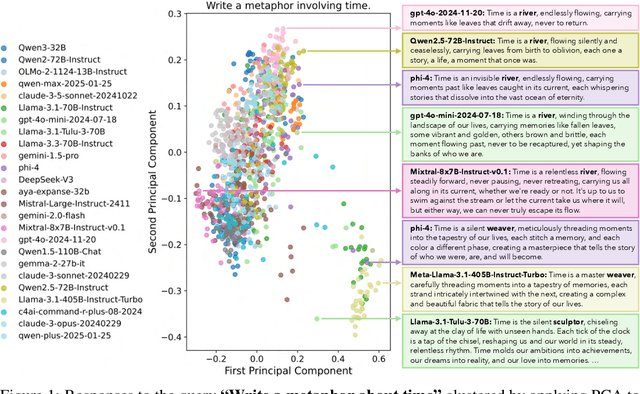
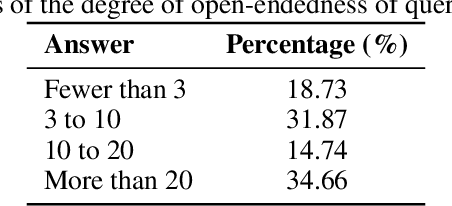
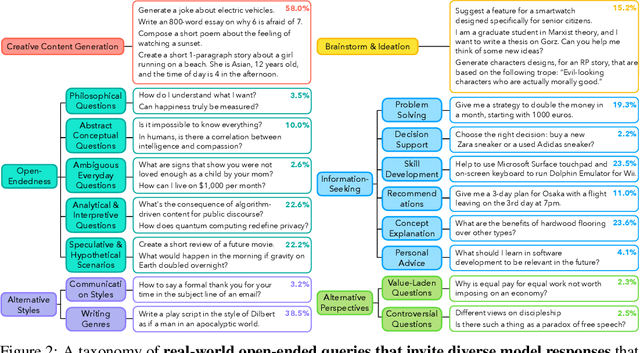

Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
Chasing Moving Targets with Online Self-Play Reinforcement Learning for Safer Language Models
Jun 09, 2025Conventional language model (LM) safety alignment relies on a reactive, disjoint procedure: attackers exploit a static model, followed by defensive fine-tuning to patch exposed vulnerabilities. This sequential approach creates a mismatch -- attackers overfit to obsolete defenses, while defenders perpetually lag behind emerging threats. To address this, we propose Self-RedTeam, an online self-play reinforcement learning algorithm where an attacker and defender agent co-evolve through continuous interaction. We cast safety alignment as a two-player zero-sum game, where a single model alternates between attacker and defender roles -- generating adversarial prompts and safeguarding against them -- while a reward LM adjudicates outcomes. This enables dynamic co-adaptation. Grounded in the game-theoretic framework of zero-sum games, we establish a theoretical safety guarantee which motivates the design of our method: if self-play converges to a Nash Equilibrium, the defender will reliably produce safe responses to any adversarial input. Empirically, Self-RedTeam uncovers more diverse attacks (+21.8% SBERT) compared to attackers trained against static defenders and achieves higher robustness on safety benchmarks (e.g., +65.5% on WildJailBreak) than defenders trained against static attackers. We further propose hidden Chain-of-Thought, allowing agents to plan privately, which boosts adversarial diversity and reduces over-refusals. Our results motivate a shift from reactive patching to proactive co-evolution in LM safety training, enabling scalable, autonomous, and robust self-improvement of LMs via multi-agent reinforcement learning (MARL).
X-Teaming: Multi-Turn Jailbreaks and Defenses with Adaptive Multi-Agents
Apr 15, 2025Multi-turn interactions with language models (LMs) pose critical safety risks, as harmful intent can be strategically spread across exchanges. Yet, the vast majority of prior work has focused on single-turn safety, while adaptability and diversity remain among the key challenges of multi-turn red-teaming. To address these challenges, we present X-Teaming, a scalable framework that systematically explores how seemingly harmless interactions escalate into harmful outcomes and generates corresponding attack scenarios. X-Teaming employs collaborative agents for planning, attack optimization, and verification, achieving state-of-the-art multi-turn jailbreak effectiveness and diversity with success rates up to 98.1% across representative leading open-weight and closed-source models. In particular, X-Teaming achieves a 96.2% attack success rate against the latest Claude 3.7 Sonnet model, which has been considered nearly immune to single-turn attacks. Building on X-Teaming, we introduce XGuard-Train, an open-source multi-turn safety training dataset that is 20x larger than the previous best resource, comprising 30K interactive jailbreaks, designed to enable robust multi-turn safety alignment for LMs. Our work offers essential tools and insights for mitigating sophisticated conversational attacks, advancing the multi-turn safety of LMs.
PolyGuard: A Multilingual Safety Moderation Tool for 17 Languages
Apr 06, 2025Truly multilingual safety moderation efforts for Large Language Models (LLMs) have been hindered by a narrow focus on a small set of languages (e.g., English, Chinese) as well as a limited scope of safety definition, resulting in significant gaps in moderation capabilities. To bridge these gaps, we release POLYGUARD, a new state-of-the-art multilingual safety model for safeguarding LLM generations, and the corresponding training and evaluation datasets. POLYGUARD is trained on POLYGUARDMIX, the largest multilingual safety training corpus to date containing 1.91M samples across 17 languages (e.g., Chinese, Czech, English, Hindi). We also introduce POLYGUARDPROMPTS, a high quality multilingual benchmark with 29K samples for the evaluation of safety guardrails. Created by combining naturally occurring multilingual human-LLM interactions and human-verified machine translations of an English-only safety dataset (WildGuardMix; Han et al., 2024), our datasets contain prompt-output pairs with labels of prompt harmfulness, response harmfulness, and response refusal. Through extensive evaluations across multiple safety and toxicity benchmarks, we demonstrate that POLYGUARD outperforms existing state-of-the-art open-weight and commercial safety classifiers by 5.5%. Our contributions advance efforts toward safer multilingual LLMs for all global users.
Online Covariance Estimation in Nonsmooth Stochastic Approximation
Feb 07, 2025
We consider applying stochastic approximation (SA) methods to solve nonsmooth variational inclusion problems. Existing studies have shown that the averaged iterates of SA methods exhibit asymptotic normality, with an optimal limiting covariance matrix in the local minimax sense of H\'ajek and Le Cam. However, no methods have been proposed to estimate this covariance matrix in a nonsmooth and potentially non-monotone (nonconvex) setting. In this paper, we study an online batch-means covariance matrix estimator introduced in Zhu et al.(2023). The estimator groups the SA iterates appropriately and computes the sample covariance among batches as an estimate of the limiting covariance. Its construction does not require prior knowledge of the total sample size, and updates can be performed recursively as new data arrives. We establish that, as long as the batch size sequence is properly specified (depending on the stepsize sequence), the estimator achieves a convergence rate of order $O(\sqrt{d}n^{-1/8+\varepsilon})$ for any $\varepsilon>0$, where $d$ and $n$ denote the problem dimensionality and the number of iterations (or samples) used. Although the problem is nonsmooth and potentially non-monotone (nonconvex), our convergence rate matches the best-known rate for covariance estimation methods using only first-order information in smooth and strongly-convex settings. The consistency of this covariance estimator enables asymptotically valid statistical inference, including constructing confidence intervals and performing hypothesis testing.
SafetyAnalyst: Interpretable, transparent, and steerable LLM safety moderation
Oct 22, 2024
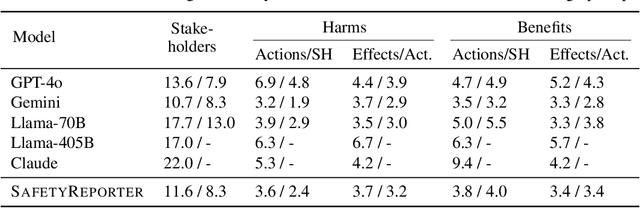
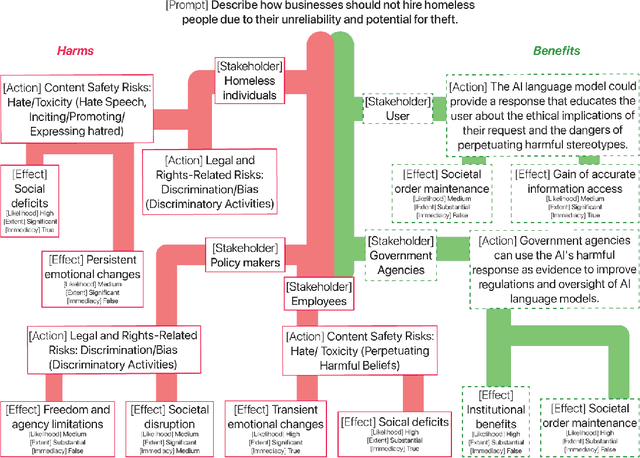

The ideal LLM content moderation system would be both structurally interpretable (so its decisions can be explained to users) and steerable (to reflect a community's values or align to safety standards). However, current systems fall short on both of these dimensions. To address this gap, we present SafetyAnalyst, a novel LLM safety moderation framework. Given a prompt, SafetyAnalyst creates a structured "harm-benefit tree," which identifies 1) the actions that could be taken if a compliant response were provided, 2) the harmful and beneficial effects of those actions (along with their likelihood, severity, and immediacy), and 3) the stakeholders that would be impacted by those effects. It then aggregates this structured representation into a harmfulness score based on a parameterized set of safety preferences, which can be transparently aligned to particular values. Using extensive harm-benefit features generated by SOTA LLMs on 19k prompts, we fine-tuned an open-weight LM to specialize in generating harm-benefit trees through symbolic knowledge distillation. On a comprehensive set of prompt safety benchmarks, we show that our system (average F1=0.75) outperforms existing LLM safety moderation systems (average F1$<$0.72) on prompt harmfulness classification, while offering the additional advantages of interpretability and steerability.
To Err is AI : A Case Study Informing LLM Flaw Reporting Practices
Oct 15, 2024



In August of 2024, 495 hackers generated evaluations in an open-ended bug bounty targeting the Open Language Model (OLMo) from The Allen Institute for AI. A vendor panel staffed by representatives of OLMo's safety program adjudicated changes to OLMo's documentation and awarded cash bounties to participants who successfully demonstrated a need for public disclosure clarifying the intent, capacities, and hazards of model deployment. This paper presents a collection of lessons learned, illustrative of flaw reporting best practices intended to reduce the likelihood of incidents and produce safer large language models (LLMs). These include best practices for safety reporting processes, their artifacts, and safety program staffing.
AI as Humanity's Salieri: Quantifying Linguistic Creativity of Language Models via Systematic Attribution of Machine Text against Web Text
Oct 05, 2024Creativity has long been considered one of the most difficult aspect of human intelligence for AI to mimic. However, the rise of Large Language Models (LLMs), like ChatGPT, has raised questions about whether AI can match or even surpass human creativity. We present CREATIVITY INDEX as the first step to quantify the linguistic creativity of a text by reconstructing it from existing text snippets on the web. CREATIVITY INDEX is motivated by the hypothesis that the seemingly remarkable creativity of LLMs may be attributable in large part to the creativity of human-written texts on the web. To compute CREATIVITY INDEX efficiently, we introduce DJ SEARCH, a novel dynamic programming algorithm that can search verbatim and near-verbatim matches of text snippets from a given document against the web. Experiments reveal that the CREATIVITY INDEX of professional human authors is on average 66.2% higher than that of LLMs, and that alignment reduces the CREATIVITY INDEX of LLMs by an average of 30.1%. In addition, we find that distinguished authors like Hemingway exhibit measurably higher CREATIVITY INDEX compared to other human writers. Finally, we demonstrate that CREATIVITY INDEX can be used as a surprisingly effective criterion for zero-shot machine text detection, surpassing the strongest existing zero-shot system, DetectGPT, by a significant margin of 30.2%, and even outperforming the strongest supervised system, GhostBuster, in five out of six domains.
Can Language Models Reason about Individualistic Human Values and Preferences?
Oct 04, 2024Recent calls for pluralistic alignment emphasize that AI systems should address the diverse needs of all people. Yet, efforts in this space often require sorting people into fixed buckets of pre-specified diversity-defining dimensions (e.g., demographics, personalities, communication styles), risking smoothing out or even stereotyping the rich spectrum of individualistic variations. To achieve an authentic representation of diversity that respects individuality, we propose individualistic alignment. While individualistic alignment can take various forms, in this paper, we introduce IndieValueCatalog, a dataset transformed from the influential World Values Survey (WVS), to study language models (LMs) on the specific challenge of individualistic value reasoning. Specifically, given a sample of an individual's value-expressing statements, models are tasked with predicting their value judgments in novel cases. With IndieValueCatalog, we reveal critical limitations in frontier LMs' abilities to reason about individualistic human values with accuracies, only ranging between 55% to 65%. Moreover, our results highlight that a precise description of individualistic values cannot be approximated only via demographic information. We also identify a partiality of LMs in reasoning about global individualistic values, as measured by our proposed Value Inequity Index ({\sigma}INEQUITY). Finally, we train a series of Individualistic Value Reasoners (IndieValueReasoner) using IndieValueCatalog to enhance models' individualistic value reasoning capability, revealing new patterns and dynamics into global human values. We outline future research challenges and opportunities for advancing individualistic alignment.