 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyGuard: A Multilingual Safety Moderation Tool for 17 Languages
Apr 06, 2025Truly multilingual safety moderation efforts for Large Language Models (LLMs) have been hindered by a narrow focus on a small set of languages (e.g., English, Chinese) as well as a limited scope of safety definition, resulting in significant gaps in moderation capabilities. To bridge these gaps, we release POLYGUARD, a new state-of-the-art multilingual safety model for safeguarding LLM generations, and the corresponding training and evaluation datasets. POLYGUARD is trained on POLYGUARDMIX, the largest multilingual safety training corpus to date containing 1.91M samples across 17 languages (e.g., Chinese, Czech, English, Hindi). We also introduce POLYGUARDPROMPTS, a high quality multilingual benchmark with 29K samples for the evaluation of safety guardrails. Created by combining naturally occurring multilingual human-LLM interactions and human-verified machine translations of an English-only safety dataset (WildGuardMix; Han et al., 2024), our datasets contain prompt-output pairs with labels of prompt harmfulness, response harmfulness, and response refusal. Through extensive evaluations across multiple safety and toxicity benchmarks, we demonstrate that POLYGUARD outperforms existing state-of-the-art open-weight and commercial safety classifiers by 5.5%. Our contributions advance efforts toward safer multilingual LLMs for all global users.
PolygloToxicityPrompts: Multilingual Evaluation of Neural Toxic Degeneration in Large Language Models
May 15, 2024Recent advances in large language models (LLMs) have led to their extensive global deployment, and ensuring their safety calls for comprehensive and multilingual toxicity evaluations. However, existing toxicity benchmarks are overwhelmingly focused on English, posing serious risks to deploying LLMs in other languages. We address this by introducing PolygloToxicityPrompts (PTP), the first large-scale multilingual toxicity evaluation benchmark of 425K naturally occurring prompts spanning 17 languages. We overcome the scarcity of naturally occurring toxicity in web-text and ensure coverage across languages with varying resources by automatically scraping over 100M web-text documents. Using PTP, we investigate research questions to study the impact of model size, prompt language, and instruction and preference-tuning methods on toxicity by benchmarking over 60 LLMs. Notably, we find that toxicity increases as language resources decrease or model size increases. Although instruction- and preference-tuning reduce toxicity, the choice of preference-tuning method does not have any significant impact. Our findings shed light on crucial shortcomings of LLM safeguarding and highlight areas for future research.
SciDr at SDU-2020: IDEAS -- Identifying and Disambiguating Everyday Acronyms for Scientific Domain
Mar 08, 2021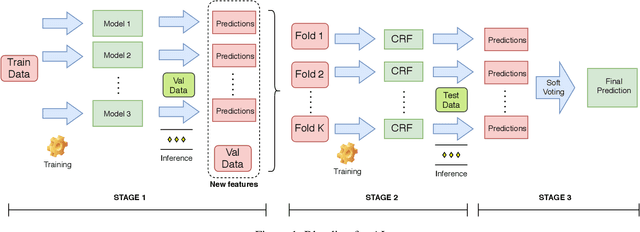
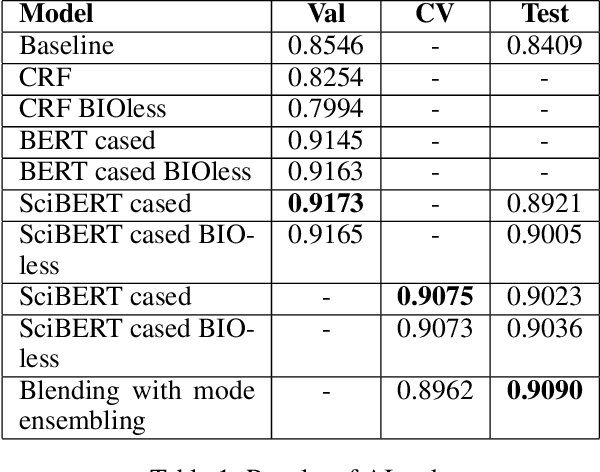
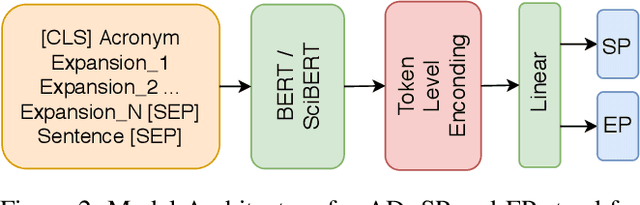
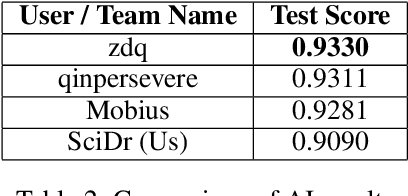
We present our systems submitted for the shared tasks of Acronym Identification (AI) and Acronym Disambiguation (AD) held under Workshop on SDU. We mainly experiment with BERT and SciBERT. In addition, we assess the effectiveness of "BIOless" tagging and blending along with the prowess of ensembling in AI. For AD, we formulate the problem as a span prediction task, experiment with different training techniques and also leverage the use of external data. Our systems rank 11th and 3rd in AI and AD tasks respectively.
NutCracker at WNUT-2020 Task 2: Robustly Identifying Informative COVID-19 Tweets using Ensembling and Adversarial Training
Oct 09, 2020

We experiment with COVID-Twitter-BERT and RoBERTa models to identify informative COVID-19 tweets. We further experiment with adversarial training to make our models robust. The ensemble of COVID-Twitter-BERT and RoBERTa obtains a F1-score of 0.9096 (on the positive class) on the test data of WNUT-2020 Task 2 and ranks 1st on the leaderboard. The ensemble of the models trained using adversarial training also produces similar result.
DSC IIT-ISM at SemEval-2020 Task 6: Boosting BERT with Dependencies for Definition Extraction
Sep 17, 2020


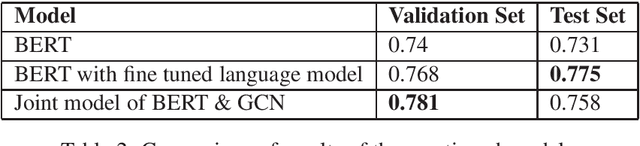
We explore the performance of Bidirectional Encoder Representations from Transformers (BERT) at definition extraction. We further propose a joint model of BERT and Text Level Graph Convolutional Network so as to incorporate dependencies into the model. Our proposed model produces better results than BERT and achieves comparable results to BERT with fine tuned language model in DeftEval (Task 6 of SemEval 2020), a shared task of classifying whether a sentence contains a definition or not (Subtask 1).